

IBIS-AMI: roles and scenerios
SERDES based links, such as USB, PCIe and SATA, are now ubiquitous. Their SI analysis poses special challenges as low bit error rate required by their spec. means millions of bits needs to be simulated. In stead of using transistor level design details or proprietorial behavior blocks (e.g. Verilog-A or matalb model), an industrial standard, exchangeable modeling format are usually required. This is because Tx and Rx IPs may not be from the same vendors, nor are the simulator or analysis tools used by IC and system integrator. IBIS-AMI is currently the industrial standard for this purpose. Just like a traditional IBIS, only more cross-domain knowledge demanding and technical challenging. It requires certain flows to be able to test, generate, validate and release IBIS-AMI models. In addition, the considerations related to IBIS-AMI also depend on the these different roles and scenarios. We believe when developing or adopting AMI workflow, three usage situations, including 1. an end user, 2. a model developer and 3. a model publisher should all be considered thoroughly.
As an AMI model user:
This is the most common scenario. As a model user, one will often want to validate and test the received model first before running full simulation. Take an IBIS model as an example, the validation tasks usually include first: check with golden parser, then run time domain simulation driving IBIS model to simple test load and check response. More diligent users will also want to extract the performance matrices such as impedance and Rtt etc to make sure the it matches what’s claimed by the model name.
The example below show pretty good matches in terms of impedance of different corners (34 and 40 ohms).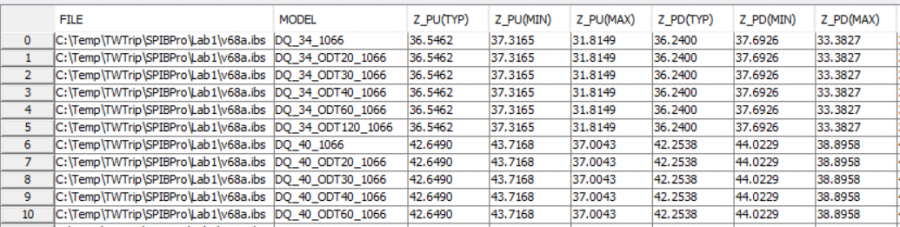
When it comes to an AMI model, things are not that easy. First of all, AMI binary model files (.dll(s)/.so(s)) are not only OS (e.g. windows vs linux vs OSX) but also platform (e.g. 32 bit and 64 bit) dependent. This means that unless a model’s file name contain correct info (e.g. TX_Win32.dll), one usually can’t easily check by just looking into the content of the binary file. Secondly, depending on the version of the spec. the implemented APIs in the model are also different. Again, these implementations are in compiled format and one can’t easily check. Lastly, even the latest golden parser will not exercise these API calls, let alone checking their performance. And to excite an AMI model usually involve third party (often expensive) EDA tools usage and required license.
EDA tools like HSpice does provide a simple utility called AMICheck for this purpose. Similarly, companies like SiSoft and Cadence also provide some development kit which enable AMI model checking. However, in the HSpice’s case, a license is required to run this utility. For the later two cases, the development kit needs to be compiled into respective OS/paltform first and the input and output to the models are not flexible. All these poses obstacles which prevents a model user to be able to quickly check the received model.
We believe a simpler yet more elegant solution should exist. That’s why we developed the SPISimAMI and release it as free tool. It’s also been compiled into different platform and can be freely download to use directly. With this utility, a user can drive given AMI dll file with accompanied .ami settings. Tool will first load the dll to make sure it matches the OS version of the executing SPISimAMI utility. It will then load the models and check mandatory API functions such as Ami_Init and Ami_Close. User can then use embedded rising/falling step and pulse response to drive these Ami_Init and Ami_GetWave functions if available (too will check whether the GetWave_exist is set to true). Alternatively, an user can pass the input response to the model in either .csv, .tr0 or .raw format. The output waveform from the model will then be saved as non-proprietorial .csv and .raw formats to be inspected by tool like excel or our free SPILite and SPIPro. The screenshot below show its usage: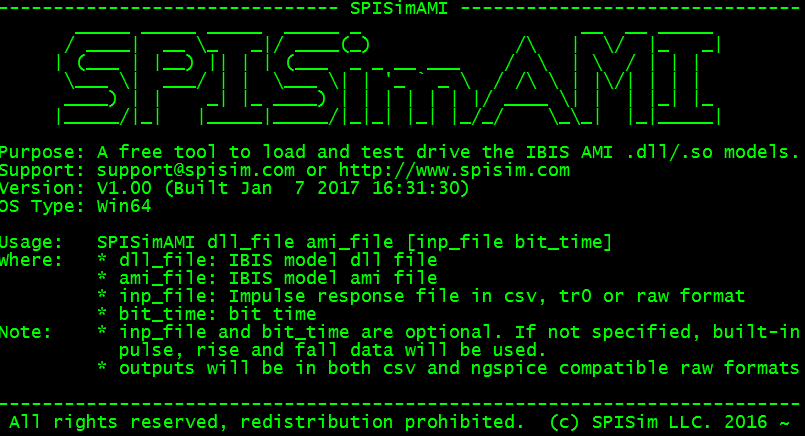
An example of quick AMI check using this features is to feed input bit sequence and check the equalization level output from the AMI model: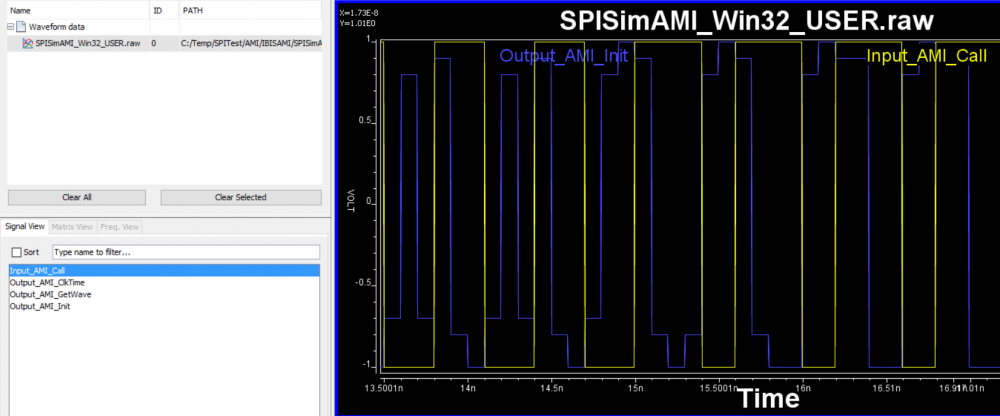
Regardless which approach or tool one takes, we believe that as an AMI model user, these checking process and capabilities should be considered due diligence and must be done before performing full link analysis with these AMI models.
As an AMI model developer:
AMI model development usually requires cross domain expertise. For example, a model developer needs to know how AMI and associated IBIS models are used. Then computer science skills such as programming in C/C++, implement APIs and use compilers like Visual Studio and g++/gcc to produce .dll/.so are also required. Finally the domain knowledge such as DSP, equalization and link analysis come to play. In terms of implementation, a model developer not only needs to comprehend these technical details but also needs to architecture codes in a way that the model is modular and can be easily extended. This is often important as design of different generations within the same company may be different only slightly, thus a proper modeling architecture will allow new model to be created by deriving from the common base class (think about object oriented design). From the discussions above, one can easily see that this modeling effort may either require dedicated engineering resource or expensive contracting service to get the job done.

CS skills are required in AMI modeling
To address thess hurdles, EDA companies have provided several top-down based solutions (albeit expensive). In my opinions, these flows are very capable. I think their advantages and strength come from the fact that many building blocks (mainly for RF purpose originally) are already available in their library, thus translate these propitiatory structure into C/C++ language and make them compatible with AMI API are obvious solutions. However, it’s also my belief that an AMI model developer should not fully rely on these flows. At the end of the day, just like any other software product, the developed model should be maintainable, extensible and efficient. An owner of these tools can take a look at the machine generated template and find that these flow’s results are usually not the cases:
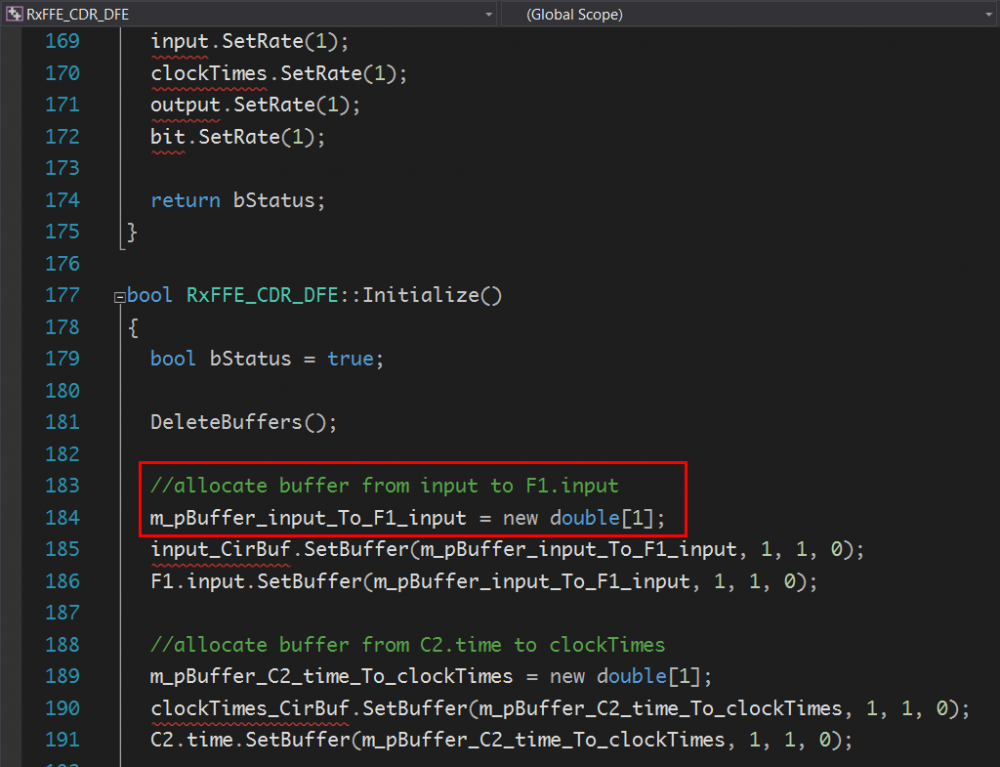
SystemVue’s codes, using buffer of size 1?
After looking these codes, as a developer, you should ask yourself how you are going to debug these machine generated codes when your user report bugs or issues. And will you be able to extend their functionalities with ease?
Fortunately for SERDES applications, where AMI are used most often, the function blocks are usually has common behaviors. For example, feed forward equalizer, low pass filter and pulse shape shaver are often required as part of the modeling functions. So for long term considerations, a company or a developer should really bite the bullet and build the AMI infrastructure from ground up like it should. Take all factors such as modeling architecture and code performance and maintainability into account. After this “exercise”, one will often find that a company’s SERDES designs do not change dramatically between generations and may developed codes/blocks can actually be reused just like their silicon IP. On top of these, one can also add functions not available from these tools such as encryption and other parameter locking mechanism.

A note worthy taken is that the aforementioned SPISimAMI utility can serve as a driver of the development stage. This way one does not require 3rd party (expensive?) tool or license usage to be able to drive and test the non executable .dll/.so under development.
As an AMI model publisher:
A model publisher should prepare to support AMI models he/she has released. The most common scenario requiring support is that the model does not behave properly or can’t achieve desired link performance. The complications here is that the user’s link analysis tool may often be different from the one a publisher is using. Without a common ground, it’s often difficult to root cause the issue without becoming blame game between models and the analysis tools.
We believe a free tool like SPISimAMI can again resolve this issue. By providing a free available tool supporting data capture both input to and output from the model in non-proprietorial format, data exchange becomes easy. An end user simply needs to probe the input signals to the model, save it as customized input and send it back to publisher. A model publisher can then use same AMI driver tool to feed in this input and observe model response. All these are done with most basic/simplest manner directly with the models instead of other analysis functions. Together with more advanced programming techniques such as proxy based modeling pattern, data will become even more transparent and not bonded by a particular link simulator. This way, both model publisher and end user can focus more on the AMI model’s proper usage and performance rather than the discrepancies between different EDA vendors’ tools.