

Preface:
In previous post, we discussed several possible roles involving IBIS-AMI and their points of considerations. In this post, we would like to focus on the AMI model developer’s role and explore several modeling flows along with their pros and cons. The materials and example discussed here are from publicly available sources and articles, which are also listed at the end of this post.
IBIS-AMI models:
Regardless how sophisticated a SERDES design is, at the end of the day, the work of generating a corresponding AMI model is to create the following the 3 ~ 5 (depending on IBIS spec. version) AMI API functions in C language and compile them as .dll(s)/.so(s) across different platforms and OSes. Noted that the actual implementations (how the SERDES or EQ operates) are not bounded by C/C++ language. For example, one may use matlab, octave, perl or other language to implement the core function, only that they have to be wrapped with C AMI-API functions. Regardless, the main objectives are still the same: translate the design to corresponding codes. On top of that, one also needs to consider how to debug, maintain and extend the generated models for model users and future design revision.
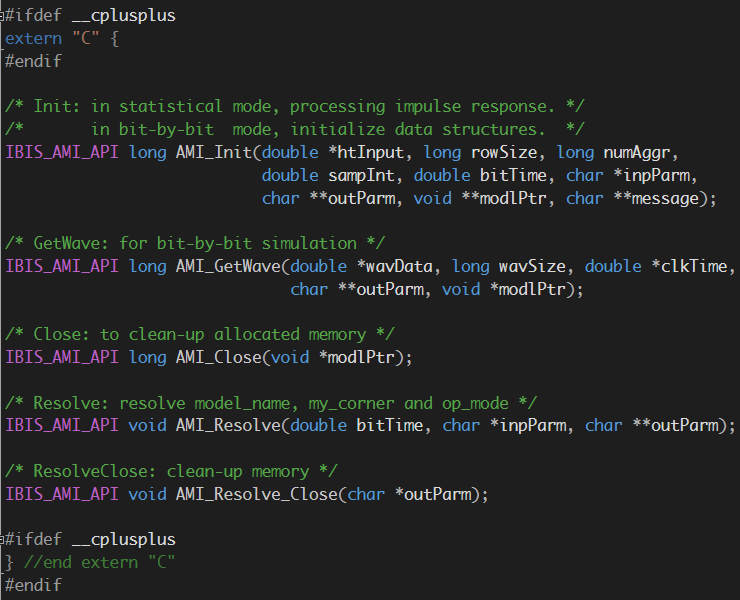
IBIS-AMI API functions
A very popular, and relatively easy approach to achieve this goal is to use tool/program to generate codes directly from design collateral.
Top-down AMI modeling flow:
A typical design flow is usually top-down based: floor plan is made and functional blocks are defined. At first, only abstract level behaviors, budgets and/or spec. are given. Each designer or team then dives into the detailed implementation of these functional blocks and finally assemble them together for full design simulation or verification. Using this approach, a schematic is usually used for design entry and connect different block first, each block may have several hierarchies. Architecture codes/schematics are translated to C/C++ by machine.
User also usually can right click on each block to specify parameters for customization or exporting. When it’s done, an add-on module will translate this design to corresponding C/C++ format most of the time. So far as AMI API is concerned, a special AMI kit may be also needed such that generated codes will be AMI-API compatible.
With this approach, user focuses on SERDES design rather than the coding or API details. Since these architecture blocks/codes are pre-generated and verified, the generated codes are considered well tested and should produce good correlations.
Machine generated codes:
While machine/program generated codes are pre-tested and usually very structured, it may not be easy to debug and extend. While it’s certainly possible to rewrite part of the codes for fine tuning or customization, one should not forget that next time when the designer click “generated c/c++” button again, all the changes will be overwritten. So the update made at the bottom (i.e. generated codes) will not back propagate or back annotate to original design. One almost always have to change from the top.
My observations for this top-down approach are:
- Suitable for designer who has original collateral, don’t know or want to code.
- These are mostly machine generated codes:
- Should run correctly as it has been tested
- May not be efficient, (most of the case, certainly in this case above)
- Not easy to maintain…. bad readability and can’t enforce coding guideline
- One direction only, code changes can’t back propagate.
Bottom-up AMI modeling flow:
If a software developer is going to tackle the AMI modeling challenge, his/her approach probably will be different from that used by the SERDES/IC designer. If it’s me, a bottom-up approach will probably be used:
- 1st, one will identify several common blocks to be used, such as
- FFE: Feed-forward equalizer, LTI, Time or frequency domain
- LPF: Low pass filter, LTI, freqeuncy domain
- CTLE, Bassel, filter based IIR/FIR etc
- DFE: Decision feedback equalizer, NLTV/digial, time domain only
- CDR: Clock data recovery, NLTV/digital, time domain only
- Coder: various coding page
- 64b66b, 8b10b etc
- PRBS: Pseudo random bit stream, PRBS7, 10, 15 etc
- AFE: analog front end to convert pulse to shape with Rt/Ft/Swing etc
- 2nd, one may define common interface, data member etc between these blocks and use OO principles to construct base and derived class etc
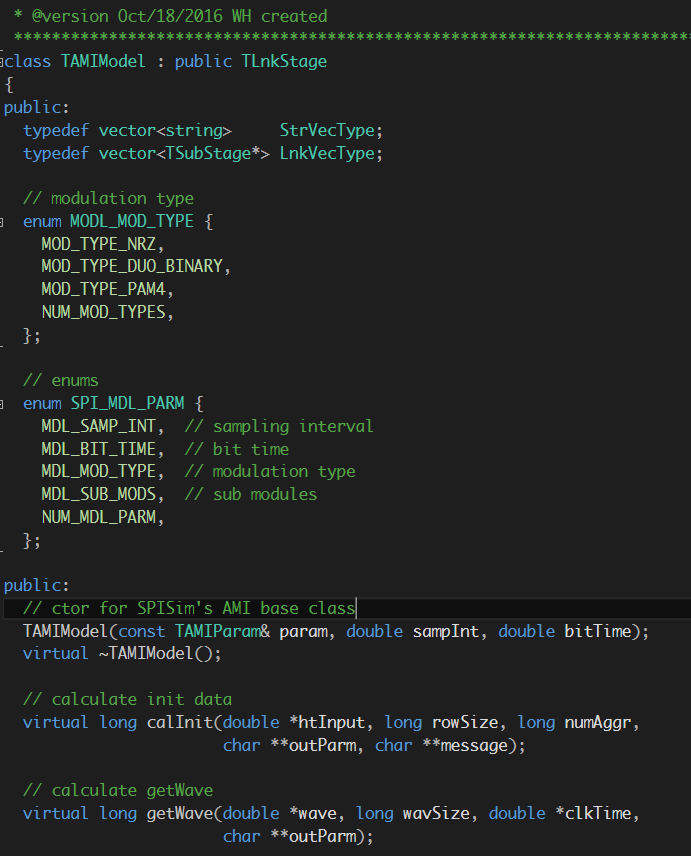
- 3rd, being able to assemble different stages elegantly and form an AMI model of this stage:
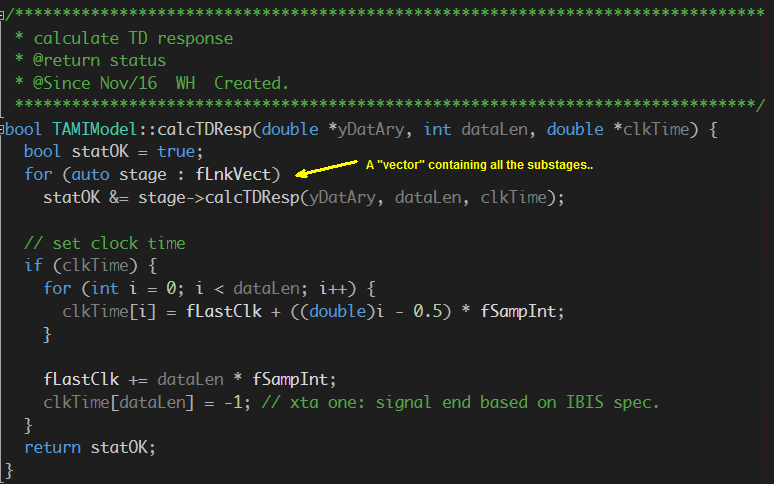
- As a bonus, one can then easily add extra mechanism such as security, encryption and/or different selector of different CTLE responses as an example.
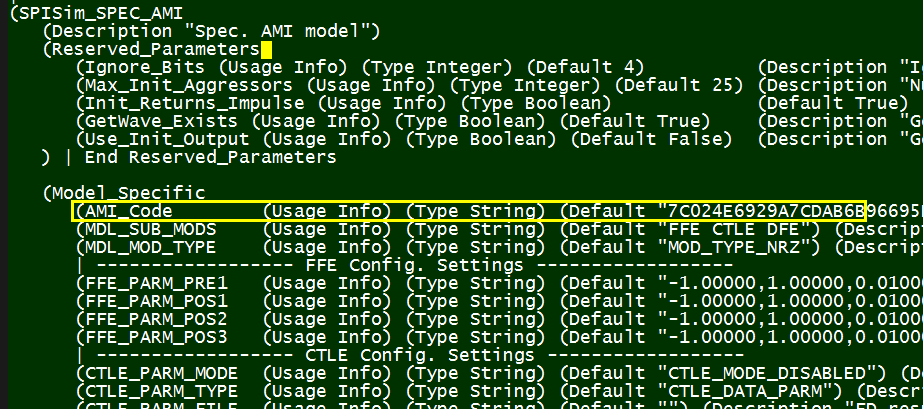
Since this is hand cranked, the developer should feel very comfortable supporting, debugging and extending the functions. Accompanies with good documentation, it can be used for very long time. In order to make sure the model’s performance matches those from the original design:
- The classes should not be hard coded with number. Instead, settings etc should be parameterized and can be tune either programmingly or from the .ami file
- A “sweep”, least-squared-error based fit or other optimization methodology can be used to find the set of parameters which match the original design’s performance best
- In other words, the good correlation is not “given”. It needs effort.
My observation of this bottom-up approach are:
- Suitable for engineer person who is good at OO and comfortable coding:
- Human written codes:
- Need effort to make sure codes can run correctly
- When doing it right, will run very efficiently
- When doing it right, will be easy to maintain and extend
- Code usability is very high, save effort/resources in the long run.
Spec/Datasheet based AMI modeling:
From the discussion above, it seems both top-down and bottom-up approaches each has its own merits. Is it possible to have best of both worlds?
It’s not easy… since each engineering’s disciplines are different, and that’s also why doing IBIS-AMI modeling is technical challenging. It demands cross-domain knowledge and experience at least. We haven’t even discussed algorithms such as FFT, iFFT, DSP, BER etc above yet…
Having that said, I believe that this still possible if we can eliminate short comings of either side. For example, One can look at other EDA vendors’ AMI library parts and find that they are actually well organized and architect like the bottom-up thinking above. So it must be the process which translates schematic to codes which compromised results. This is most likely due to its general purpose usage: “design anything and tool can translate to c/c++”.
Since it’s not easy to change big EDA company’s product and application scope, if one can find suitable DSP/filter design library to use in the first place in the bottom-up flow, then a well behaved, efficient, maintainable and extensible modeling is not that out of reach. Fortunately, there are plenty of such open source libraries available. Further more, commonly used functional blocks can be assembled together based on settings or parameter. They can even be pre-built/pre-compiled so the compilation can be further avoided. The end result is template/spec/datasheet based, AMI modeling approach.
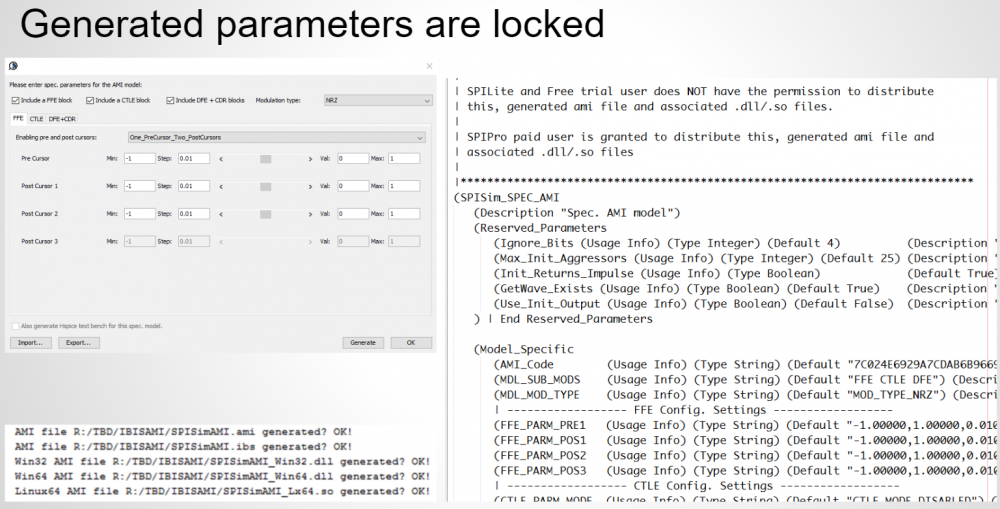
SPISimAMI: Spec/Datasheet based AMI modeling
Many recent publications, alone with the adoption of this approach from smaller EDA company like us, has supported this as a better modeling flow so far as IBIS-AMI is concerned.
Reference:
2015 DesignCon paper: [HERE]
2016 IBIS Summit paper: [HERE]
2016 DesignCon paper: [HERE]