IBIS-AMI: 相關角色及使用場景
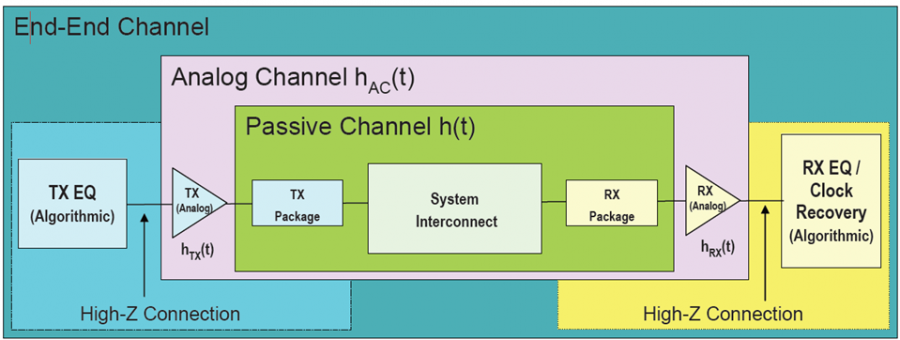
近年來以SERDES為主的相關介面:諸如PCIe, USB及SATA等早已是無處不在;有別於傳統以Spice為主的時態SI分析, 因為這些界面要求低BER, 所以總是要跑上幾百萬個Bit才能得到較準確的分析結果,所以在分析方法上就不能以傳統的IBIS或Transistor模型等來進行。而為了與業界EDA工具或其它IP來源模型一起運作的相容性考量,其它的行為模型如Verilog-A等也未必適合;在此考量下, IBIS-AMI已成為近年來最通用的SERDES模型格式。在使用及建模程序上, IBIS-AMI都較傳統的IBIS要求更高的技術門檻及更跨領域的相關知識。本貼文就與IBIS-AMI模型相關的幾種角色來做相關議題的討論。分的相關角色有:1.終端AMI模型的使用者, 2.AMI建模工程師及3.供應AMI模型的公司人員等。
以AMI模型使用者的角色言:
這是最常見的使用情況, 究竟大部份的人都只需要知道怎麼用模型就可以了。但做為模型使用者而言, 一般標準程序上在對全設計進行相對冗長的仿真分析前, 都應先對所要使用的模型做相關的測試及審核..以免垃圾進垃圾出。以傳統IBIS為例,較謹慎的用戶不會全然相信一般常以模型名字來標出的阻抗值(尤其是用的不是TYP corner時), 所以都應以軟體、手算DC準位的相關阻抗並連以簡單的測試電路(test fixture)進行快速的時態仿真以確認手上的IBIS模型無誤。
以下圖為例,我們用BPro的Performance Measurement 對相關的IBIS模型量測準態阻抗值,發現其與模型檔名所標示值相差不多,便可繼續進行下一步分析。實務上我們常發現的是MIN, MAX corner與TYP值相差甚多, 故在做SI分析時就得把阻抗的不匹配列如考量之一。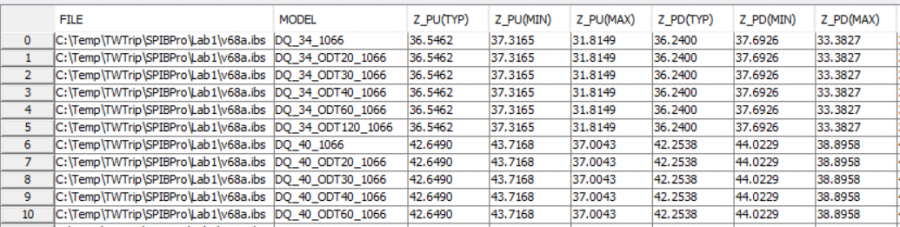
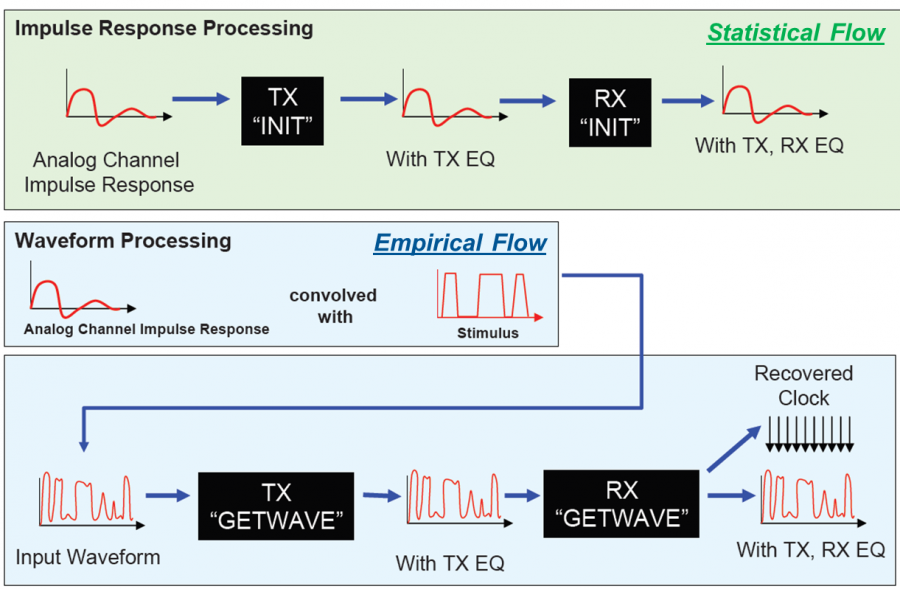
同樣的想法套用到AMI的模型上就有更多一點的考量。首先AMI模型是二位元機器檔(非本文檔), 所以外人無法一窺究竟…非得透過其它程式才行;其次此二位元檔不僅是和作業系統windows/linux有關, 也和系統的位元(32/64bit)有關,AMI模型無法在不相同的程式上運作。雖說模型檔案一般也會有相關位元的資訊(比如說TX_Win32.dll), 但最好仍是先做相關測試。其次, AMI應用程式界面(API)中所規定必需包括的函式隨著模型用法(statistical or bit-by-bit)及介面Spec的版本也有所不同, 所以使用上也需先進行了解。最後, 即便是至今最新版的IBIS golden checker也只查驗.ami檔案及AMI必含程序的有無來做檢測, 並不進一步地對這些程序加以驅動並查看其輸入、輸出結果, 換句話說, 模型用戶至今為止仍必需透過第三方(常是較複雜且昂貴)的EDA軟體才能對模型做進一步的檢測。凡此種種皆拉高了初步測試的門檻。
業界常用的仿真軟體HSpice有內帶一簡單的AMICheck程式,唯其需要正式版的license才能跑。EDA公司諸如SiSoft及Cadence也都有提供類似的程式, 但我們在使用過後仍覺得有更多改進的空間, 更不用說它們仍需要用戶在不同系統及位元上先做編譯的工作(因為是以DesignKit的型式提供), 所以在實務上,要直接用這些程式仍有多不便之處。
為此, 本司開發了免費的SPISimAMI程式並供業界下載使用(毋需註冊或License),為免為德不卒,我們也已在不同系統及位元上編譯好以便可直接呼叫使用。這個程式會針對用戶提供的.ami, .dll(s)/.so(s)做下列的檢測:
- 若呼叫的程式與模型系統及位元不符, 比如說用Win64版叫Win32的AMI模型, 則會顯示錯誤資訊。
- 會針對必有的AMI函式, 如AMI_Init 及 AMI_close做檢測, 其次會依.ami裡GetWave_Exists的必有設定來對AMI_GetWave做檢測, 所謂檢測在此儘是查檢函式在模型裡的有無。至此以上兩點功能大致和最新版的golden checker相同。
- 程式下一步會對這些檢測出有的函式進行驅動, 驅動模式有二:
- 用戶可提供自已的輸入波型, 波型格式可以是.tr0, .raw, 或.csv任一, 其中的.raw是開源Berkeley Spice的內定格式。
- 若無用戶的波型, 程式內建有rise step, fall step及pulse response以對程AMI_Init及AMI_GetWave加以驅動。
- 驅動結果的輸出波型會直接存成.csv及.raw格式, 用戶可用如excel, 我們所提供免費的SPILite或其它程式來觀圖。
以下顯示此免費程式的使用說明: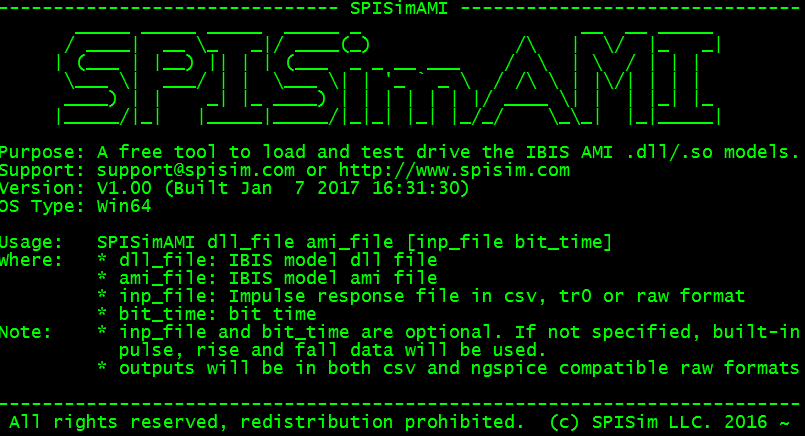
舉例而言, 吾人可能拿到了一個TX的AMI模型且被告知其等化(EQ)的位準, 則就可以簡單的利用一串的脈波信號透過此程式輸入並查驗其輸出以確認所提供資訊無誤。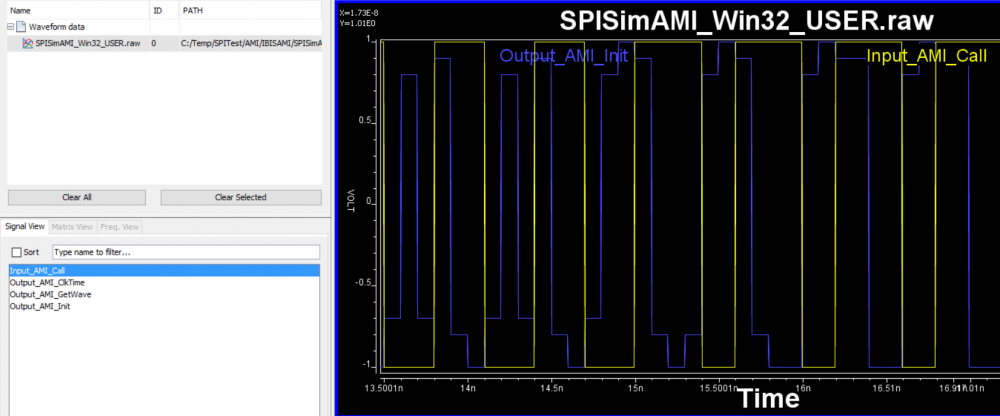
不論用戶所用的軟體及程序為何, 我們要強調的是AMI用戶對AMI模型就如其它的系統模型(IBIS, S-parameter, RLGC model)一樣, 在進行全分析前都應先進行初步的確認, 而這也應列入SI分析標準程序SOP裡的一個步驟。
以AMI建模人員的角色言:
之前提及AMI建模人員需要有跨更多領域的相關知識及經驗。比如說他/她先要知道AMI模型是什麼、格式有那些、運作模式有那兩種等等(關係到AMI_GetWave的有無), 其次要能將SERDES的相關運作及設計以C/C++的語法合乎AMI API的格式來寫出, 當然程式的相關規範如OO(物件導向)及效能也都要考量到。再來這些程式要用編譯器如Visual Studio或gcc/g++等編譯成.dll/.so的格式;這中間的過程當然也包換了數位信號處理DSP的相關技巧如低通濾波器及傅利葉轉換等等。最後, 所建模出來的模型架構應是可輕易維護且延伸性佳。這是因為同一公司不同SERDES間或不同設計版本間的相似性常是很高的, 所以好的設計可避免每次都重起爐灶重頭來過。凡此種種考量可了解對身為一位AMI建模者而言要了解及學習的知識實在很多。也因此就不難想見AMI建模要不就得花大錢外包或得有專職的工程師負責才能確保模型品質及長久的維護。

以資訊人員的想法從下而上的建模例子
在分工甚細的情況下,幾家EDA公司也就為此順勢推出了AMI建模的解決方案,其大都功能強大且各有風騷。它們的強處都在於這兩者在AMI流行之都早已是系統設計裡從上而下(top-down)流程的首選…尤其是在RF設計上, 所以也早就有很多的Library可供選擇使用。再者, 它們也早都有將流程轉成C/C++語法的外掛, 所以只再加一步..將轉出的源碼配合AMI API的要求即是水到渠成。然而, 就如我們下篇會再探討一般,我們也相信一個AMI建模者不應全然使用這些軟體就直接釋出模型給用戶。因為問題可能在模型釋出後才開始發生…試看這些軟體所轉出來的C/C++源碼:
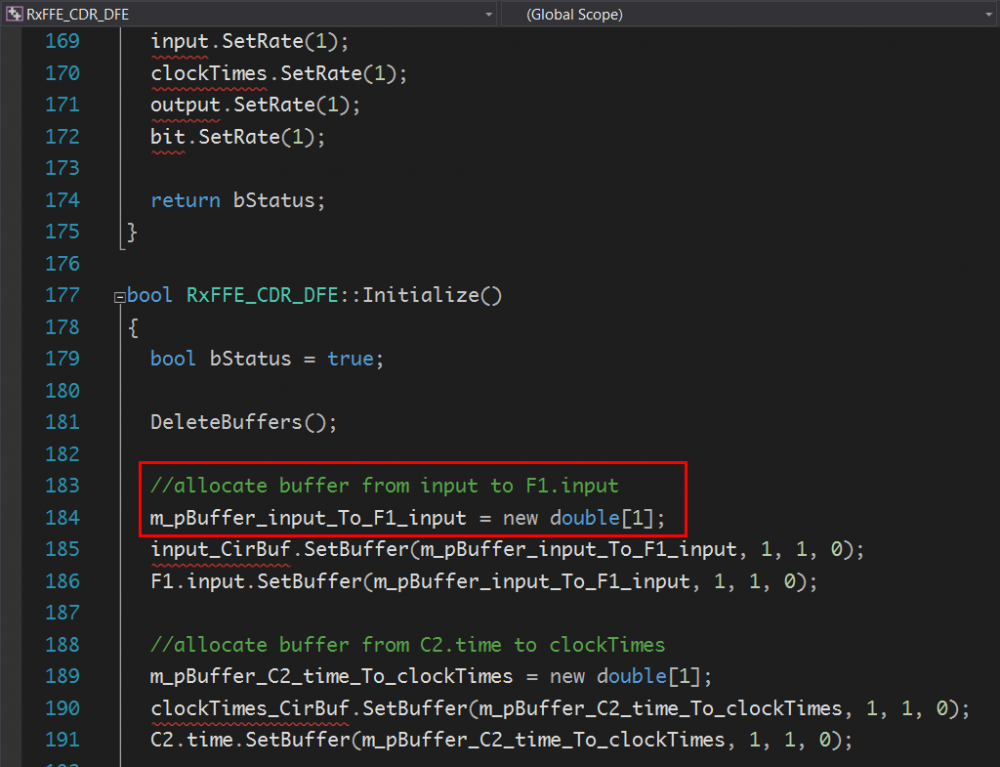
SystemVue常用長度為1的buffer..
隨便把這給一個軟體工程師看他/她可能頭上都會有三條線, 軟體直接轉出的碼不僅維護不易而且也跑不快。至少以上圖所示.. 重覆地new/delete長度為1的buffer大概就足以讓專職軟體人員丟掉工作。就更不用提到什麼延伸性的的考量了。
如前所述, 其實在一個公司內的SERDES設計或不同版本之間其實差異不會太大, 再者一個SERDES裡所常用的功能區塊也大概就是那麼幾種, 則如為長久考量, 一AMI建模者實在是應該下基本功(Bite the bullet)一步一步地把模型架構建起來, 若設計得當的話很多的模組其實重覆使用性都很高。最後,一旦對架構有第一手(而非透過其它軟體)的掌控後就能加上一些其它”特異功能”, 比如說對部份設定加以加密, 容許特定用戶使用不同的模型設定等等, 而所設計出的模型也可參數化並有特定的GUI以便設計組態,甚至是只要編譯一次的AMI檔案而可將所有其它的設定透過.AMI檔案來做功能上的切換。凡此種種考量一旦建製完成,都可視為公司一IP及無形的資產。
最後值得一提的是在建模過程中將無可避免的需用編譯器來對開發中的模型進行除錯及測試, 則上述的SPISimAMI程式也可在此時派上用場。AMI模型是.dll/.so檔而無法直接執行,再者不論是仿真器或如SPISimAMI, AMICheck這類的驅動程式都需負責讀入並解析.ami檔案以便將相關參數再傳入給模型本身。所以若無這種輕巧的驅動程式的話,建模人員就得利用全仿真器(且得佔一個License)才能對手上的AMI模型讀入驅動且除錯。
以發佈AMI模型的公司角色言:
對一發佈AMI模型的公司,其所釋出的模型不僅代表產品的原有矽智財,其對此模型的效能報告及支援也間接影響公司的聲譽;一般在有AMI模型後最常見的問題是:用戶所用的仿真器或軟體和公司內部所用的不同, 則結果跑出來可能也就不一樣或甚至有錯,那要如何才能迅速有效地對這模型提供支援呢?
如果到各大有釋出AMI軟體的大公司相關網頁看(比如Xilinx), 都可發現他們都強調結果是在某特定軟體上測試, 言下之意,用戶若使用不同軟體則後果自負!?
我們認為模型發佈者及使用者之間的共同立足點(以交換資料)應是以最簡易形式為之, 這樣子就沒有在模型及使用工具上對問題互踢皮球的可能;舉例而言, 用戶可將模型輸入及輸出端的波形轉出來,再加上使用的參數檔.ami,應就足以做為提供給模型發佈商的測試資料(Test Case)供除錯用。關於這個應用,除了之前所提及SPISimAMI之類的驅動程式可供使用外, 可再配合如Proxy class等的設計(下下篇貼文會探討)就可使輸入輸出至某一AMI模型的資料達到透明化的結果,而這也就利於供應商對這模型的支援及維護。