

Preface:
It has been often believed that IBIS-AMI modeling imposes a comparably high cost and technical barriers to get started. An AMI modeling engineer certainly has the due diligence to be familiar and understand the basic of link analysis or AMI flow. However, the requirements of implementing the models in C/C++ codes, compiling them into .dll/.so libraries, and being able to run on third party (often expensive) EDA tools with consistent results are often too much to ask for… or at least will increase the design cycle. To meet these challenges, several big EDA companies have provided top-down based flow for AMI generation directly from architecture codes. In exchange with the “click-button” convenience, SERDES needs to be designed in its environment first and tool’s up-front expense also needs to be considered. Further more, the long term cost of the generated AMI models (in terms of model support, maintenance and extensibility) are often ignored. It’s also true that even with these top-down flows, compilation on different platforms (win32, win64, linux) etc are still inevitable.
We published several free tools recently and presented a paper at the recent IBIS summit regarding AMI modeling. Together with other open source/free link analysis tool to be mentioned at the end of this post, we think it’s now a good time to consider an alternative AMI modeling flow. This proposed methodology in this post will be economic (no front end tools cost) and efficient (give SERDES/AMI developer most control).
[Note that in this post, we use link tool/simulator alternatively to represent the application loading IBIS-AMI models and calling their functions.]
Concepts:
Engineers familiar with Spice-like simulator know that we usually only need one platform specific simulator (binary). Schematics netlist is in plain text format and can be used cross different platforms (assuming good practice such as relative modeling path, file line endings are followed). A general purpose spice simulator is not design specific so there is no need to have different simulators for different circuit or IC design. This compatibility is achieved by building on simple rules, i,e KCL and KVL and linear algebra. This way a simulator can decoupled from the implementation details of design specifics.
In the “AMI-modeling” world, are there such simple rules to be found so that we don’t need to compile a binary just because the design is different? Understood that there are always trade-offs: e.g. simulation speed of design specific binary model vs slower yet convenience during modeling cycle, then at least we should find a way so that modeling engineers can focus more on the basic of the algorithmic blocks and hopefully, still find a way in a later stage to generate a speedy model with minimum extra tasks (C/C++,dll etc)
AMI model, at its current scopes, is mainly for SERDES application. They are mostly point-to-point system or can be processed stage by stage. We may also think it this way by looking at the defined AMI-API function prototypes:

AMI_Init and AMI_GetWave are two main processing routines defined in the API spec. Various arguments are passed-in and the AMI models are responsible to perform designed algorithmic within the model then return these values in place. By “in place”, we mean the impulse_matrix’s and wave’s content will be modified in the same memory address before returning back to the calling application… which is mostly simulation platform or circuit simulator.

Based on these observations, we can liberate the couplings between 1) link tool and models, and 2) models and underline algorithmic processing. Via these decoupling, an economic yet efficient flow can be made possible.
Decoupling within the model:
First, we want to observe how data are being passed from the link tool to the model. In the schematic above, the input to the Tx stage is either channel’s response (LTI mode) or bit pattern (NLTV). If the Tx is a simple pass through, then Rx will receive similar information without being affected by Tx:

Take AMI_Init as an example, we can achieve this decoupling using SPISim’s free SPISimProxy model. SPISimProxy will write the argument received from the link tool to a plain text file. After the AMI model’s processing, it will again write out the processed data to another text file before finally giving back to the link tool. This way data being exchanged between link tool and the model are now exposed… even if they both are compiled binaries. The two blue boxes above represent such generated text data. The main function of the AMI_Int function, purple block in the middle and existed in the model’s .dll/.so file as a form of the C function, is to transform input to output response.
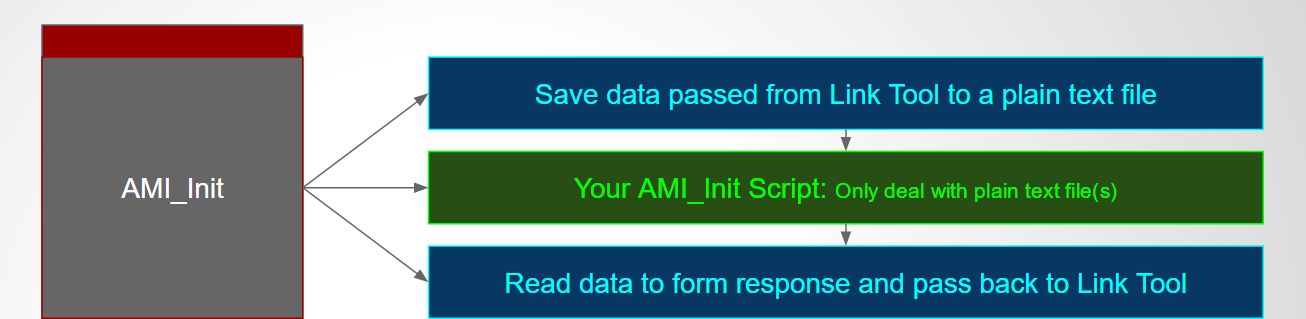
With this, we can now replace the AMI_Init function with our own… we can write this function in matlab, python, perl, java etc language instead of more demanding C/C++ form. It only needs to interface with two text files just exposed with the following operation sequence:
- SPISimProxy will expose the calling arguments into a text file, the top blue box
- User’s script will read the text file and perform necessary processing
- User’s script will write out the data in similar text format
- SPISimProxy will read the generated text data, form argument and pass back to simulator.
Because each of these steps can be customized by Proxy’s .ami settings, a configuration file or even environment variables, AMI developers are now liberated to use what ever languages they preferred without dealing any C/C++ if they like. There is also no need for .dll/.so compilation as SPISimProxy has been pre-compiled to support most of the platforms.
The example above uses AMI_Init as an example, other API calls, such as AMI_GetWave or AMI_Resolve can be done in similar fashion. Clean-up calls such as AMI_Close or AMI_Resolve_Close are also supported in SPISimProxy model so if needed, AMI modeler can also clean-up all these file traces at the end.
Part of the arguments passed from the simulator is the model pointer. This model pointer (void*) is supposed to be persistent during the AMI process. The script author may use file based persistence mechanism across AMI_Init/AMI_GetWave calls to store constructed data structure or settings etc. By avoiding using C/C++ specific pointers or data structures, the process becomes neutral and can support many different languages.
Decoupling with the EDA tool:
The aforementioned process requires an application to drive the proxy model, and thus the modeling scripts. This can be achieved with our free SPISimAMI.exe. It’s again pre-compiled to support most platforms. Its built-in pulse response enable user to model LTI based AMI process directly. For bit-by-bit based input data, user may use our SPILite or other free simulator such as our SSolver or NGSpice to generate bit sequence, then feed this input in .csv format to the application. SPISimAMI will then take this user’s input, form the proper arguments and send to underlying AMI models… it can be modeling script current under development, or an existing IBIS-AMI models for testing or validation purpose. SPISImAMI can also be used to drive an existing AMI models via SPISimProxy so that user may get insights about this process. In the demo video we posted on SPISimProxy page, a matlab script has been used to demonstrate the AMI_Init process.
Test drive with open-source link tool:
Once the given response work properly with the prototype implemented in modeling scripts, next step is to run them in a link tool for BER like analysis. For this purpose, pyBert may be used as it also load IBIS-AMI models, including our SPISimProxy.
Up to this point, there is no front-end cost involved in the AMI modeling process and a developer only needs to use his/her own favorite language to deal with plain-text input/output. In addition, the debugging and testing of the model prototype can be done with direct command call instead of multi-step GUI operation/invocation. This not only avoid license needed with 3rd party tool, but also ensures an efficient work flow with easily repeated consistent results.
Optimization and model release:
There are several possibilities to release the models from on this process:
- The model publisher may encrypt the script if needed, then distribute as they are. This will produce most accurate results as they have been validated by the author during the modeling process. The disadvantages include that: 1) it’s less efficient as the data exchanged between the SPISimProxy and the modeling scripts are file based, 2) the model recipient may need to install other run time interpreters such as perl, python etc in order to run the encrypt/compiled script, and 3) the client also needs to download the SPISimProxy from our site as unlicensed redistribution is strickly prohibited.
- We can work with the model publisher to provide specific API to the prototype model such that the IP and accuracy are still maintained, yet the performance will be improved dramatically. We can also remove the unlicensed terms and add the proxy class to have your company’s name so that you can distribute SPISimProxy together with your model.
- We can also create the corresponding AMI model with pure C/C++ codes to that there is only one model to be released with best performance and convenience for the clients.
The modeling flow suggested above is not proprietary and can also be implemented within the corporation or the modeling team. We believe that with the liberation of the modeling engineers from these unrelated AMI modeling process, they will be able to focus more on the core business logic, i.e. the algorithmic part and deliver the best quality model for the industry’s progress. Those non directly related tasks can be left for other EDA professionals (* cough *) if needed.