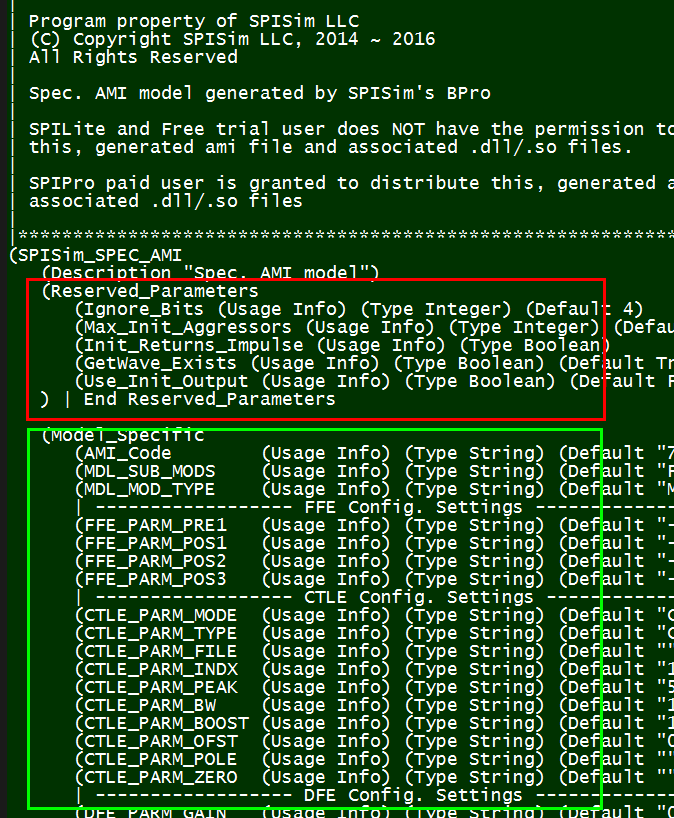
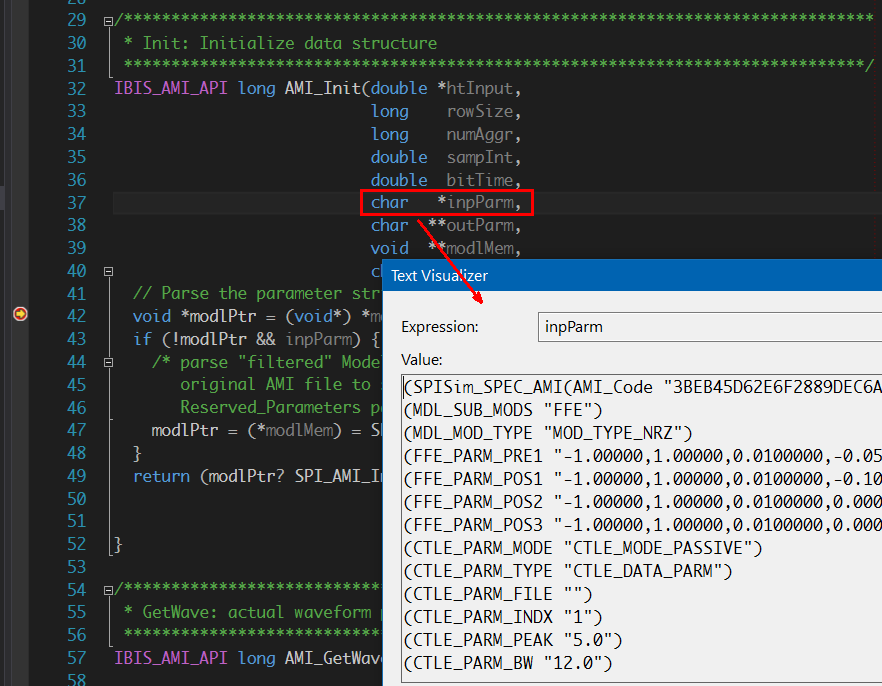
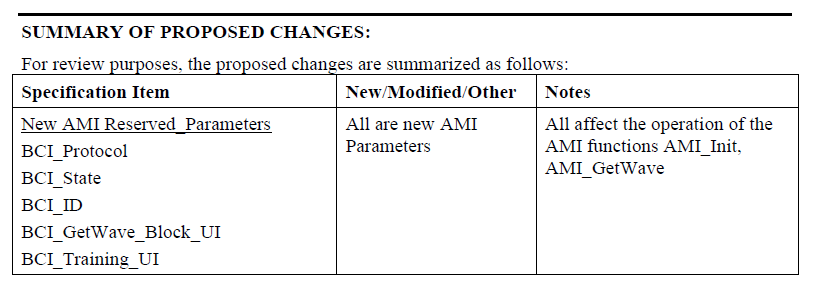
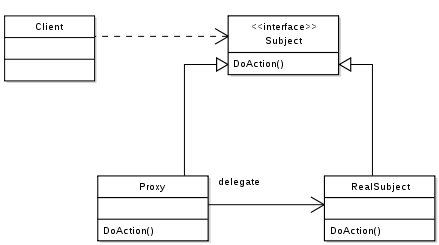
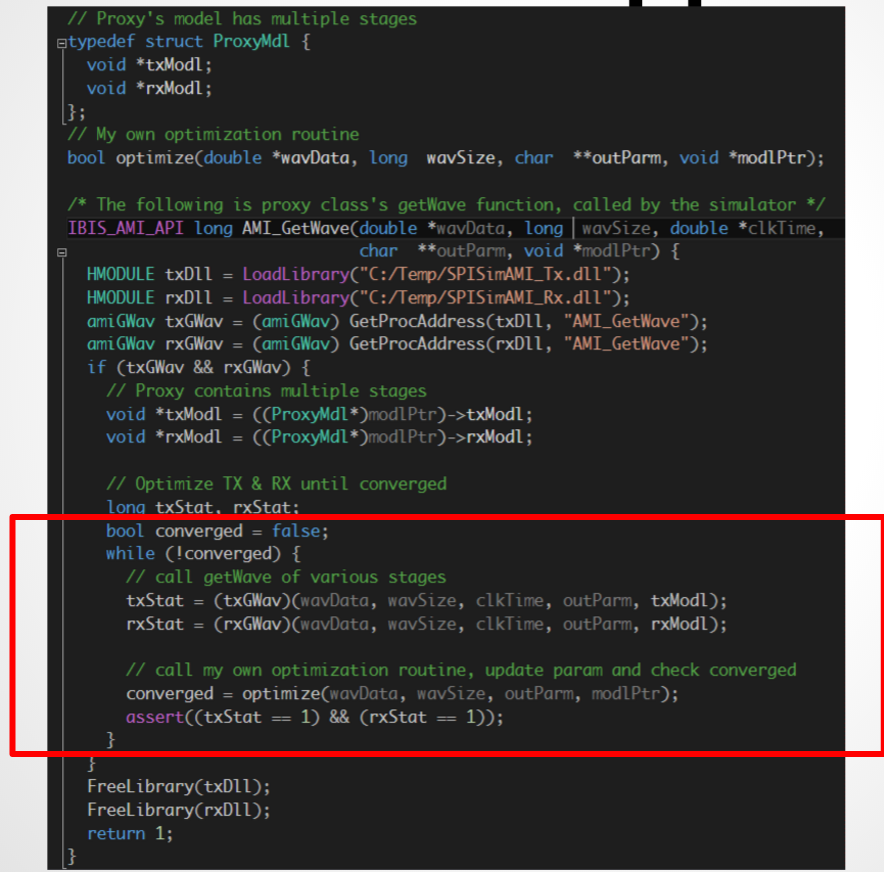
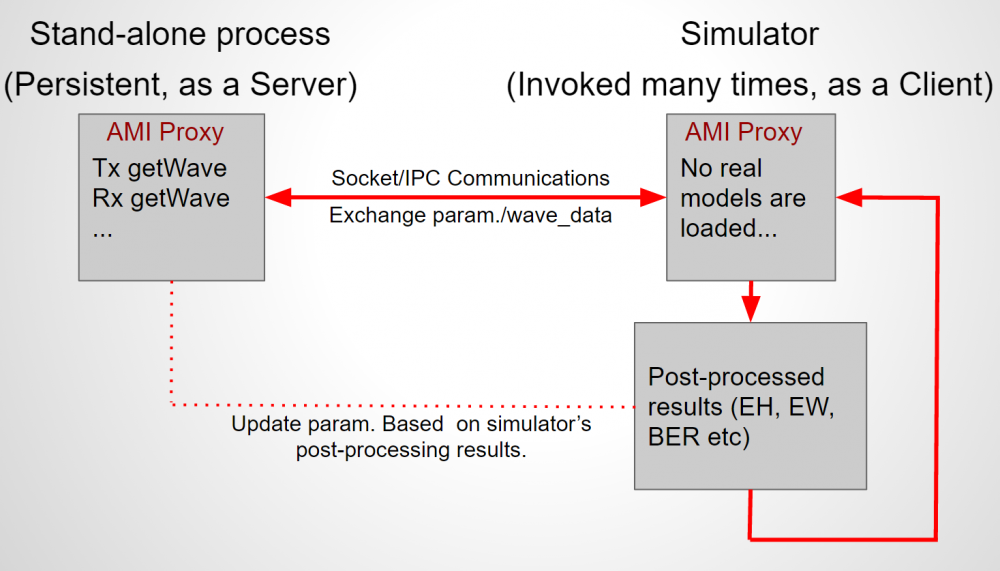
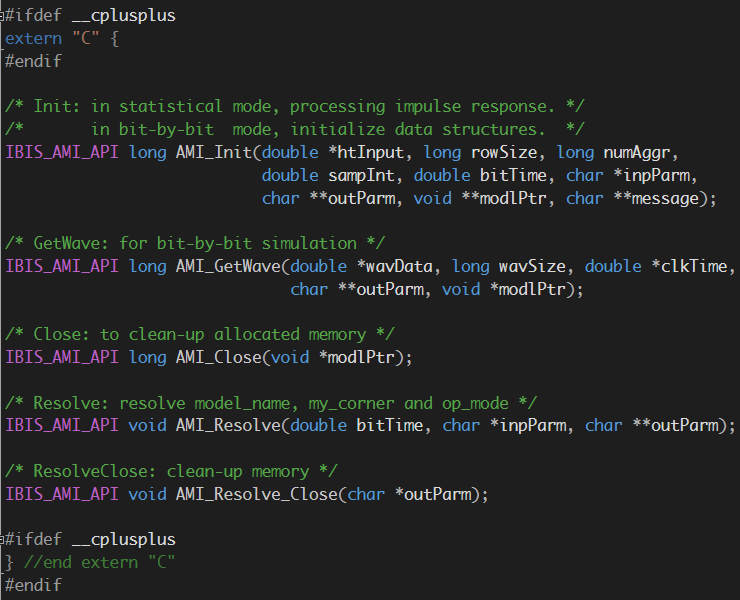
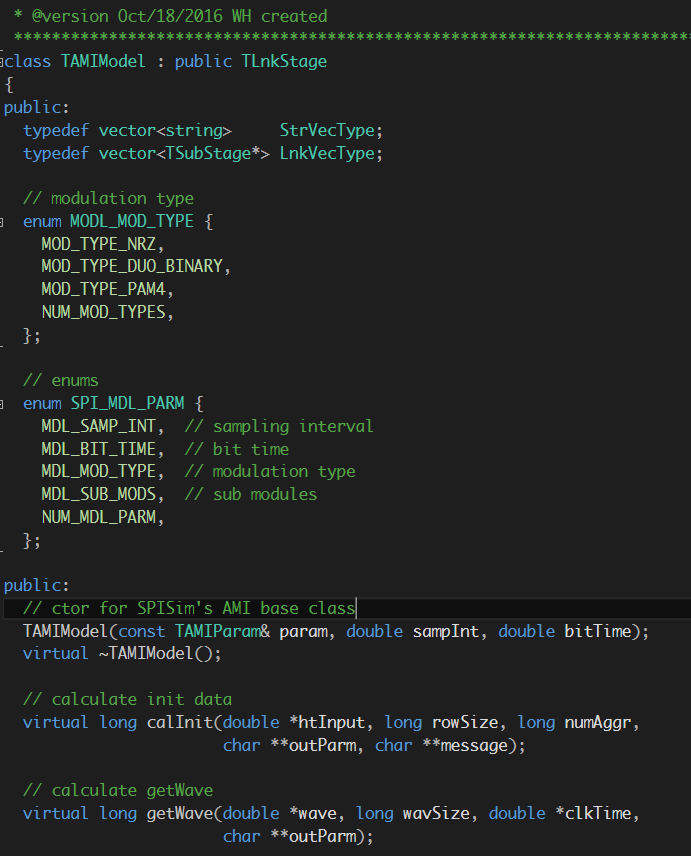
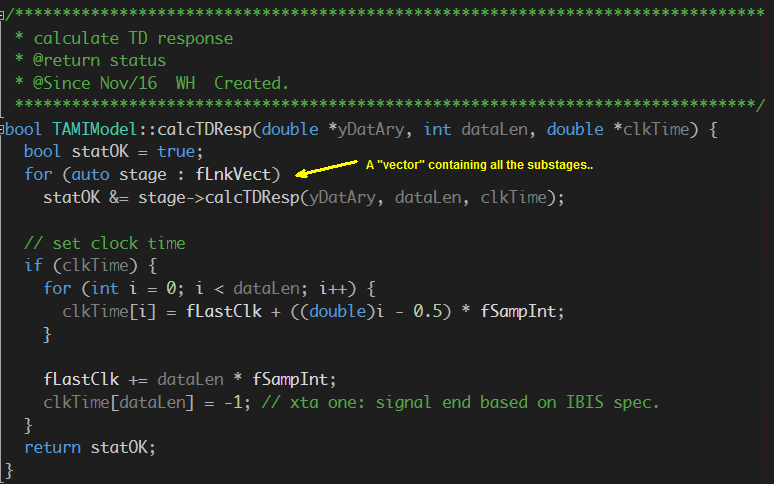
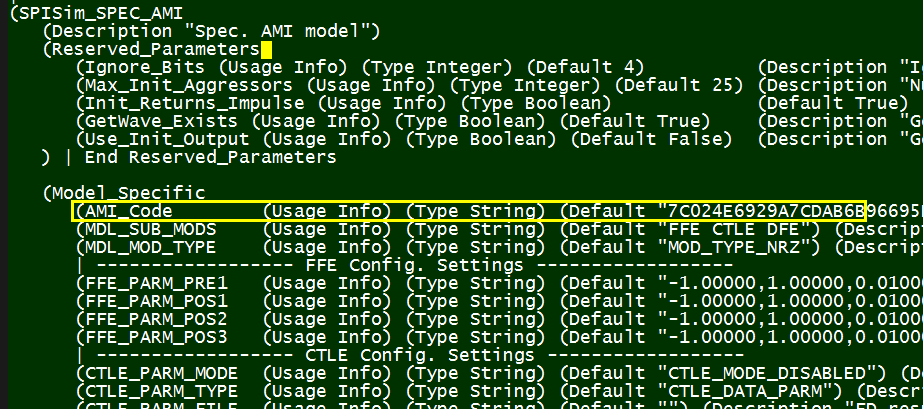
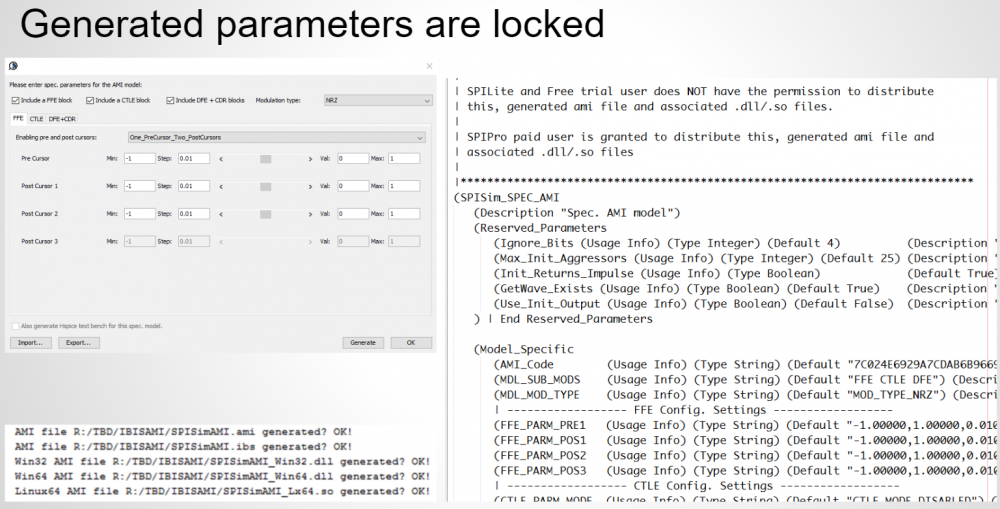
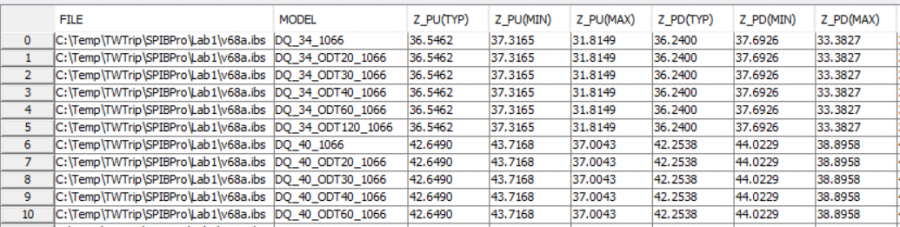
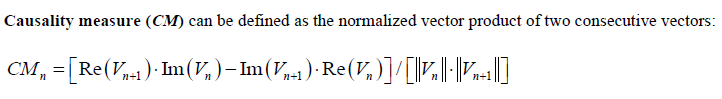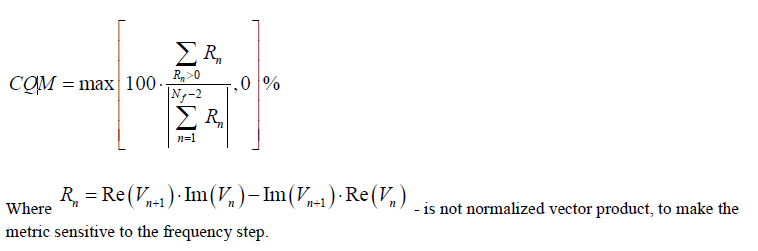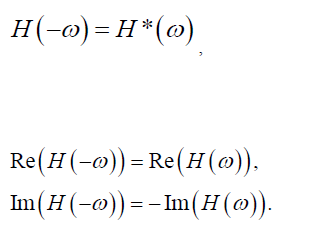Preface:
A S-parameter model can be obtained from lab measurement using VNA, full-wave field solved from a 3D structure, analytically computed via AC simulation or analysis process such as cascading of various stages. There are many situations when more than one s-parameters will be generated for similar setup. When dealing with multiple s-parameters, one should be able to quickly batch process and generate a summarized report for desired performance or measurements. Equality important is to be able to investigate and debug on a case by case basis. Both of these functions are also must haves for an EDA tool supporting S-parameter models.

Example report from the PLTS tool
In this post, we would like to discuss points of considerations when planning for these types of analysis and reporting capabilities. We would also demonstrate how they are accomplished in our SPIPro tool. Most of the mathematics for these processing can be found on website such as RFCafe or matlab RF toolbox.
Analysis:
There are many analyses often used so far as s-parameter is concerned. They can be classified into several categories:
- Conversion: such as converting a single ended S-parameter to a differential one or one with mixed mode (mixed single and differential), converting between S and Y, Z, ABCD formats, etc
- Extraction: such as trimming unwanted frequency data points, extracting subset of S-parameter, or calculating physical properties such as impedance, effective inductance etc
- Generation: such as cascading different stages together, either assuming generalized 2N port in a point-to-point topology, or arbitrary ports branching out like those multi-drop situations in DDR, combining S-parameter data in other fashions such as merging, synchronizing frequency samples etc.
- Processing: such as smoothing the data using moving average, extrapolating toward DC and high frequency based on physical properties, renormalizing reference impedance to different values.

10 of 30 SPIPro’s S-Param analysis capabilities.
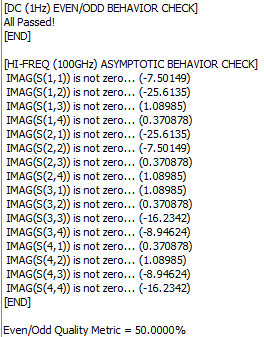
Based on our experience, Convert, Cascade, Renormalization and Quality check are most frequently used. For mixed mode conversion, several port ordering scheme should be supported: incremental, interleaved or even-odd mode.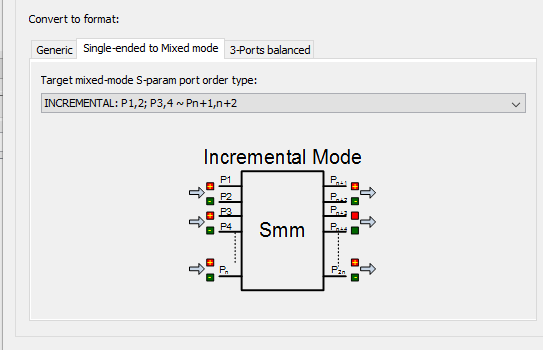
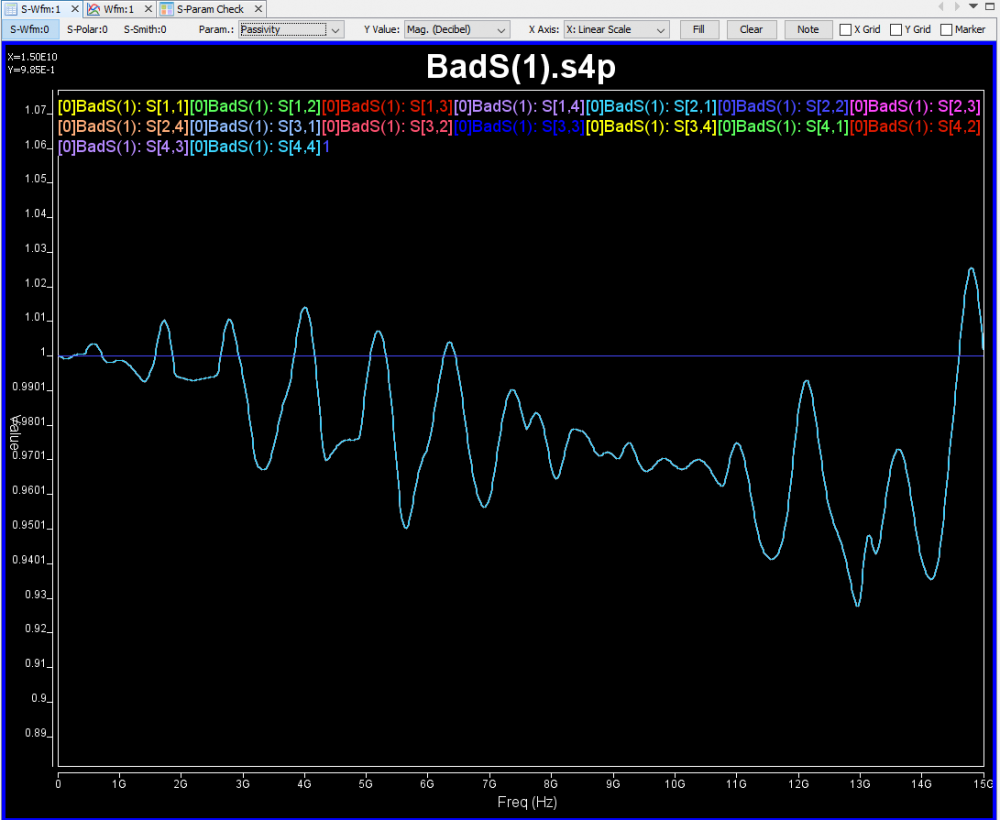
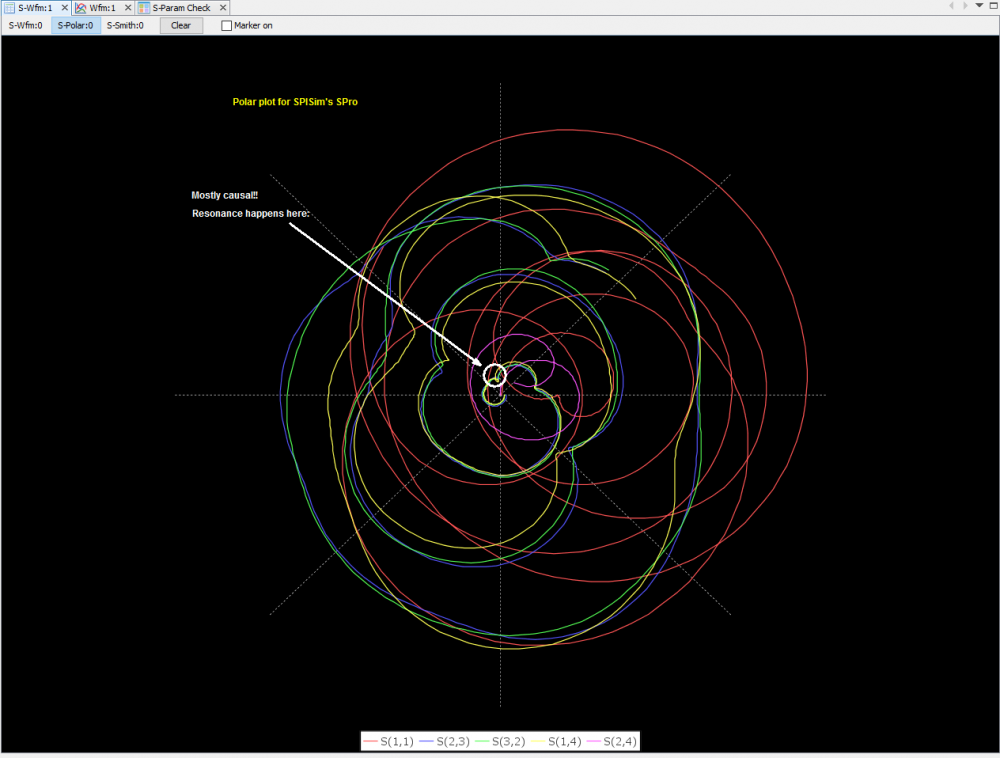
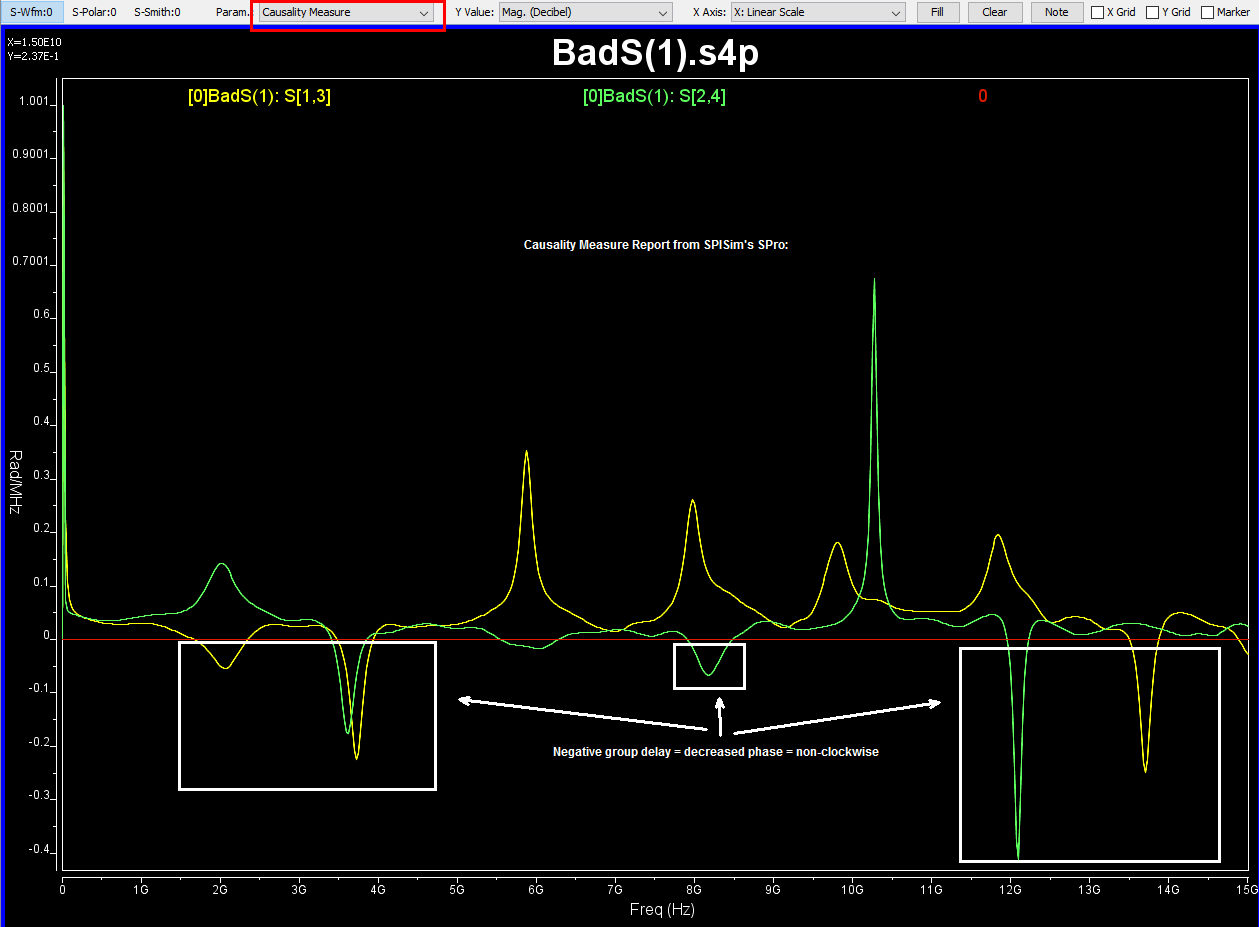
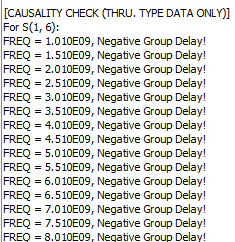
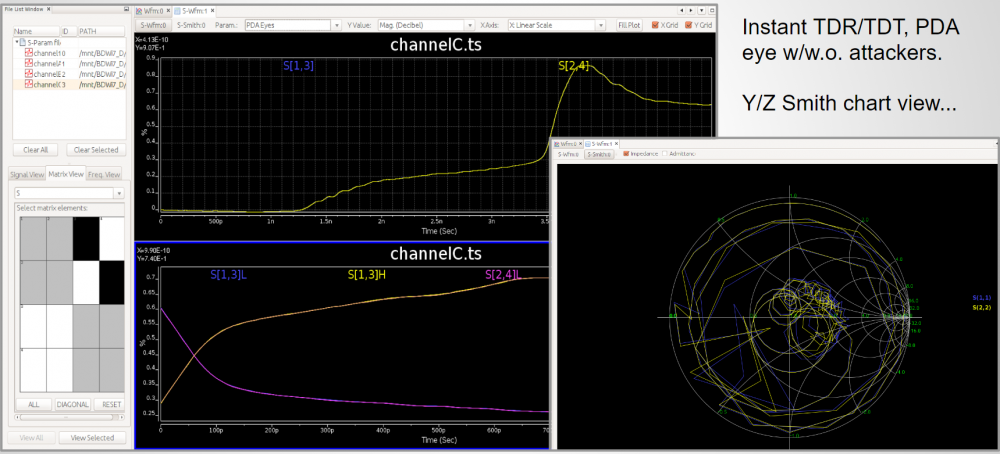
The outcome of the processing above are mostly another s-parameter. Thus one should be able to inspect selected individual Sij element either visually or textually further. For the same set of data, it can be plot in different format to reveal different properties or behaviors. For example, X-Y format by default, polar plot for causality inspection and smith chart in either Y or Z format etc. Since only several Sij elements are plot instead of the full S-parameter, some analysis can be done almost in real time to provide feedback: time domain reflection (TDR), time domain transmission (TDT), worst case eye analysis based on pulse distortion analysis or even passivity plot etc.
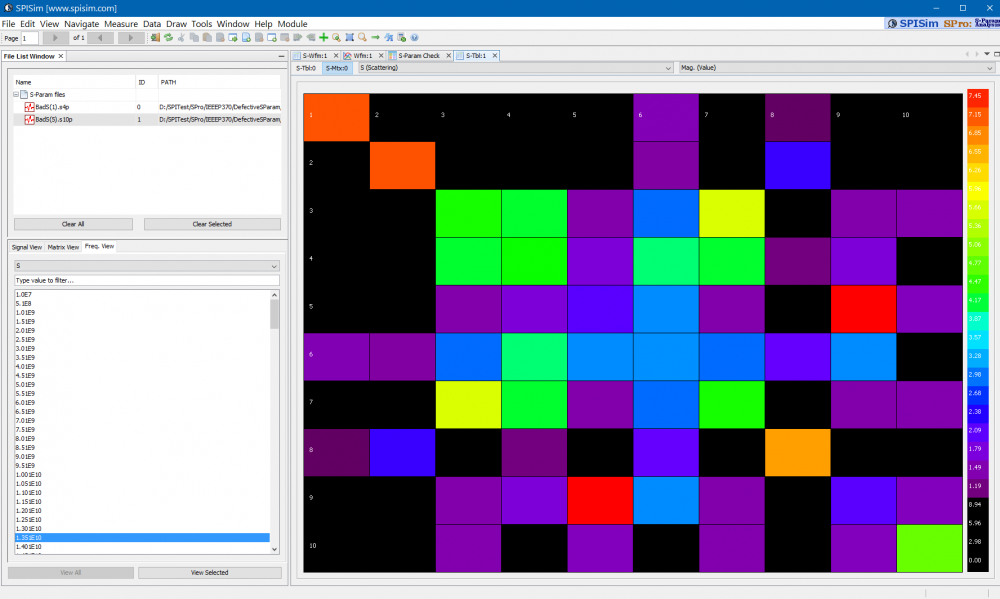
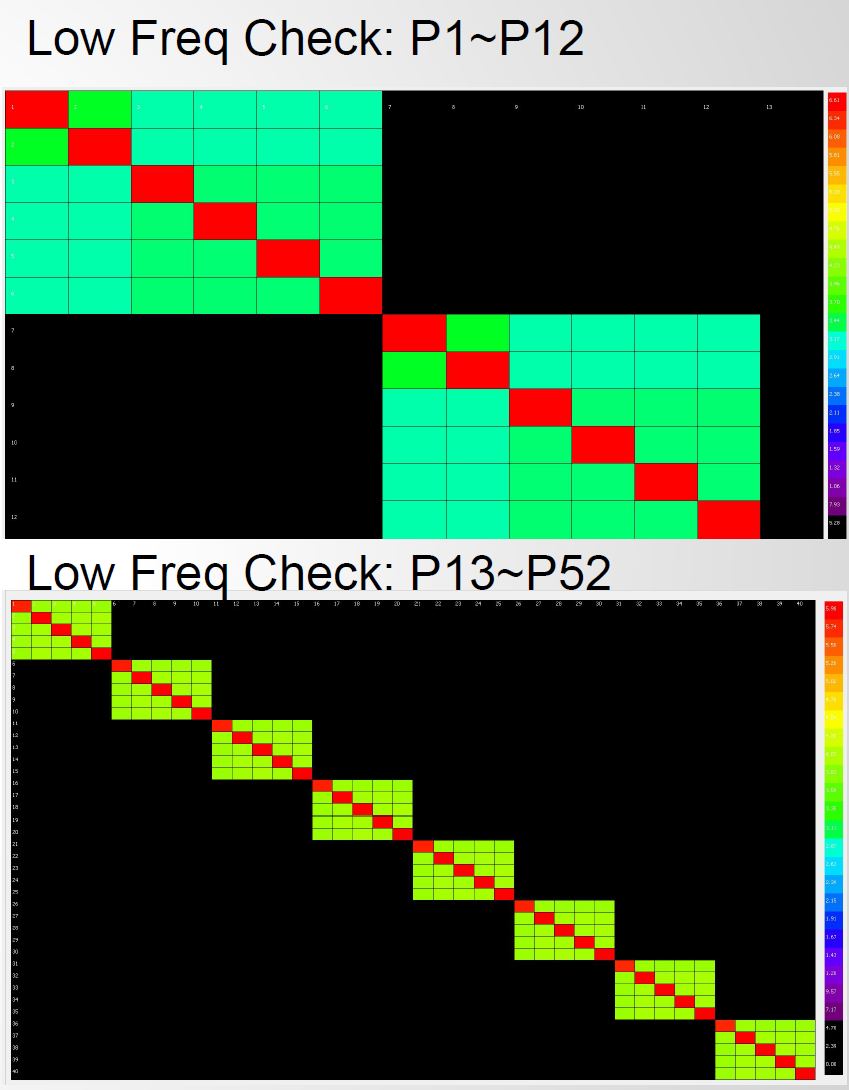
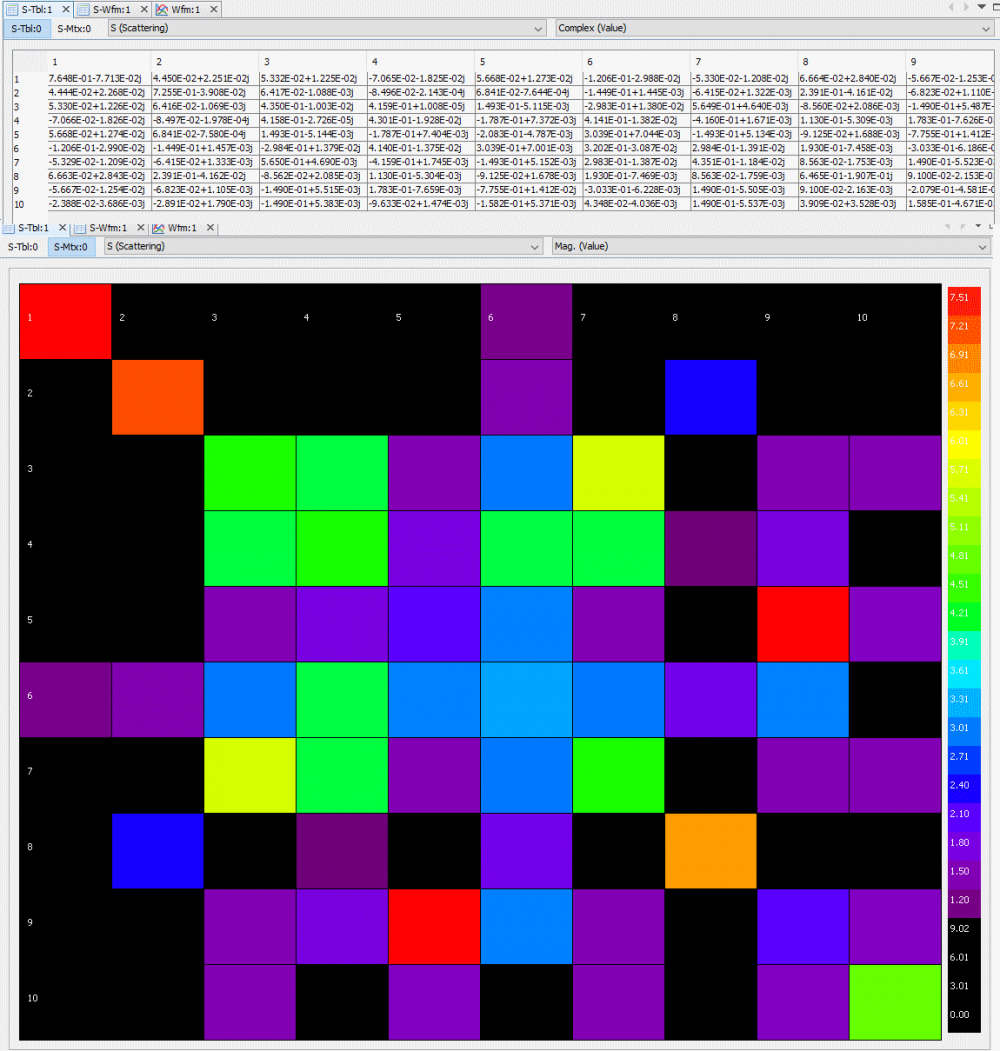
Texture representation can be useful when one needs to copy part of the calculated data for further analysis, such as taking effective inductance for power integrity simulation. Color coded matrix at the first and last frequencies are also useful for quickly checking connectivity or high inductance ports.
Report figure:
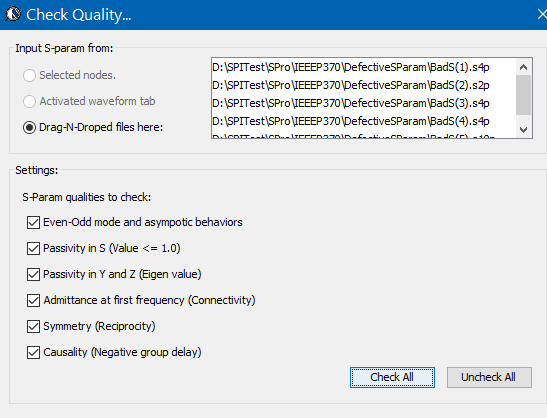
The analysis process mentioned above are good for investigation or experiment purpose. When there are more than several s-parameters need to go through similars sequence of operations, being able to batch process and report becomes important. In this case, the input conditions such as number of ports, their mode (single ended or differential etc) port ordering and reference impedance etc are specified up front (via GUI or a template). This settings will be applied to all the given s-parameter such that after they are read in by the tool, this sequence of actions will be performed automatically. After calculation, report in the form of various figures, statistics and csv can be generated:
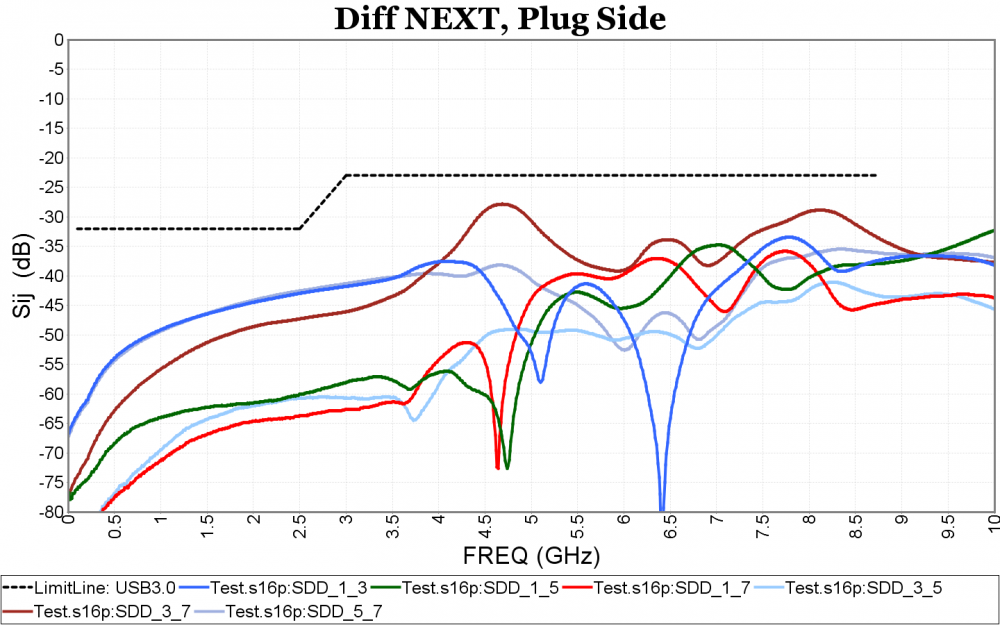
- Frequency domain figure: one or more selected Sij traces from the processed data can be plot in the X-Y chart in linear or log scale. Waveform calculation using real or complex number with various operator including log and power should also be supported. Multi stage limit line can be added to identify boundaries which signal traces should not cross.
One or more such figures can be defined for different data and measurements.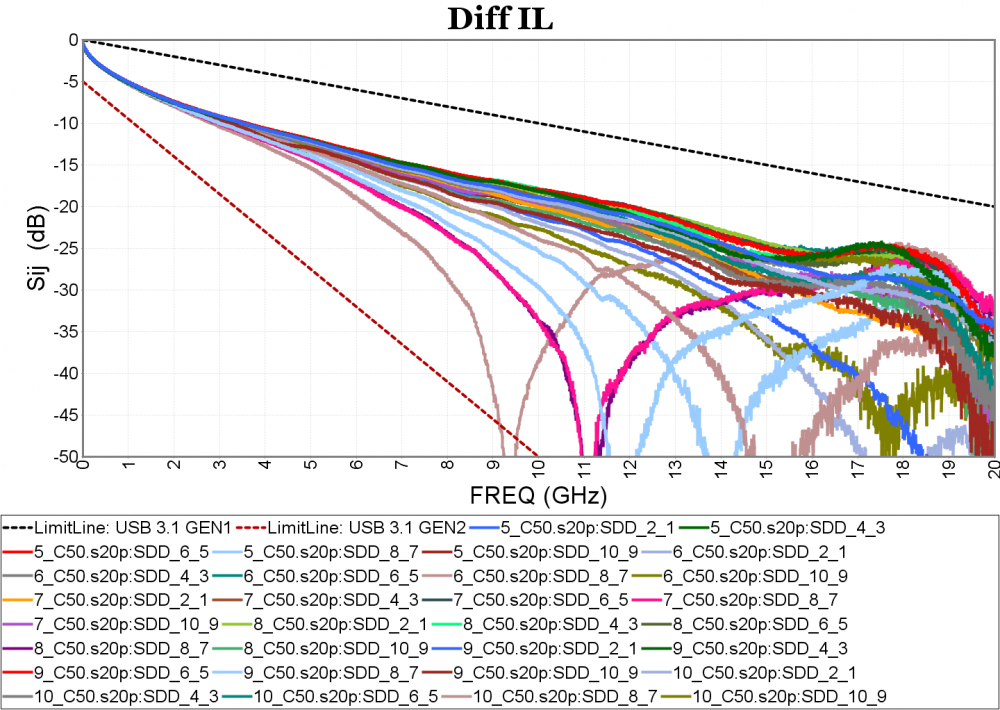
- Time domain figure: For time domain, Sij needs to be converted using iFFT first. To achieve certain time domain resolution, extrapolation to higher frequency and data smoothing using moving average may be needed. There are several time domain metrics often used: TDT, TDR, crosstalk, inter-pair and intra-pair skews etc. Input pulse’s rise time may affect the resulting slew rate so it needs to be part of the settings.

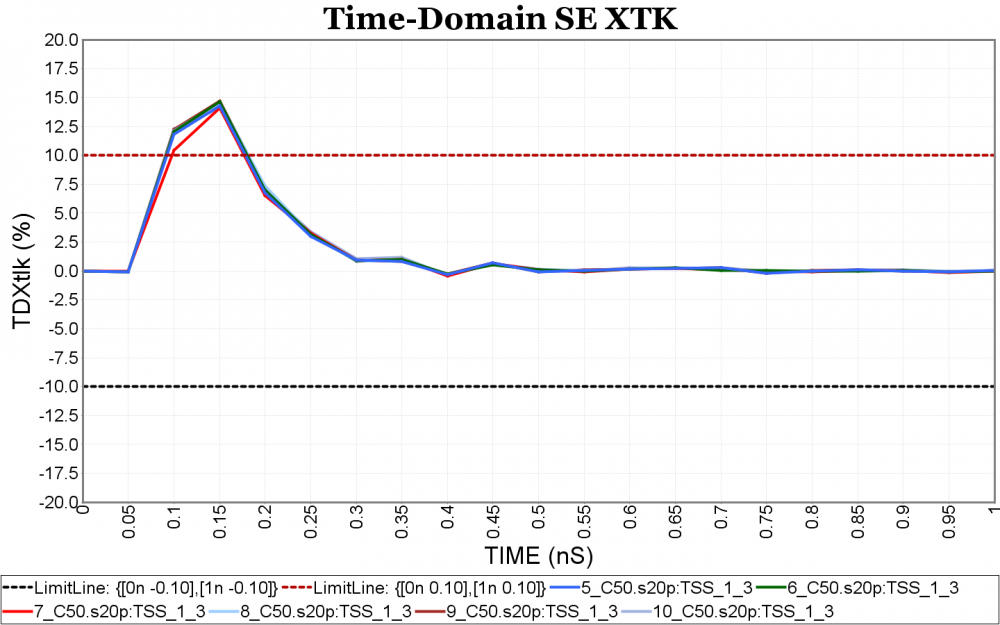 Again, one or more such time domain figures can be pre-configured so that their settings will be applied to all s-parameter data.
Again, one or more such time domain figures can be pre-configured so that their settings will be applied to all s-parameter data.
- Statistics figure: The timing or skew measurement can be summarized using a histogram with distribution curve. Their data in csv format can provide more detailed info. for individual cases.
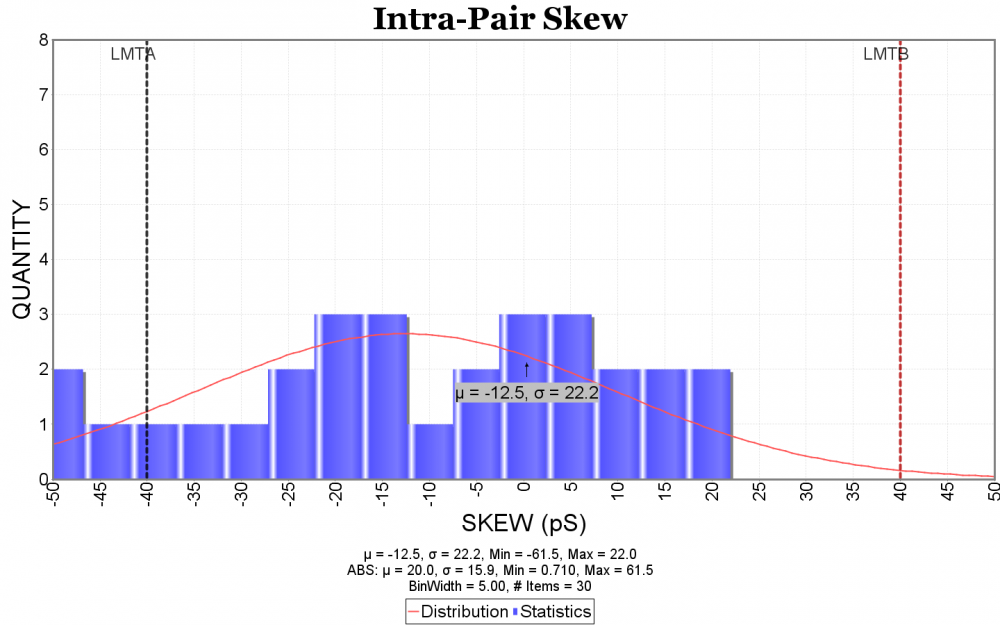
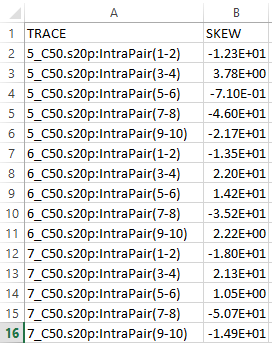
Allowing further customization such as various font size, frequency unit, grid line etc will make the generated reports more appealing aesthetically. Finally, these settings should be allowed to be imported or exported for later use. Resulting report can be in html or pdf format with indexing at the top of the page. With this kind of capability, analyzing a set of s-parameters become easy and efficient.
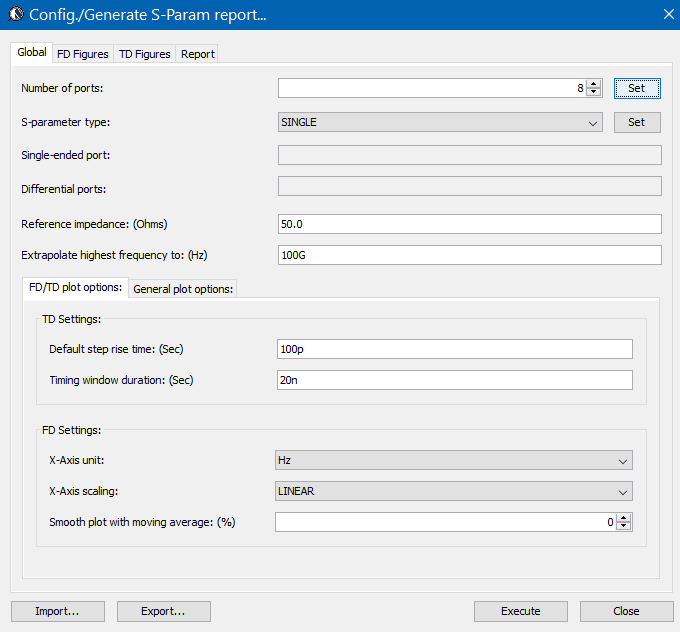
Report data:
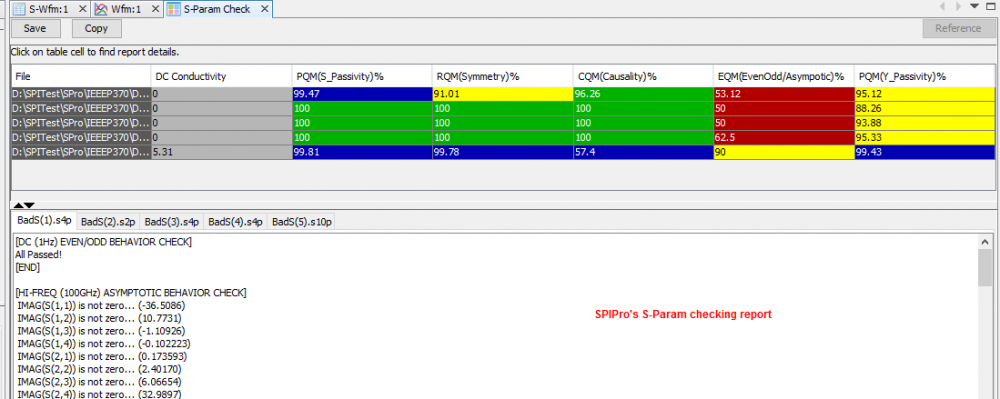
When there are even more s-parameters to be processed, such as hundreds or even thousands of cases from analysis methodology such as design-of-experiment or multi-dimensional sweep, even visually check with reporting becomes time consuming. In this situation, batch processing to extract performance value, summarized in a multi-column csv fashion to be used for statistic tool such as our MPro or JMP is more practical.
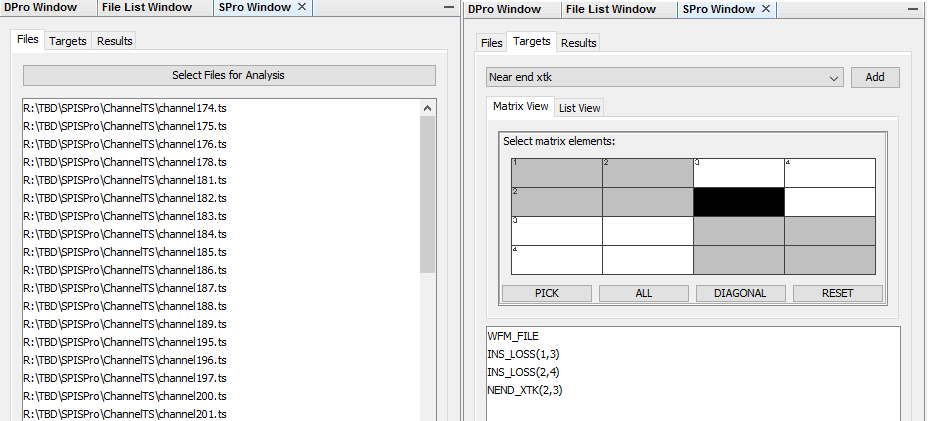
User first specify all the files to be processed, then specify one or more time domain or frequency domain performance targets. The processed results can be visualized as a summary plot. Interested cases or outliers can then be selected to generate more detailed report or investigate individually.

Unless specified, all the screen captures used in this post are from our SPIPro product. All the mentioned functions and capabilities are also supported in this product.