

In AMI modeling domain, several “black box” magics or techniques are very useful. They exist to make the modeling process more streamlined yet flexible. In this blog post, I will share some experiences and thoughts we have during the development of our SPISimAMI flow. Modeling examples from some major companies will also be reviewed
Why the black box magic?
In contrast to other system models such as T-Line’s RLGC data, S-parameters or even traditional IBIS model, the AMI model itself is a black box. AMI models are both platform and OS dependent. They are in compiled binary format in the form of shared library… “.dll” (dynamic linked library) on windows and .”so” (shared object) on linux-like system. The other part of the ami model, the .ami file, is indeed in plain text holding model settings. However, it needs to work closely with the associated .dll/.so AMI model and can’t be changed arbitrarily.
For a model developer, even if he/she has the skills of the C/C++ coding and .dll/.so compilation, the whole process is still very tedious and error prune. For example, the same compilation and testing need to be done twice on windows due to the 32/64 bit difference. It’s even worse on linux. Different machines or OS need to be tested separately because no only there are different linux “distros”, different environments or IT set-ups may also cause discrepancies. As an example, the usage of “boost” or some other libraries like GSL are very common and widely used in C++ engineering/scientific computing development. However, they may not be included in all IT-built, production oriented environment. As a result, AMI models running perfectly fine on the developer’s system may fail to load on others. To be on the safe side, one usually needs link these “non-essential” libraries statically into the .so file, strip symbols to reduce size, and then test on different machines (virtual or not) to be assure for maximum compatibility. These details may explain why AMI modeling charge has been very high in the past and somewhat monopolized by very few companies.
In previous posts, we mentioned the similarities we felt between a circuit simulator and an AMI model. While a purposely built circuit simulator (like those for cache or memory circuit etc) may run very fast and efficient, a general purpose (e.g. MNA based) simulator usually is suffice for most of the design work. In these simulators, primitive device model such R/L/C/V/I are built-in, even more complicated ones such as MOSFET, T-Line, IBIS are also included and configurable via external files (.snp file, .ibs file and .tab). This simulator, compiled to native format to maximize the performance, are also platform and OS dependent. However, they do not need to be design specific. Those configurable aspects are left in the netlist file…similar to the plain text .ami file. When more sensitive information needs to be provided to the simulator, such as the process file or design IP, they can be encrypted such as “encrypted hspice” does.
From this point of view, we can see that “magic” or modeling techniques can happen in both places… i.e. the .dll and .ami files
Black box magic in binary .dll/.so files:

While there are five AMI API functions defined in the spec., most important ones are AMI_Init and AMI_Getwave. From their signature shown above, we can see that the same pointer (impulse_matrix for AMI_Init and wave for AMI_GetWave) are used for both input and output. That is, the data are passed-in, the AMI functions need to calculate the response based on this black box’s behaviors, then fill the output response back in to the same pointer to return to the simulation platform on top. This can be depicted with a schematic to depict more or less like the one below:
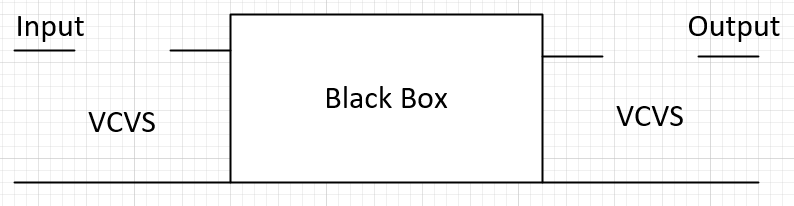
The assumptions implied implicitly in AMI channel simulation is that the input impedance to the AMI model (black box above, such as Rx model) are infinitely high, same for the output stage of a AMI Tx circuit. So we can imagine two voltage controlled voltage sources (VCVS) with gain = 1 are used at both input and output ends, with the AMI model sitting in the middle to transfer circuit block’s response between stages.
The content inside the “black box” are not visible to outsiders, so a model developer can write spaghetti C/C++ codes to mangle everything together and produce module used only once. Or he/she can does a better job by architecting it in a modular way like the one below:

If we image this with a spice netlist, it will be something like a .subckt: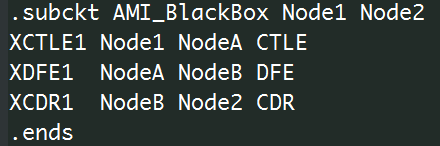
Parameters to different modules are apparent and omitted here. Construct an AMI model this way will enable module being reused more easily. With that said, the example above still has two assumptions: the first one is that only three stages (i.,e. CTLE, DFE, CDR) are used and their order are fixed. What if user want an AGC up front or LPF filter in between? Do we need to rewrite the codes and compile/test again? The second assumption is that these module are cascaded stage by stage (mostly true for SERDES design) and each block has only one input and output (not necessarily true even for SERDES), These two assumptions are not necessarily true for other design. So we believe that they do not need to be “hard coded” and compiled into the rigid AMI model.
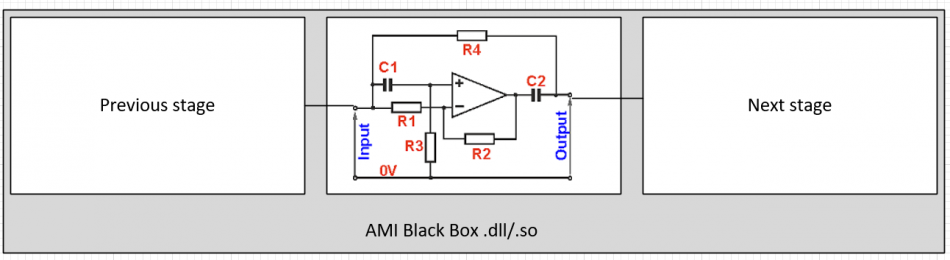
In normal modeling process, one usually need to translate a circuit or a module’s response into describable behavior before its C/C++ codes can be written. For example, if we know this is module is a LPF (low pass filter) then we only need to get its frequency response in order to do IFFT and perform convolution in time domain. However, some blocks may not have close form formula or an easily describable behavior. Is it possible to embed a “mini circuit simulator” in a block so that its input and output will be calculated automatically? This is certainly possible. In fact, one can even implement a S-parameter block or T-Line block to serve as analog front end of the AMI model (for example, to represent a package model). In SPISim’s case, because we have developed an in house circuit simulator and associated device model, we simply need to construct a time domain PWL source representing input “impulse_matrix” or “wave” data, then run mini circuit simulation and retrieve output from simulator’s API (or even waveform on disk) and give back to the channel simulator on top.
As one can see, there are a lot of techniques or magics can be applied to this .dll/.so black boxes. Because compiling platform/OS dependent binary are not a fun, it’s our belief and practice that we should compile a comprehensive AMI model and reuse it as much as we can. The configurable part should be put in the .ami file.
Black box magic in plain text .ami file:
An .ami file has settings for both channel simulator and more importantly, the .dll/.so models being called. It contains two parts:
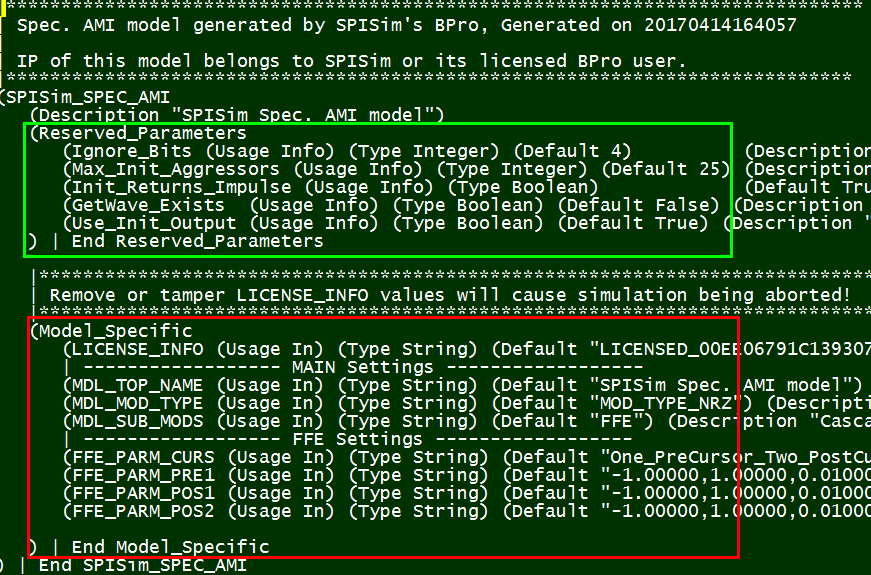
The “Reserved_parameters” (boxed in green) are for channel simulator to consume. The keywords used here are defined in the spec. and need to be used accordingly. All spec-compliant channel simulator needs to be able to process info. in this part (in reality, we do see individual companies defining their own keywords due to aforementioned monopoly situation).
The “Model_Specific” (boxed in red) portion, on the other hand, are only for model to consume. It’s not channel simulator’s business to judge and interfere how they should be defined and be used. As a result, we can perform many creative techniques here.
We proposed some of the techniques first late last year in previous posts. It’s to our pleasant surprise that other company, such as IBM/GlobalFoundaries also has similar thoughts. Please see their presentation at DesignCon this year linked below (Topic time is 10:15AM)
The AMI_Resolve: A Case Study for 56G PAM4 (http://ibis.org/summits/feb17/)
Simply speaking, one can embed lots of information in the .ami file to convey to the underneath .dll/.so models. Common encryption can be used to protect sensitive information. For example, the reason why SPISim can release our AMI models for free to generate and use is because our AMI .dll/.so files require a license setting and a time stamp and/or data dependent values are part of the license info. Thus, a model will expire after certain time, the parameters can be changed if locked, and the license info can’t be tampered.

The paper presented by IBM demonstrate the intercommunication between unresolved .ami file and the AMI_Resolve API function. The “netlist” or “equation” is encrypted and embedded as part of the .ami file. In the IBIS spec, a table format is also supported in the .ami model_specific syntax yet it may be a hassle to produce and use. In practice, we prefer to point to an external file directly like below:

This external file can also be encrypted up front and decrypted by the .dll/.so file on the fly. It can be a setting table, a frequency response, a S-parameter or a netlist to support the “mini-simulator” block within the AMI model. From this point of view, while the .ami file is plain text, it can still be like a black box and many aforementioned techniques to minimize the re-coding/re-compilation of the .dll/.so file can be used.
Real world examples & considerations:
While these “black box” magic are intriguing and wonderful, at the end of the day, we need to see how well they work in real world. Lets see two examples:
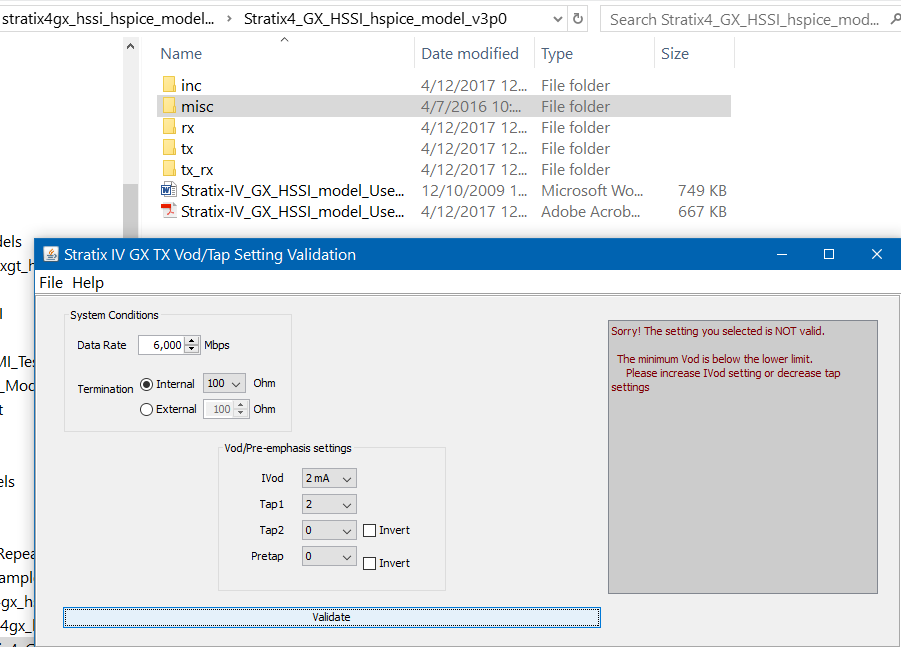
The first model is from Altera. Not only do they provide AMI models and documentation, they also provide a GUI tool to let user check what combination of parameter are valid. In this case, they only provide one .ami file with all possible values inside.
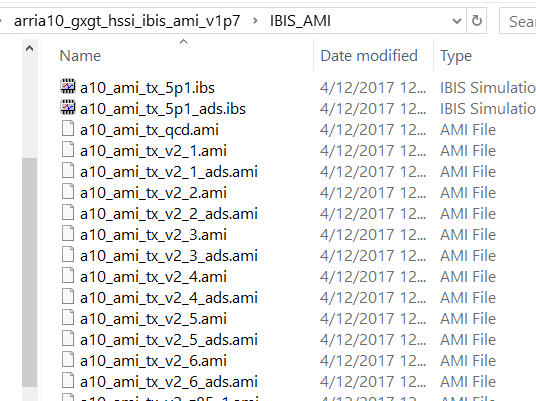
The second example is also from Altera but with different approach. There are many different .ami files, each supporting different usage scenarios.
In our approach, we let user to assemble a csv table first with needed columns to provide settings for different modules, each row is a pre-defined configuration so no further check of valid combination is needed.
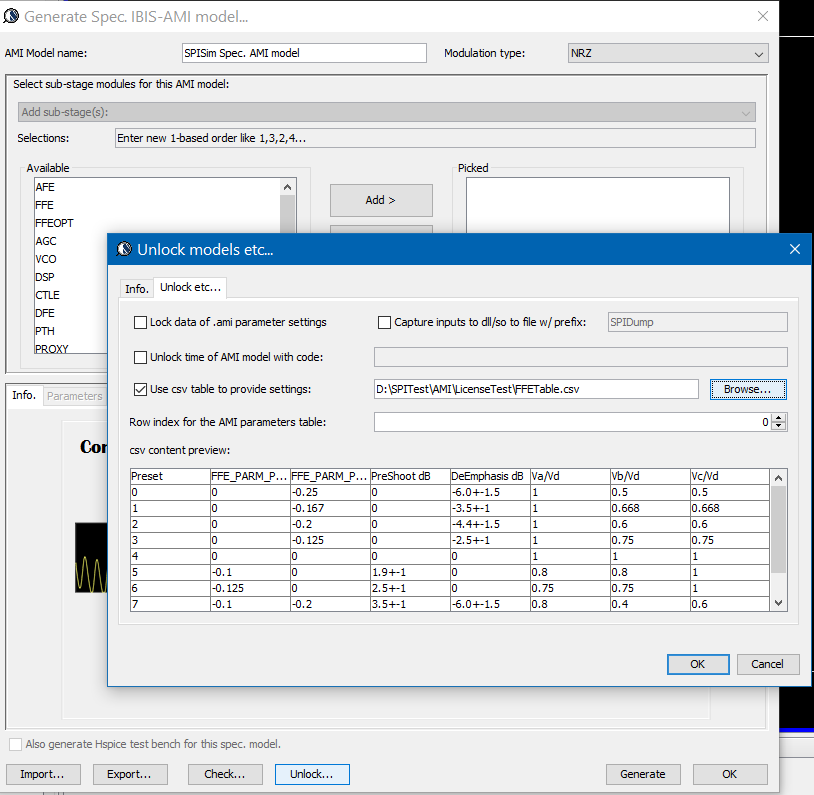
With this approach, customer only need to change the row index, rather than different settings of different taps or modules. More over, the table is encrypted and the model publisher can provide different set of configuration to different customers, all with same set of data and .dll/.so models.
With our approach, user use our GUI front end to perform settings, then associated .ami file and pre-built .dll/.so files will be generated instantly. The .ami file contain minimized settings to make sweeping AMI parameters more easily. This minimized .ami settings will also make configuration within other EDA tool more convenient. As a result, with the help of front-end GUI, the “black box” magics resides in both the .ami file and .dll/.so models.
Check before use AMI:
It’s worth mentioning that the latest golden checker published by IBIS are now both OS and platform dependent. This is because they support embedded .dll/.so file checking on the most basic level now as well. Regardless whether you are a model developer or a model user, three steps need to be performed to validate the given or modified AMI models:
- Use IBIS’s golden checker (IbisChk6) to check the .ibs file. If this ibis file contains algorithmic model section, then the associated .ami and .dll/.so file will also be checked based on the platform. This will identify compatibility issue up front.
- Use a test driver to drive the .dll/.so and .ami file. This step is like connecting an ibis model to a test load and run simulation. A model may pass the golden checker, yet if the test load waveform is not meaningful, then there is no need to put into the full channel simulation. This step makes sure not only the model can be loaded (has all required API function defined), but it can also function properly. In HSpice and Ansys, this test driver is called “amicheck.exe” and require respective license to run. We SPISim also provide free checking/driver tool call SPISimAMI.exe for this purpose.
- The last step is to put into channel simulator such as HSpice, Cadence’s SystemSI, Mentor’s HyperLynx or sort. They will provide simulation measurement such as eye, BER and bath-tub plot for further validation. These features will also be in our SPICPro later this year (2017)