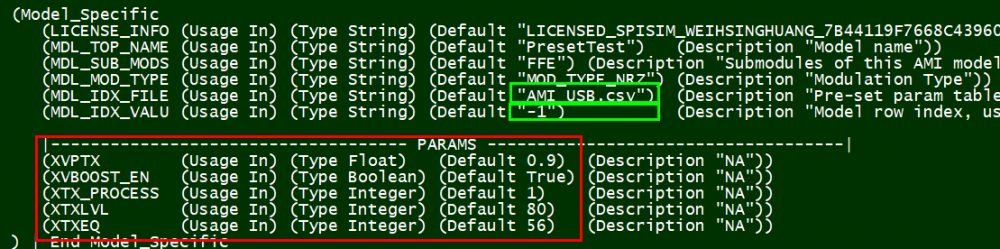
[這篇貼文系為2019 DesignCon IBIS Summit發表的同標題文章做準備, 相關簡報檔及現場錄音(英文)已連結於此文之末。]又:此研究是由本司分在美國及東京的兩位顧問共同準備。
研究動機:
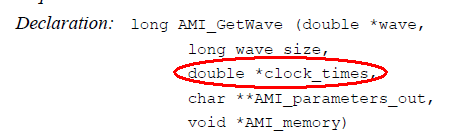
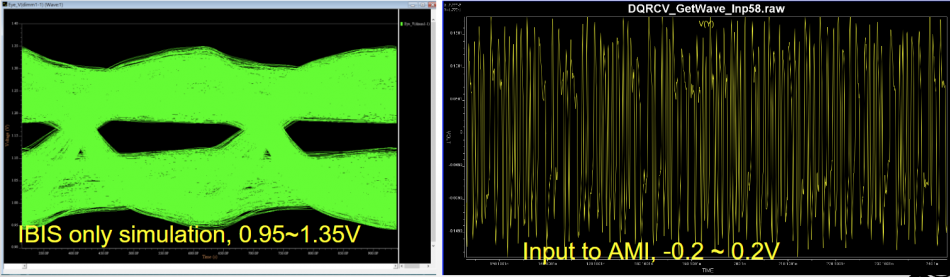
IBIS委員會下有一個工作小組(ATM: Advanced Technology Modeling)在美國這邊每週二中午開會; 若是有空話我都會儘量與會以了解最新的建模趨勢及資訊。自2018年中開始, DDR5於AMI上運用的課題便成為會議討論的焦點。主因在於現今的AMI參考流程係以差分訊號或SERDES為主;舉例來說, SPEC裡談到傳入AMI_GetWave的訊號是由正負0.5間所驅動, 而儘用單一的impulse response來執行AMI_Init似也象徵著Rise time (Rt)及Fall time (Ft)是相同的。現有的AMI流程是否能大致原封不動地套到DDR的單端信號如DQ上便引起了熱烈的討論; 與會的不同EDA廠家對此都有不同的看法, 有些認為問題不大可直接套用, 另有些則認為這裡有根本上的問題而非得砍掉重練不足以應用於DDR5之上。IBIS 規格若要改變向來不是那麼簡單的…覺得規格有不足之處的廠家得以buffer issue resolution document (BIRD)的書面文件表達意見及想倡議的改變; 但如此做則不免要揭露本身的商業秘密或是自曝其短, 所以時至今日並未有如此的倡議產生。對於一建模服務為主的本司而言, 則不免好奇而想像倒底一仿真器能在何種情況下不變現有流程而能直接支援DDR5? 這篇論文便是想出這樣的”一種可能”是如何運作; 實際上大EDA廠可能早已有思慮更稹密的設計而比此處所倡議的更週到,但這麼”一種可能”的存在便應足以取信建模者不需再等待規格的改變而可開始構思DDR的AMI應如何的被建構。
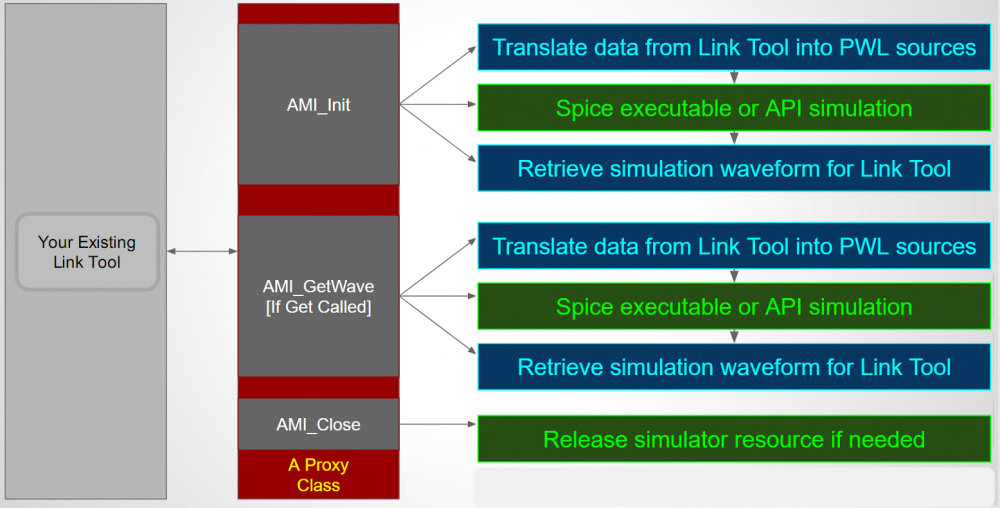
AMI_Init:
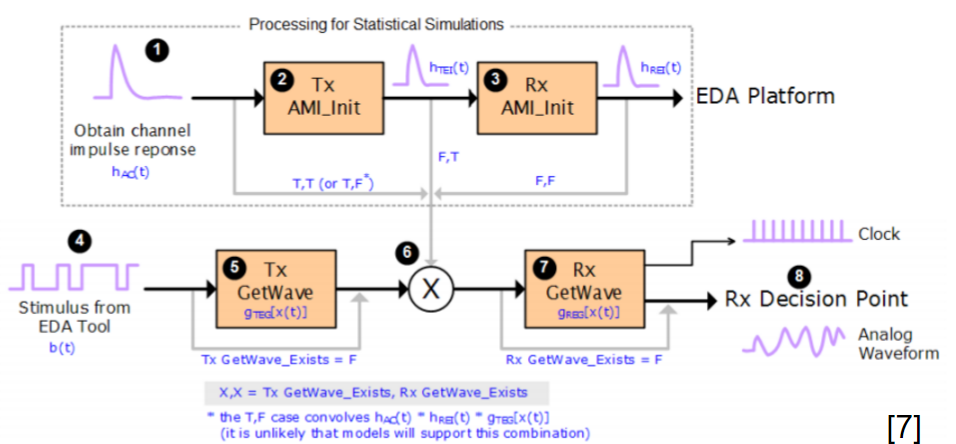
通道分析一般有兩種方法: “Statistical” 及 “Bit-by-bit”; 不論是採用何種方法, 流程一開始之初便是仿真器對含類比前端(及IBIS BUFFER)在內的channel進行”calibration/characterization”(以下紅框內所示)。目的是要取得這中間LTI channel部份的突波響應 (impulse response)。對於一SERDES其RT/FT為稱而言, 如此取得在”calibrate”之後的突波便會依序先傳給TX EQ而後再傳給RX EQ, 最終的結果回到仿真器去依機率統計來計算probability density function (PDF), 積分而得 cumulative density function (CDF),再來畫出如浴盆曲線等等的結果。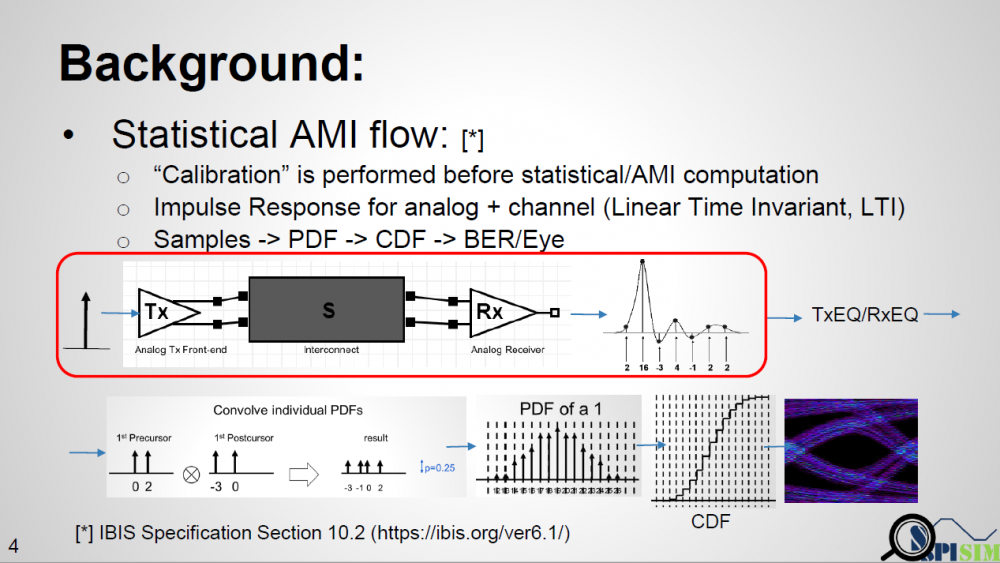
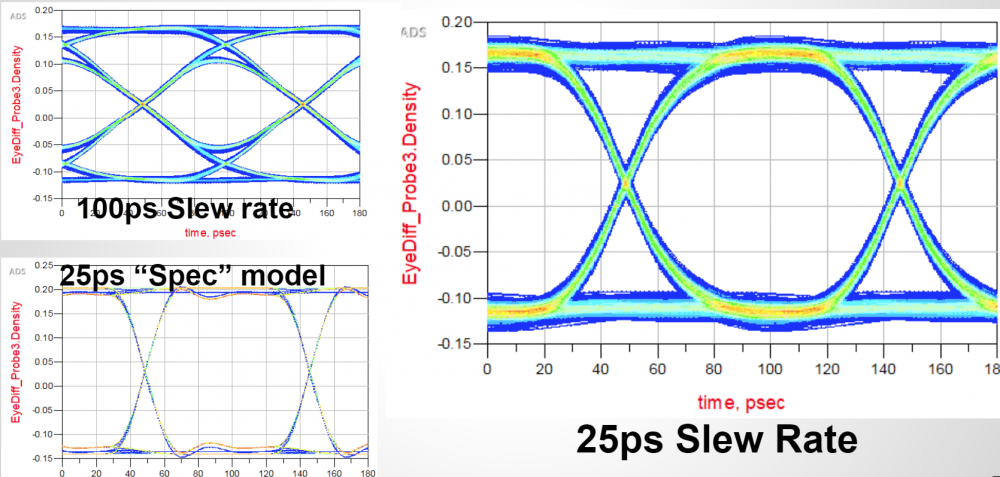
教科書裡對於突波響應的定義是在無限短的時間內輸入信號由0至1回到0所造成的響應。在實際上, 仿真流程裡最小的時間單位是一個時步, 而含有類比BUFFER的部份是沒有在同一時步內做兩次的信號變換的。所以一般的作法都是改用階波響應而後再加以做一階微分而得到突波。對於一Rt/Ft不同的情況而言,其上升及下降階波並不相同, 也就是說, 如此得到的突波會有兩種形式, 則如果流程不變, 是要把那個突波送進模型裡了?這裡要先提的一點是:暨然是由仿真器對channel來仿真以得到calibrate的波形, 則其可自由地去”probe”不同的節點而有任何它想要知道的資訊。
Asymmetric Rt/Ft: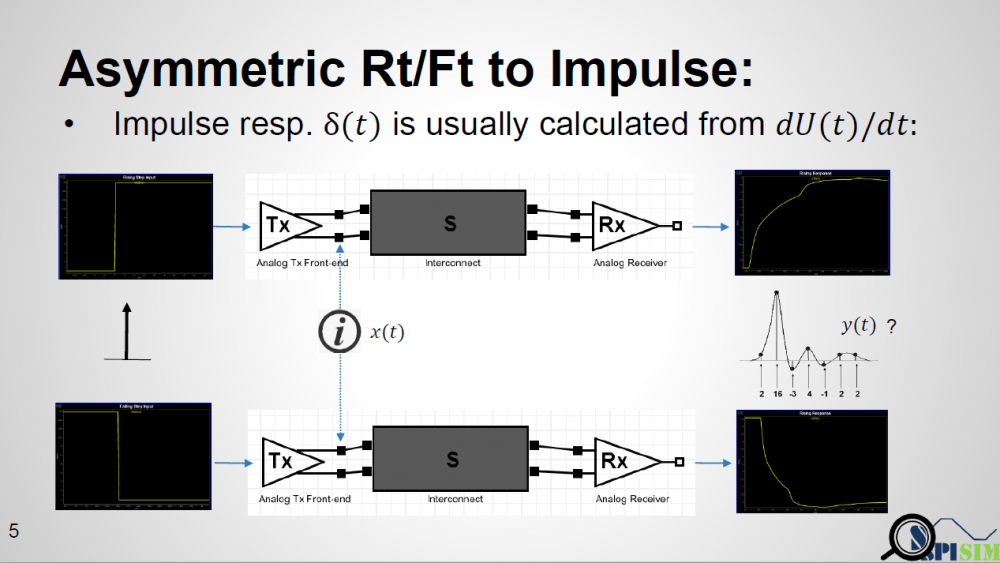
有的人可能會想:規格裡沒有規定AMI模型在流程裡只可被叫一次, 也就是說理論上而言,仿真器可跑連續兩次流程: 第一次用上升沿算出的突波、第二次再用下降沿算出的突波..分別來運用。如此做不但要花兩倍的時間, 主要的是若在同一個process裡, 一個.dll等的模型被叫兩次..也就是先被叫AMI_Close後又AMI_Init的話,則取決於模型的編程, 很可能會有穩定度的問題。比如說如果第一次叫AMI_Close時記憶體沒清好, 則第二次AMI_Init的呼叫就未必會得到和第一次叫時同樣的結果,如此一來等於仿真器的穩定性就不能保證了。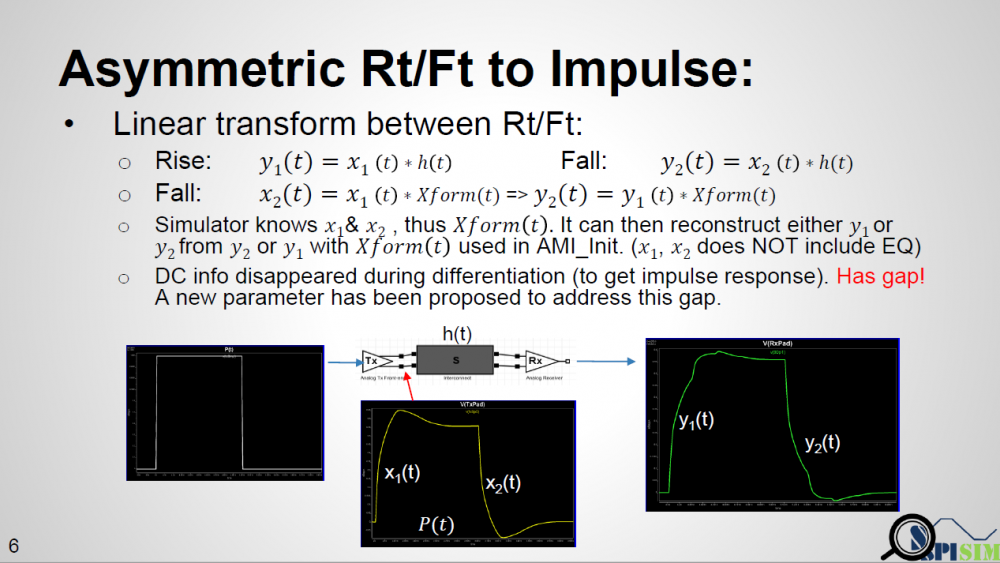
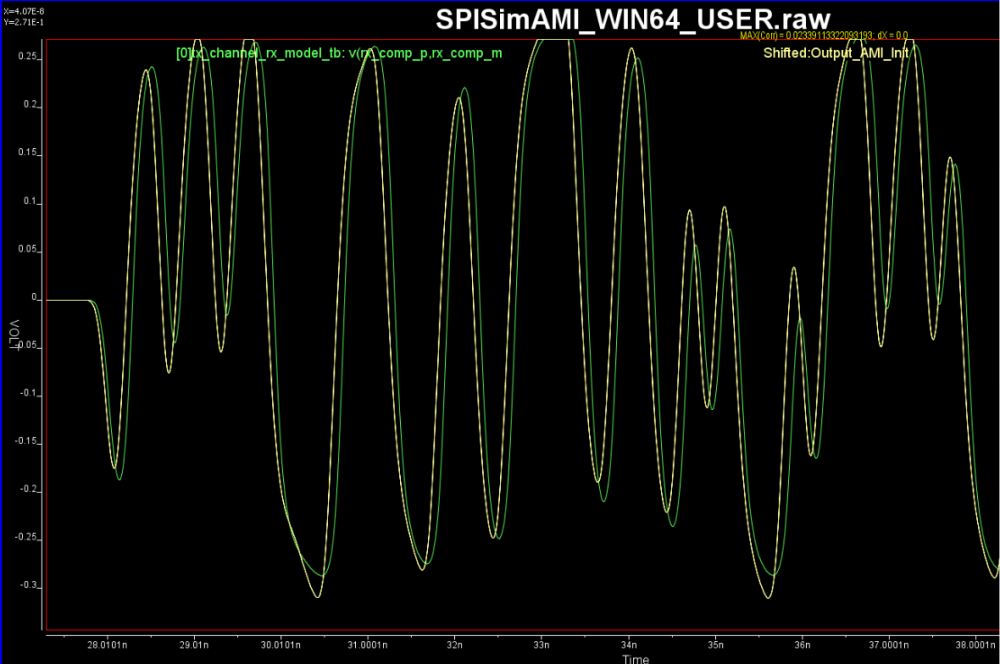
如上所示, 如果仿真器在Calibrate的時候用的是一個UI很大的方波, 則其響應同時會有上升及下降階波的部份。如果說在這過程中, 仿真器同時去probe TX analog buffer PAD端的話, 上升及下降時對channel的輸入是X1(t)及X2(t), 而其在RX PAD端的響應是Y1(t)及Y2(t), 因為吾人可以導出一轉移函式Xform(t)其在兩輸入信號X1(t), X2(t)之間做轉換,而整個interconnect又是LTI的, 所以Y1(t)及Y2(t)之間存在的也應就是同樣的轉移函式。也就是說, 不論仿真器傳進AMI模型裡的是由上升或下降沿所得的突波, 因其有Xform(t)的資訊, 兩種都Y1(t)及Y2(t)都可在最後透過轉換而取得, 也就是說:一仿真器可透過現有的AMI流程而得到兩個不同的響應。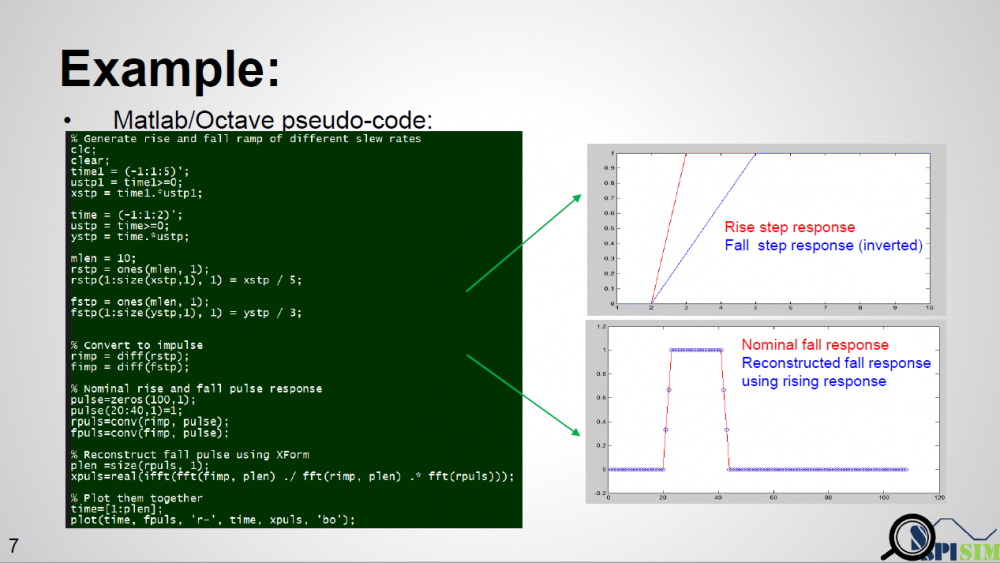
依據這個想法我們寫了一個簡單的matlab script, 其將不同的輸入訊號inp1 及inp2 之間的轉移函式Xform(t)算了出來, 而後把由當輸入為inp2時的實際輸出out2各由輸入為inp1時透過Xform(t)所重建的理想inp2的輸出out2’來比較, 其可完整的重合在一起, 也就是說驗證了這個理論的可行性。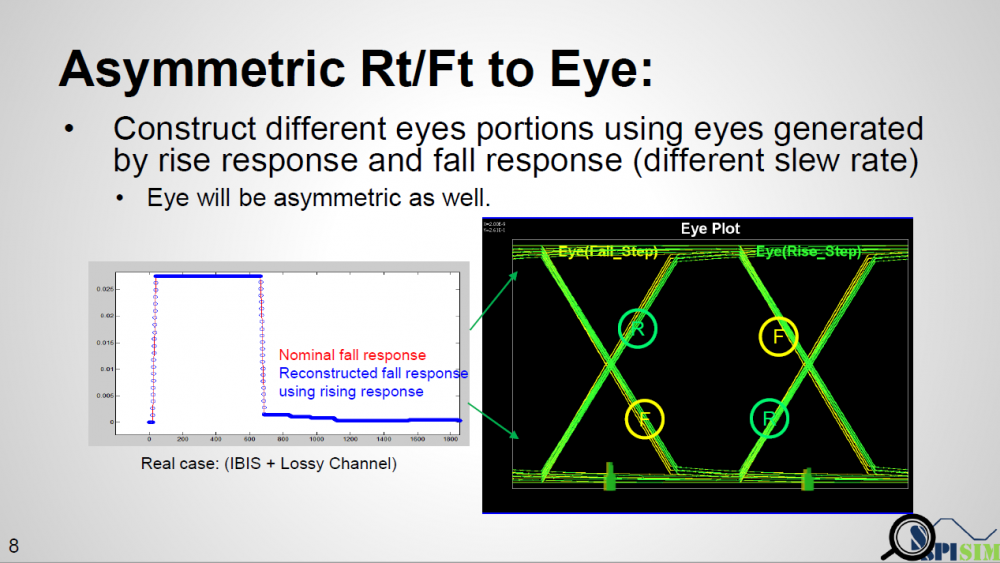
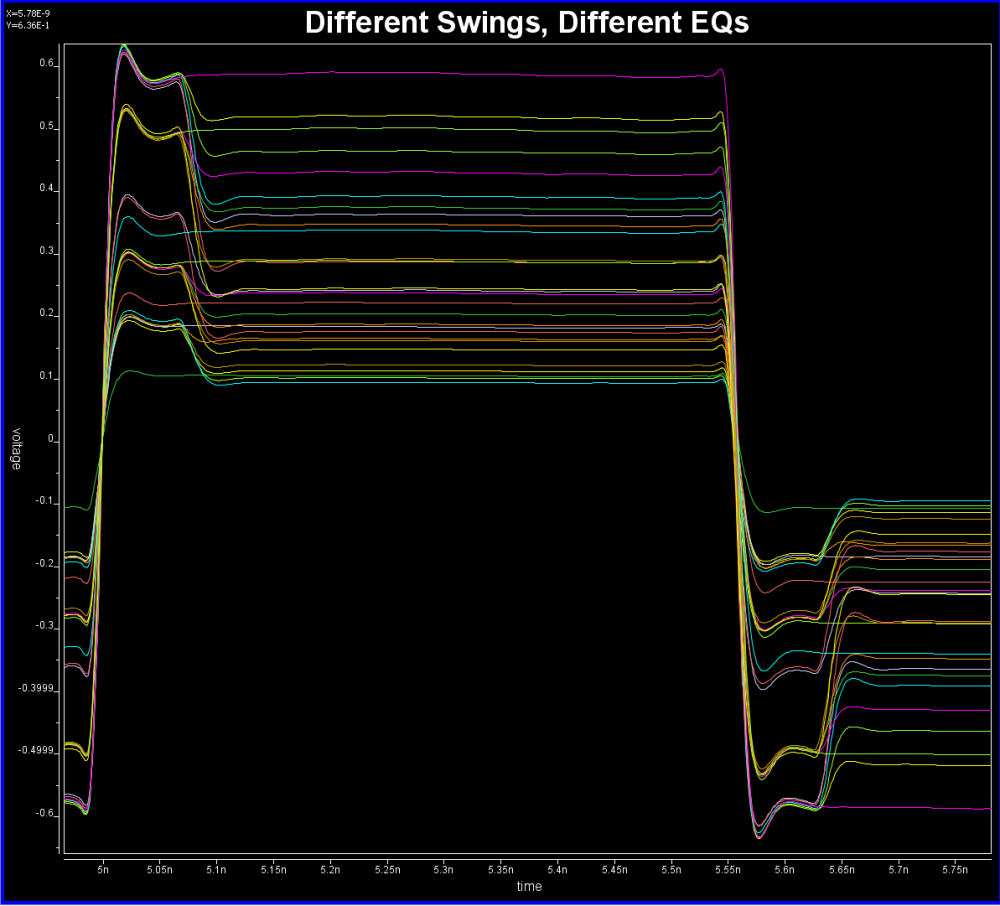
而一旦我們有分自兩個不同斜率所得的完整響應之後,就分別去建構出兩個不同的眼圖, 再把兩眼圖中分屬於上升沿及下降沿的部份抓出來合成一個眼圖…這就是在非對稱Rt/Ft之下應得的眼圖, 其與SERDES的應會不同…即應會顯示非對稱性。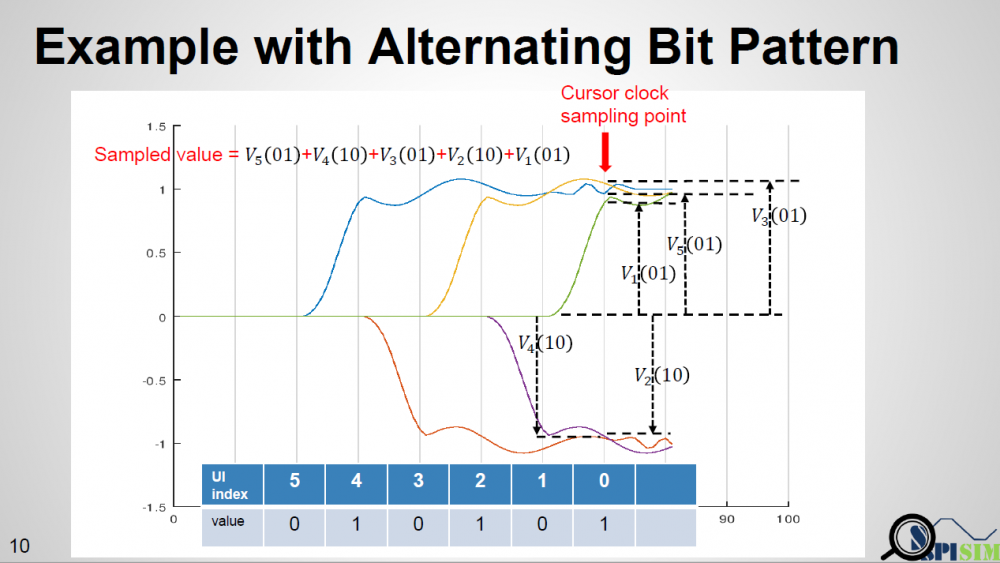
其次, 對於不同Rt/Ft在PDF的計算上也有點不同, 因其必需考慮到之前位元的值為何而不是在不同位元間相互獨立。比如說在算SERDES的PDF時, 若不考慮到編碼(如8b10b)的話, 每一個位元出現0和1的機率各為50%, 也就是因此吾人能透過不同位元間pdf的相互convolve而得到最終的pdf; 但Rt/Ft不同時,我們要分別就上升沿和下降沿的階波做考量, 如果是cursor用的是上升沿的話, 表示這個位元現值為1且前值(cursor – 1)為0, 同樣的, cursor-2分有0 和1 兩種可能, 若其為1, 則在cursor-1所形成的下降沿波尾部份會和現cursor的部份做重合, 凡此種種, 意即一個仿真器得事先決定要追踪的位元深度,而後就此深度內每一個0或一的可能做如樹狀的記錄, 最後再把這記錄內不同時間點上升沿或下降沿的部份去在cursor的那點做疊加而得到最終波形, 這些工作自不簡單, 但全是仿真器裡可做而與AMI模型無涉的。
AMI_GetWave:
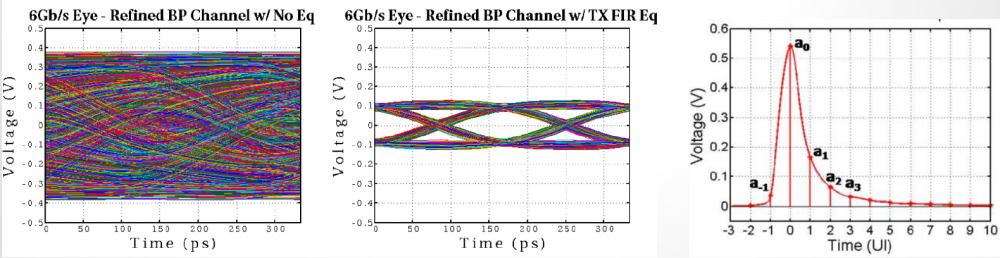
根據SPEC建議的標準流程:在bit-by-bit模式中, 數位位元列傳給TX AMI後, EQ過的TX信號由仿真器和Channel的突波做Convolution再把這信號傳給RX AMI 做末端的EQ, 這期間,不論是TX EQ 或是RX EQ都有可能不是LTI地等化信號, 所以之前倡議的Xform(t)轉移函式在此並不適用。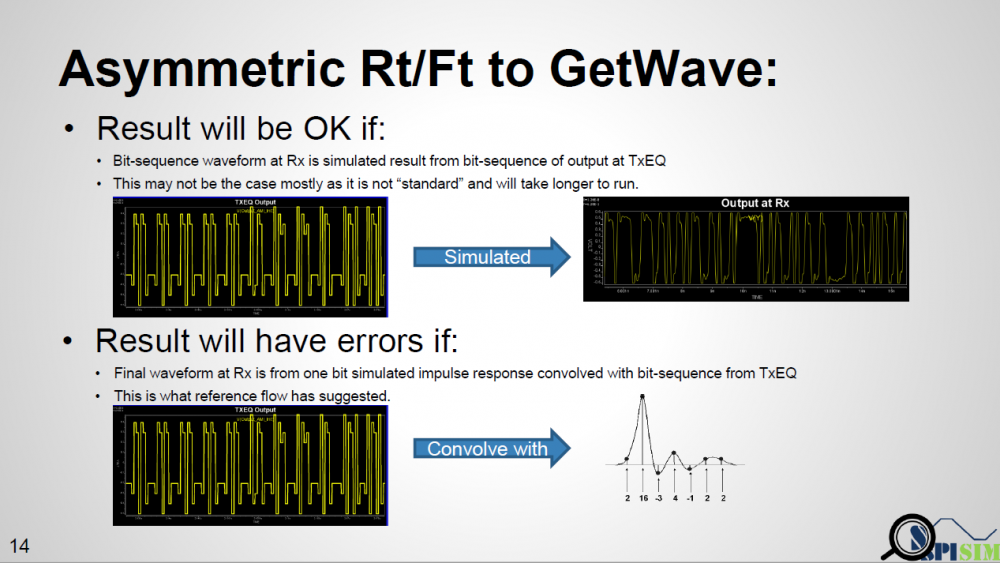
假設先這樣想: SPEC裡只規定仿真器在此處理的是TX EQ出來及輸入到RX EQ前的信號, 而其方式是與Channel的突波做convolution, 那是否有這建議以外的做法又不動到標準流程呢?
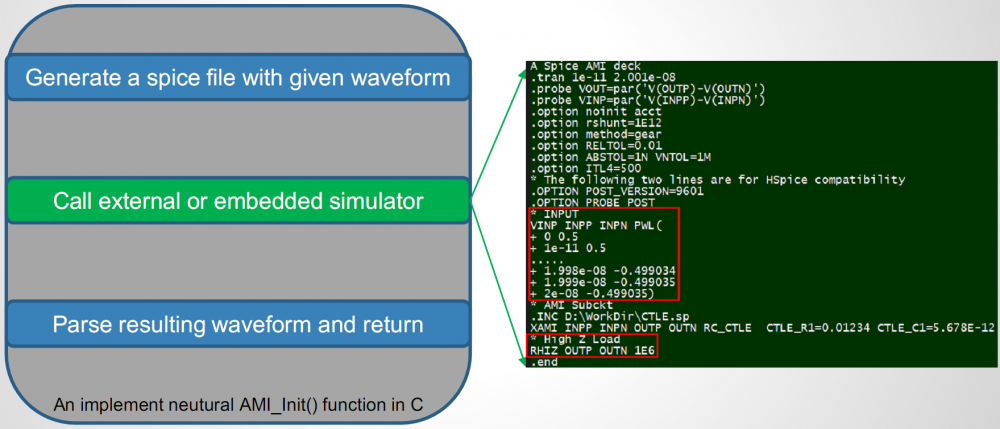
如此的一個例子如上圖上半部:假設仿真器並不是用convolve的方式, 而是把那TX EQ出來的信號透過傳統transient simulation的方式來得到在channel末端的波形, 那所有因不同Rt/Ft所造成的影響也就自動包含在裡面而不需要去做額外處理了;但這樣的做法不僅慢(因為要跑傳統時域分析), 且也和規格建議的做法甚為不同, 所以我懷疑真有仿真器是如此運作。
另一種可能是先把TX EQ的輸出和一個UI的數位信號做de-convolve, 把這UI的方波算在channel的頭上而用仿真器去把channel 對這方波的響應算出來, 這樣一來Rt/Ft的不同儘在這方波裡, 而因為只有一個方波…在做最後Convolve時應會快得多, 那這樣做是否就可解決問題了呢?
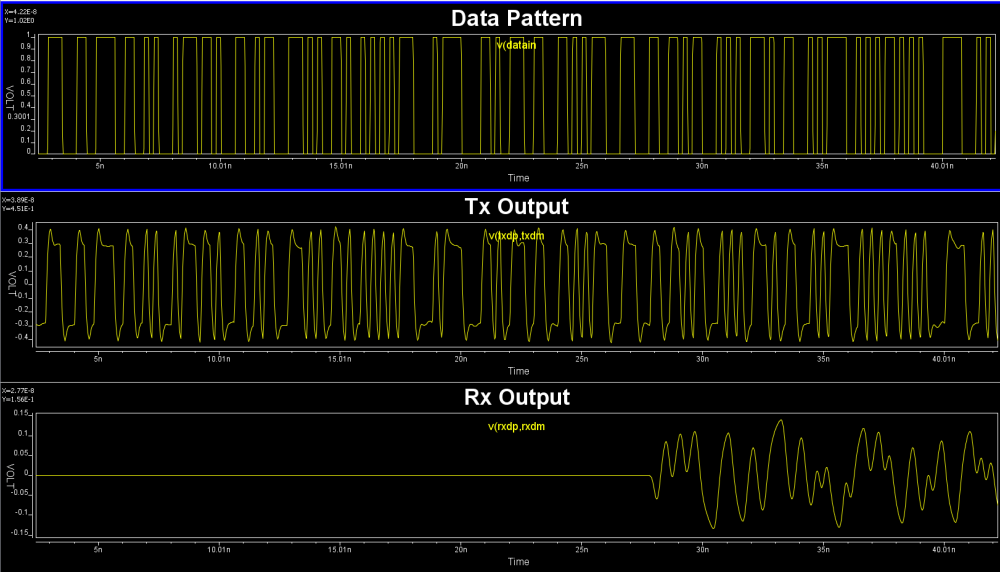
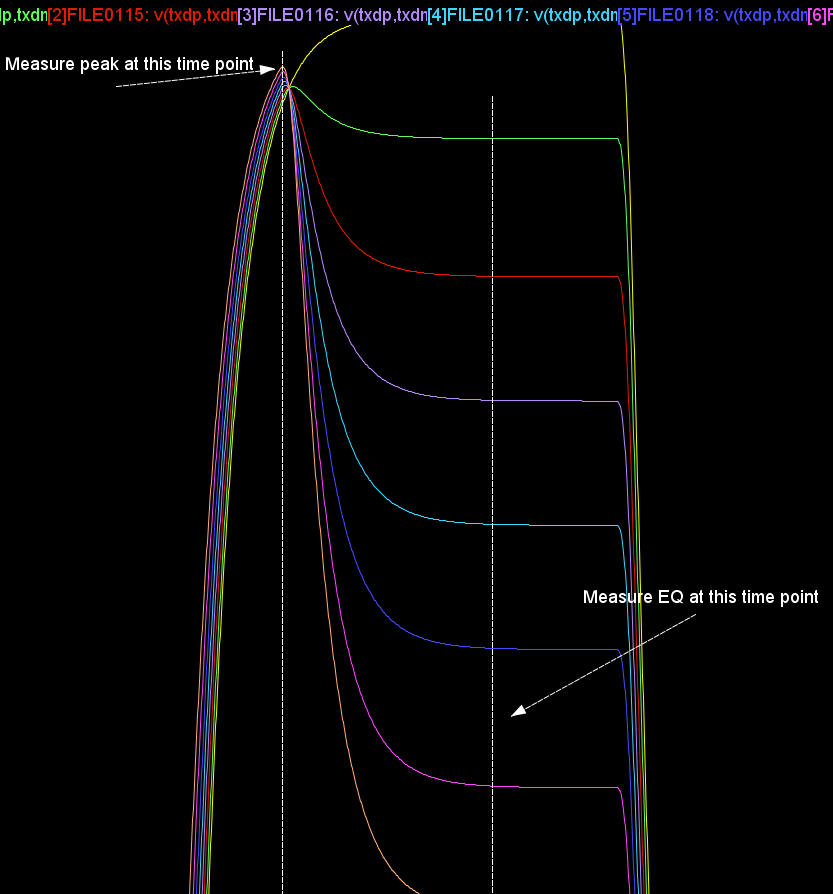
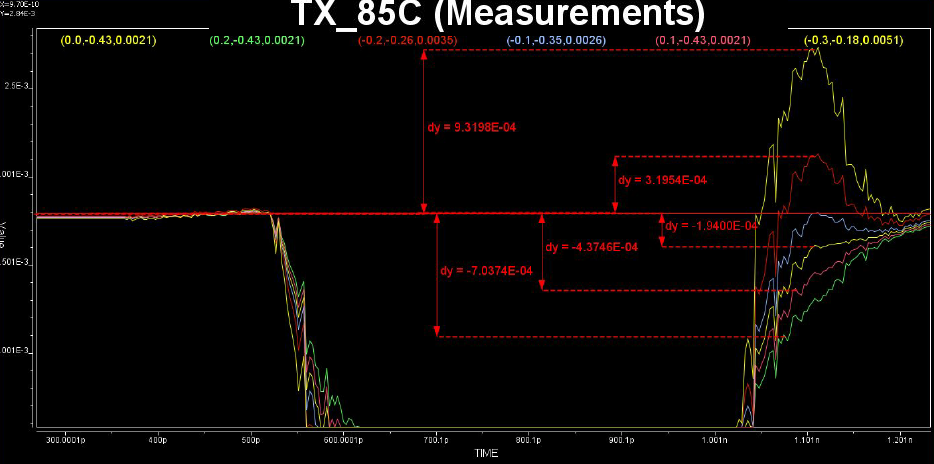
實則未然…如上圖所示, 當我們用Rt/Ft不同的方波透過Convolve的方式去合成不同位元的信號波形時, 會造成一些”glitch”,這是因為利用疊加的方法並不能把Rt+Ft變成一個平線, 也就是說若有連續同樣的位元信號如01111或10000時, 用方波Convolve形成的合成波形在都是1或都是0的尾端不會有一static state. 其glitch的程度取決於Rt和Ft有多不同, 也就是說, 在這種情況下, 應用Rise或Fall 的階波去算才能得到理想的效果(接下來細節仍很多, 不再往下探討)
結語:
在這篇文章中, 我們討論了若要將現有IBIS Spec裡的reference flow (參考流程)直接套用到有不同Rt/Ft的如DDR的信號時, 仿真器可能有的做法。結論是這是可行的…但仿真器裡得有更多複雜的計算方法以將不同會造成誤差的可能都能考慮進去。當channel analysis係以”statistical”模式進行時, 因為EDA軟體在characterization/calibration的過程中可對任一設計上的節點做量測, 所以其可以有任何想要的資訊, 其中可利用的是在類比TX及RX PAD上的瞬態波形, 透過上升沿及下降沿的波形, 仿真器可預算出一轉移函式, 這函式因整個流程是LTI的關係而也可套用到接收端的信號而使得不論當初AMI_Init時送進的是什麼(上升或下降)沿的算出的突波, 都能將其結果在事後在相互間轉換, 從而兩種資料以合成出不對稱的眼圖, 其間也要做的包括了用如樹狀的追索以對不同cursor處的不同位元做考量…而不是如二項式分佈般每位元間相互獨立。在bit-by-bit流程中, 因為參考流程的限制較多…中間的計算需以channel的突波以convolve方式為之, 而又因非LTI的關係使得不能透過一線性函式相互轉換, 故而仿真器得另闢磎徑…其最終可能得用上升及下降沿的波形(而非突波)來做計算,否則在不同Rt/Ft的情形下, 在原本應是steady state的地方會有glitch的現象…而其大小取決於Rt/Ft間相異的程度。
相關連結:
簡報檔: [請按這] http://www.spisim.com/support/paperetc/20180202_DesignConSummit_SPISim.pdf
現場錄音(英文): [請按這]

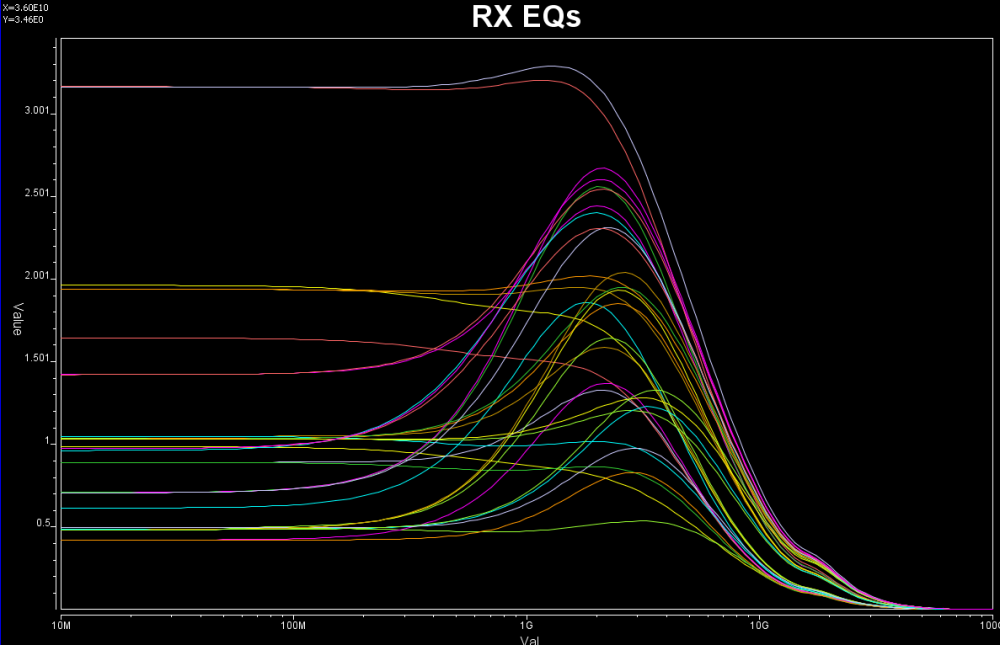
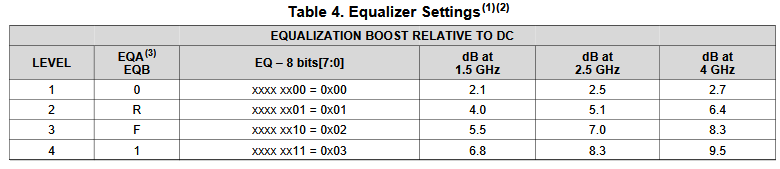


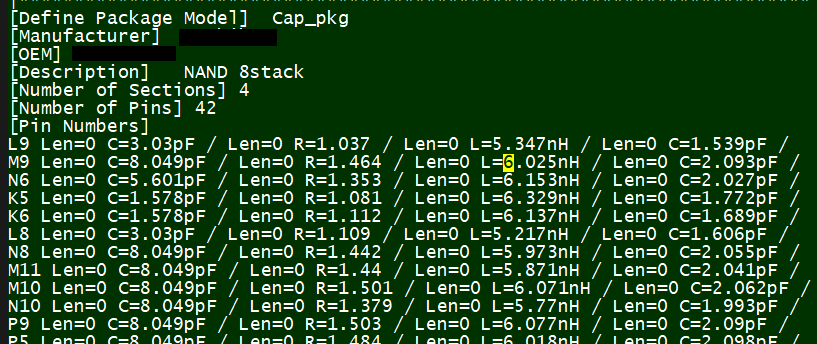
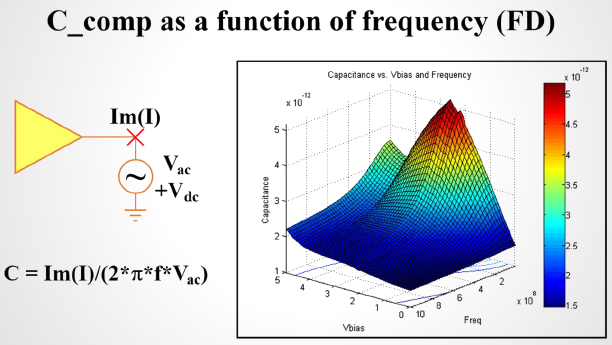

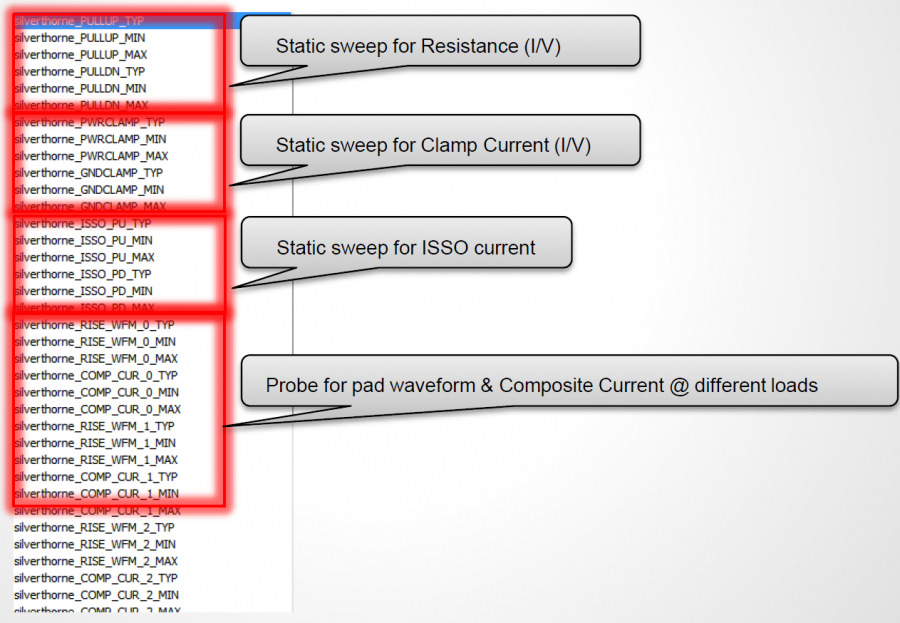
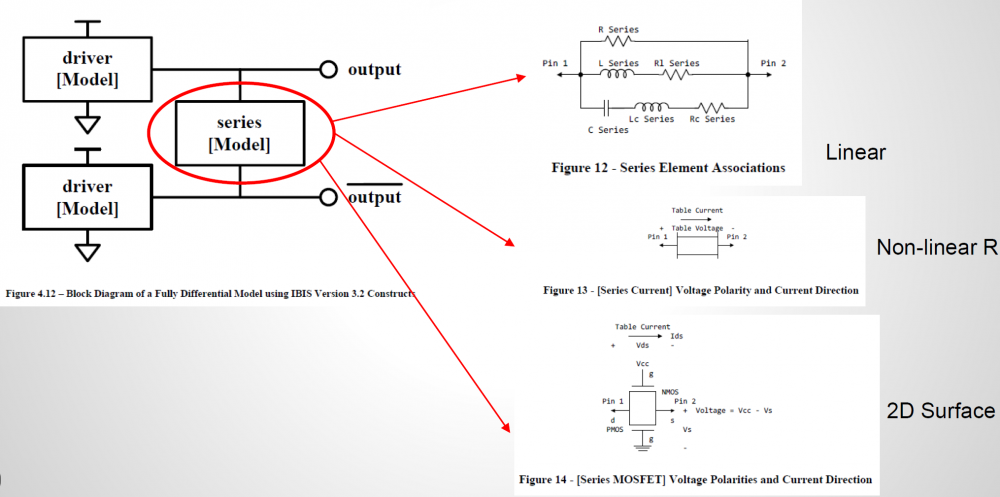
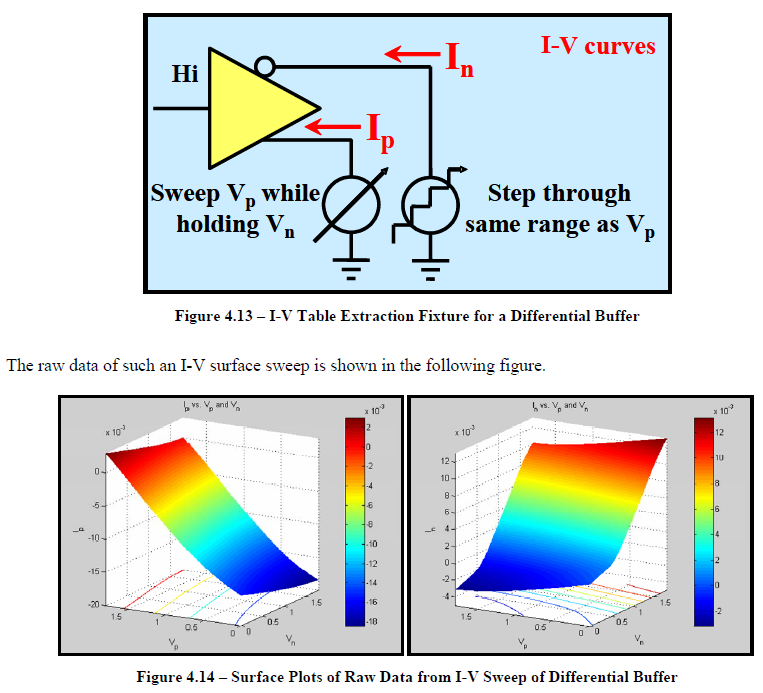
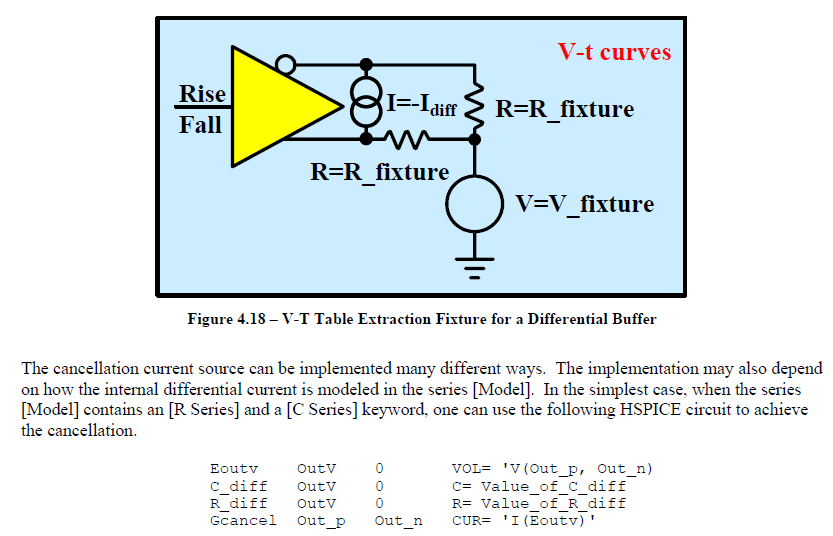
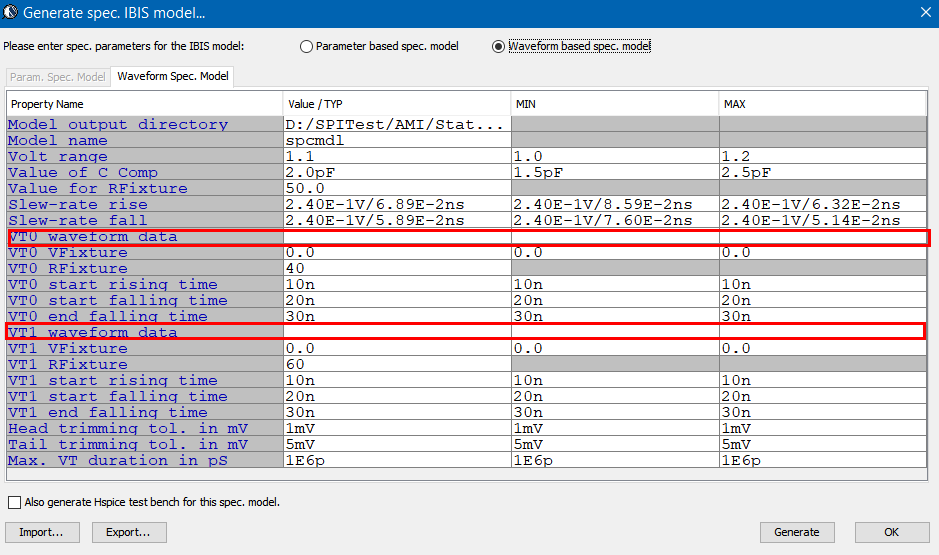
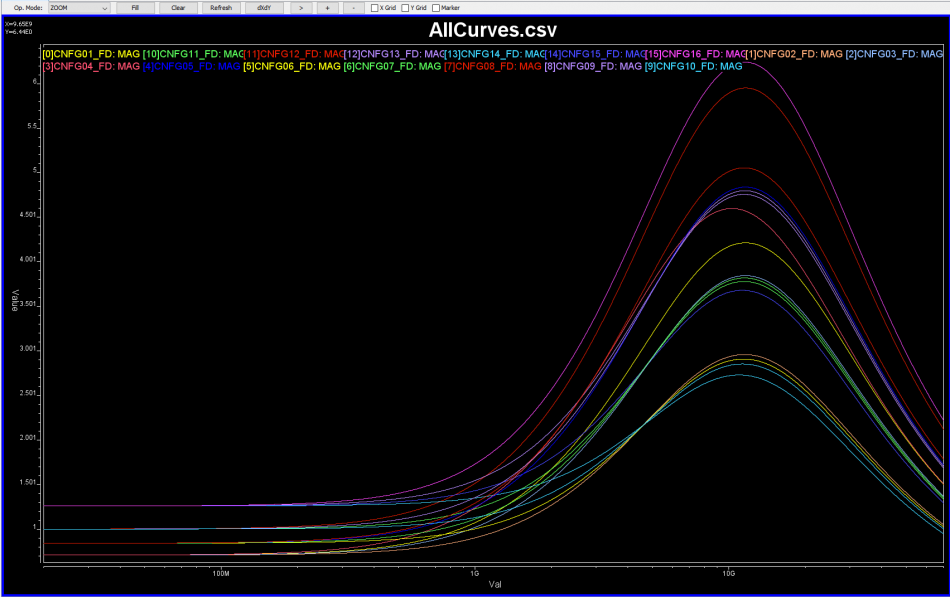
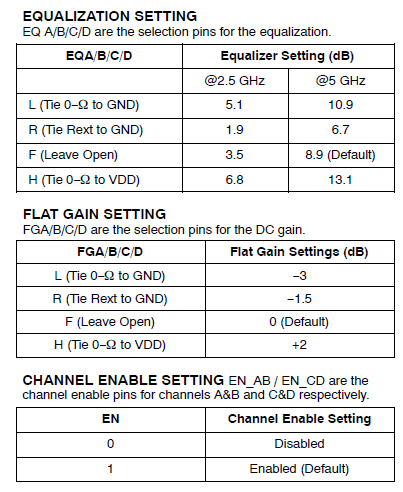
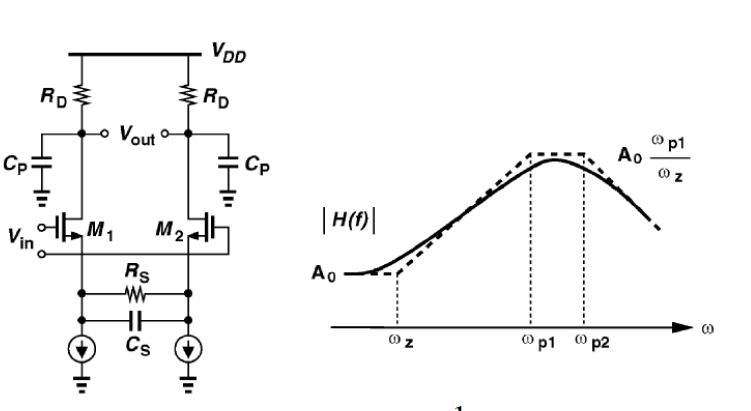 比如說如果我們手上所有的資料只是待建模型的資料表(data sheet),則首先可以從上面找出關鍵頻率必需要有的放大程度
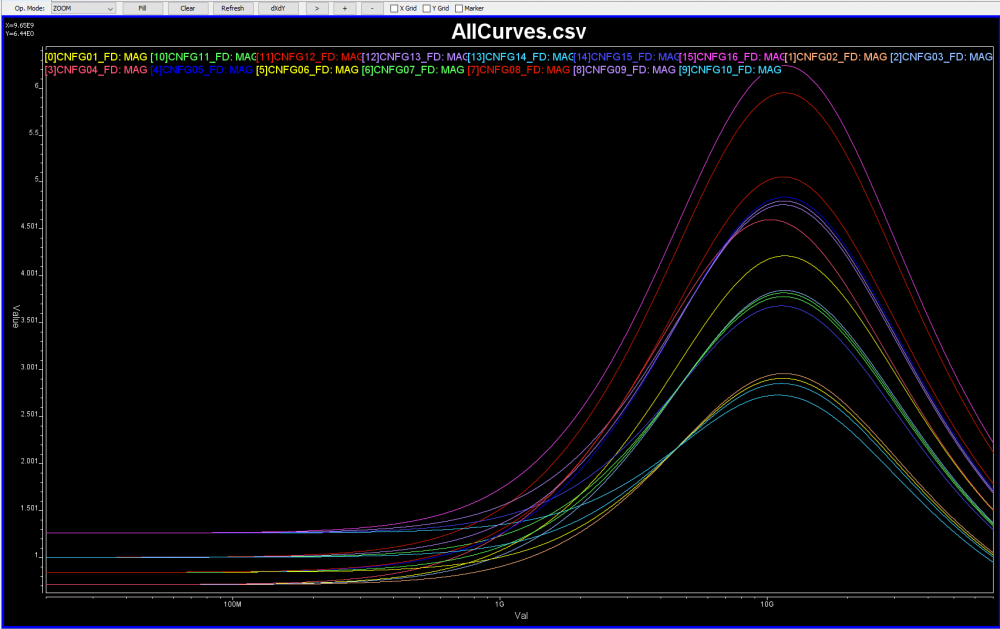
比如說如果我們手上所有的資料只是待建模型的資料表(data sheet),則首先可以從上面找出關鍵頻率必需要有的放大程度 上圖的例子是USB3.1, 所以關鍵頻率是和其運作主頻相關的諧波;當對不同數目、位置及DC放大性做掃描之後, 我們就可以很容易地找到幾組符合此data sheet spec的頻率響應:
上圖的例子是USB3.1, 所以關鍵頻率是和其運作主頻相關的諧波;當對不同數目、位置及DC放大性做掃描之後, 我們就可以很容易地找到幾組符合此data sheet spec的頻率響應: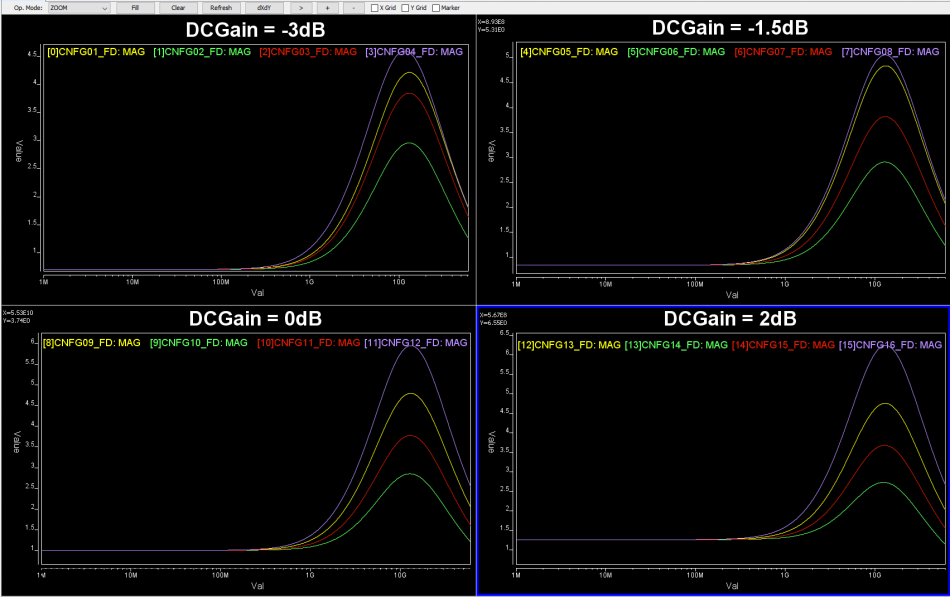 也因為這些曲線係由預訂的線性函式(由那些極零點所組成)所產出, 所以一則為相對穩定、高品質而不會有passive/causality上的問題,再者也從0Hz 到極高頻皆唾手可得。
也因為這些曲線係由預訂的線性函式(由那些極零點所組成)所產出, 所以一則為相對穩定、高品質而不會有passive/causality上的問題,再者也從0Hz 到極高頻皆唾手可得。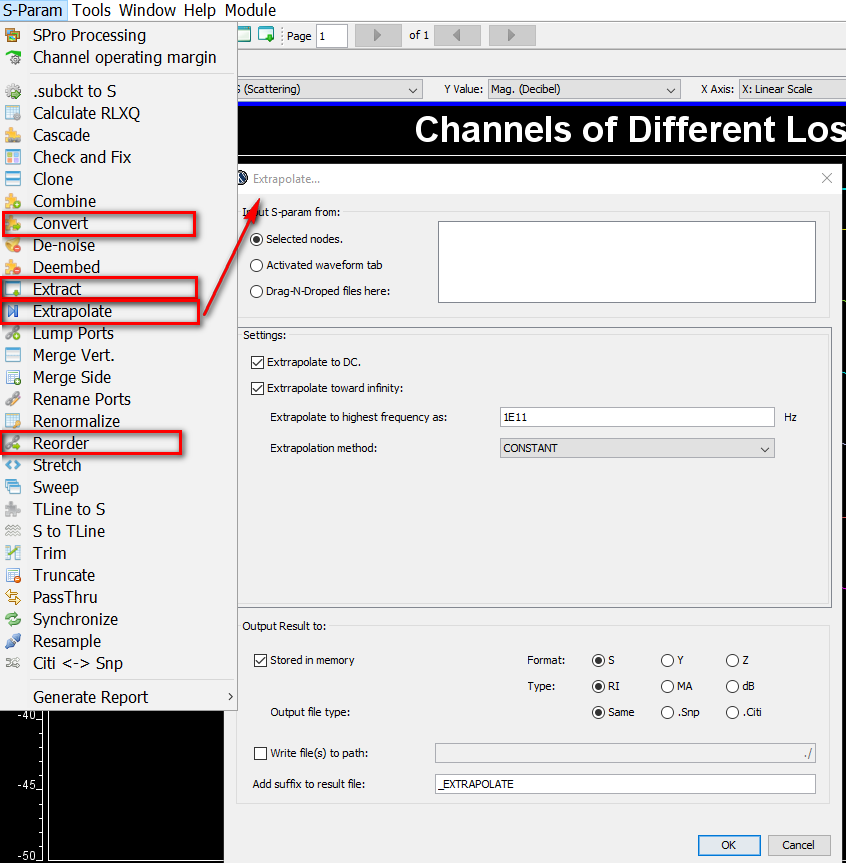 首先手上的S參數可能是單端點(single ended)且適於某種port ordering的 (如1->3, 2->4), 則先要做port reordering 至1, 2->3, 4, 而後用generalized 2-N port 做differential mode/mixed mode 轉換,而後外插到DC及夠高的頻率(由VNA等所得的頻率通常只有10或20GB…這是遠遠不夠的), 在外插的過程中所有的計算均需使得這個S參數仍能保持適當的物理性(如causal), 最後再把只適用於differential input->differential-output的那個部份從S參數裡extract出來成單一一條頻響曲線(含magnitude及phase)。
首先手上的S參數可能是單端點(single ended)且適於某種port ordering的 (如1->3, 2->4), 則先要做port reordering 至1, 2->3, 4, 而後用generalized 2-N port 做differential mode/mixed mode 轉換,而後外插到DC及夠高的頻率(由VNA等所得的頻率通常只有10或20GB…這是遠遠不夠的), 在外插的過程中所有的計算均需使得這個S參數仍能保持適當的物理性(如causal), 最後再把只適用於differential input->differential-output的那個部份從S參數裡extract出來成單一一條頻響曲線(含magnitude及phase)。

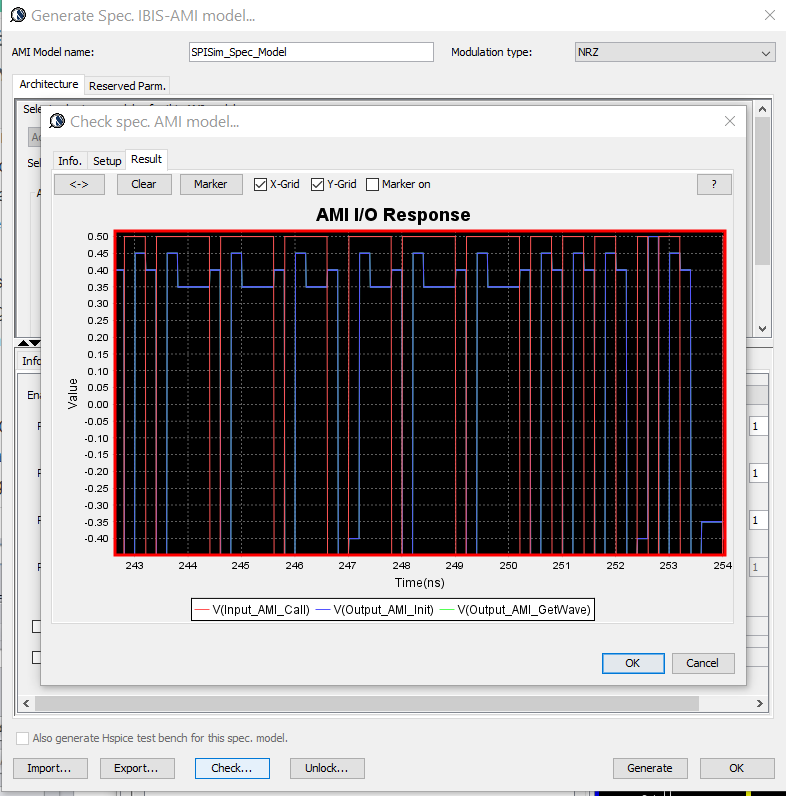
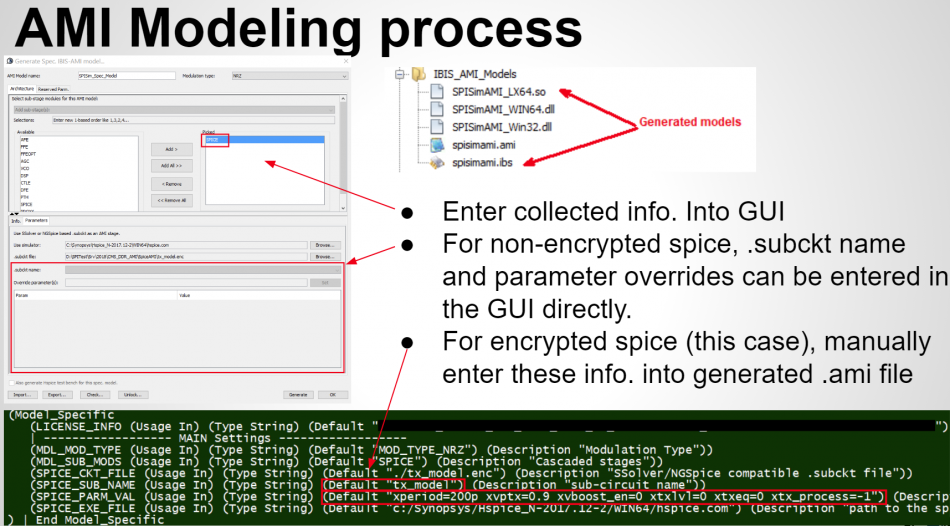
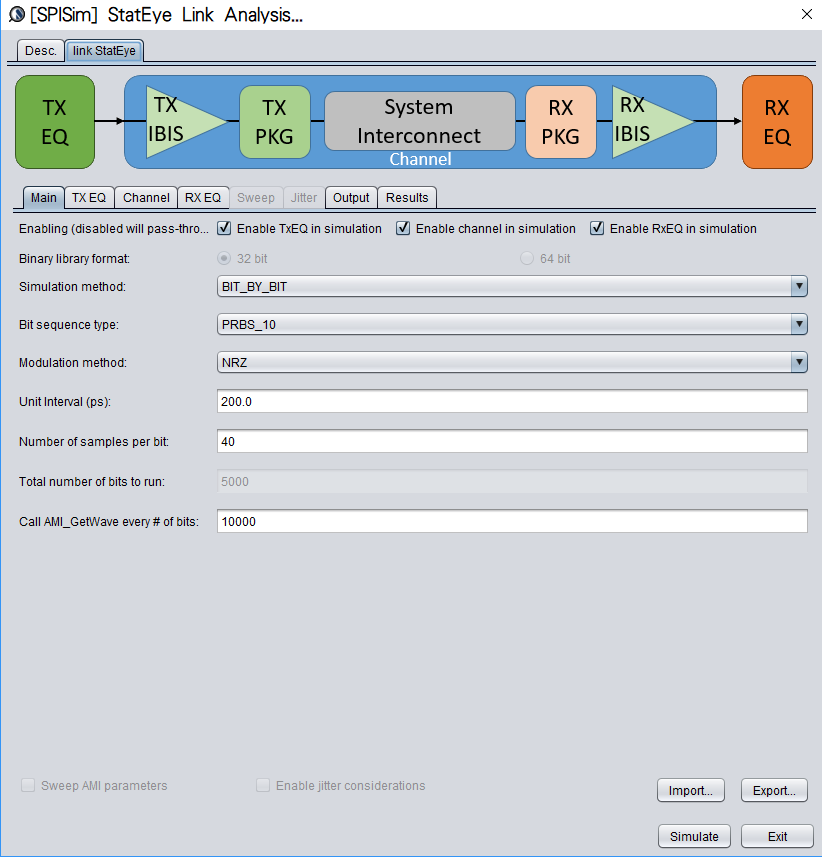
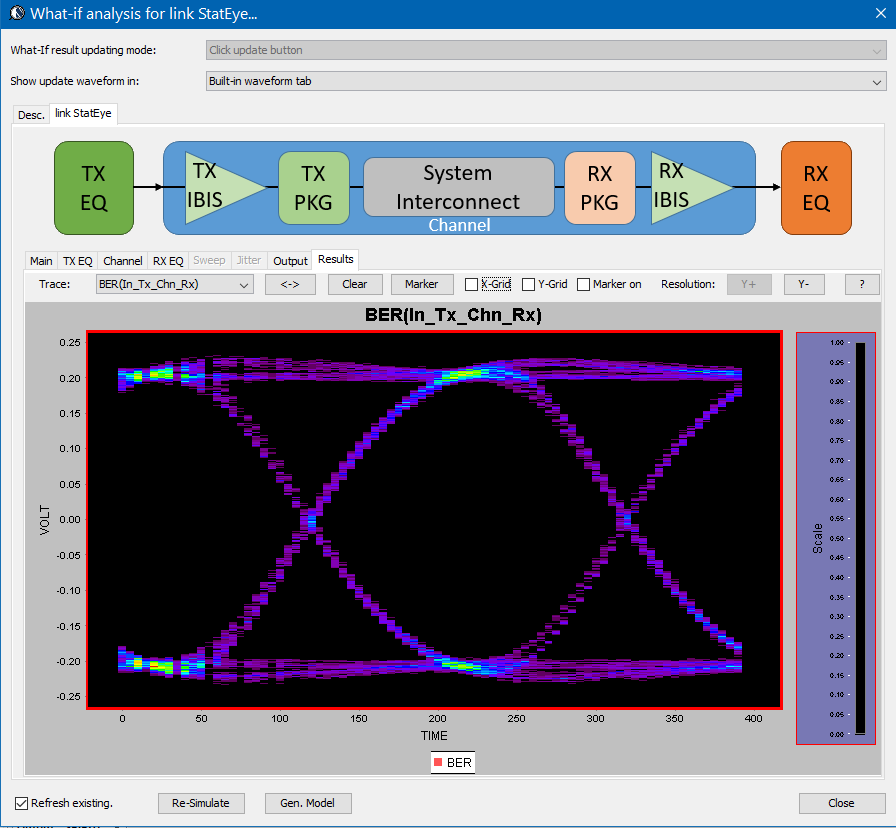

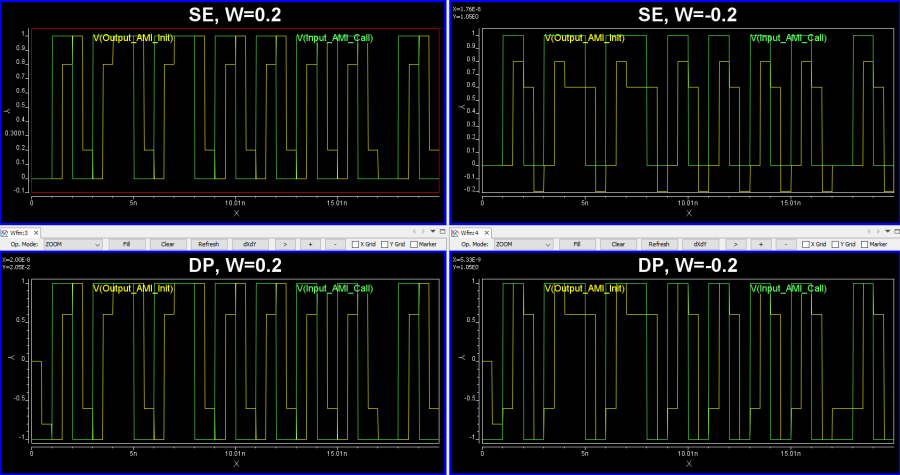
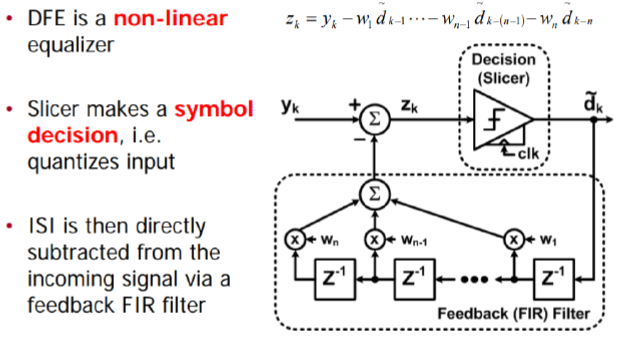
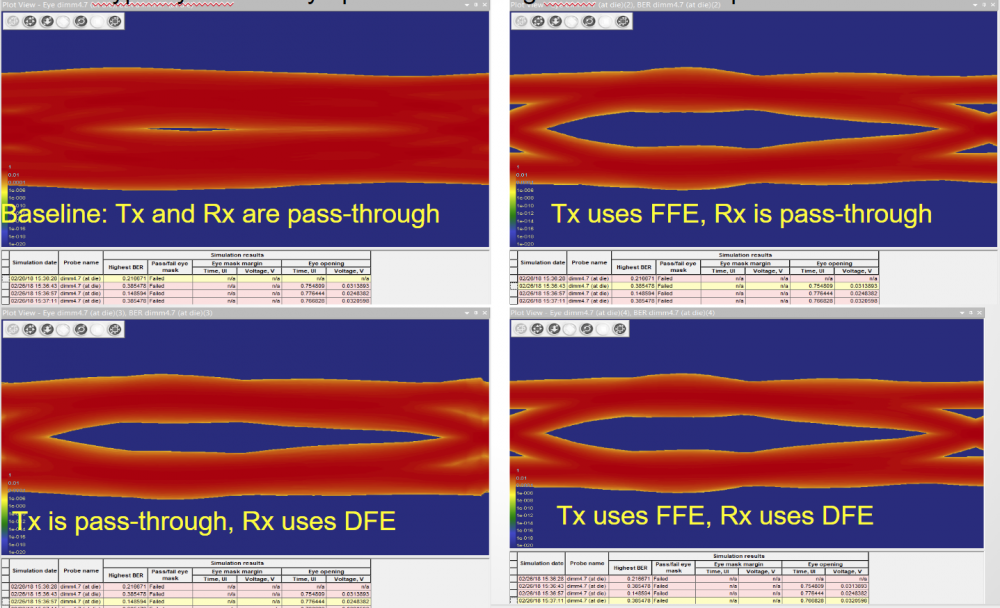





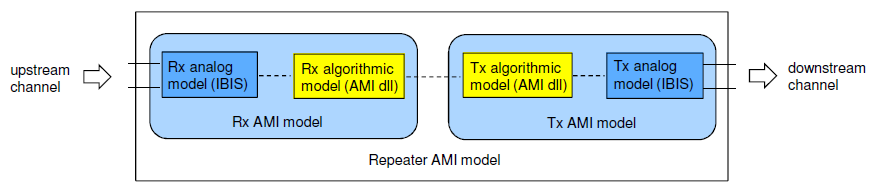
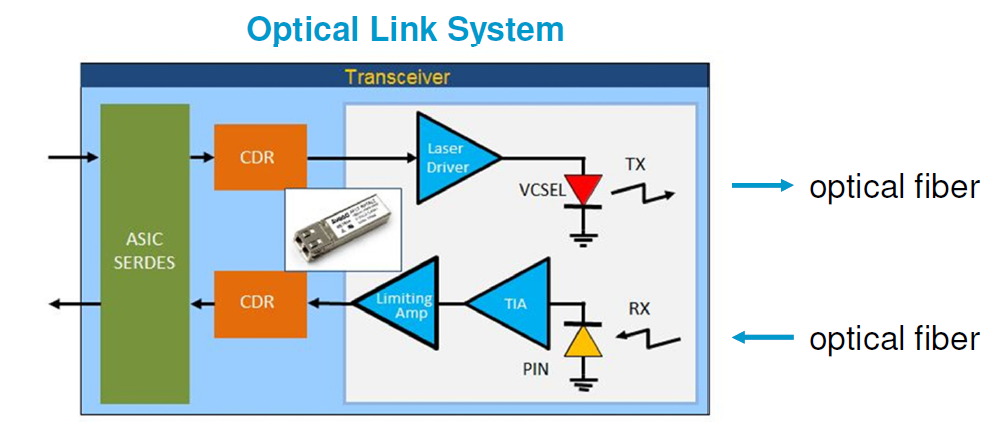
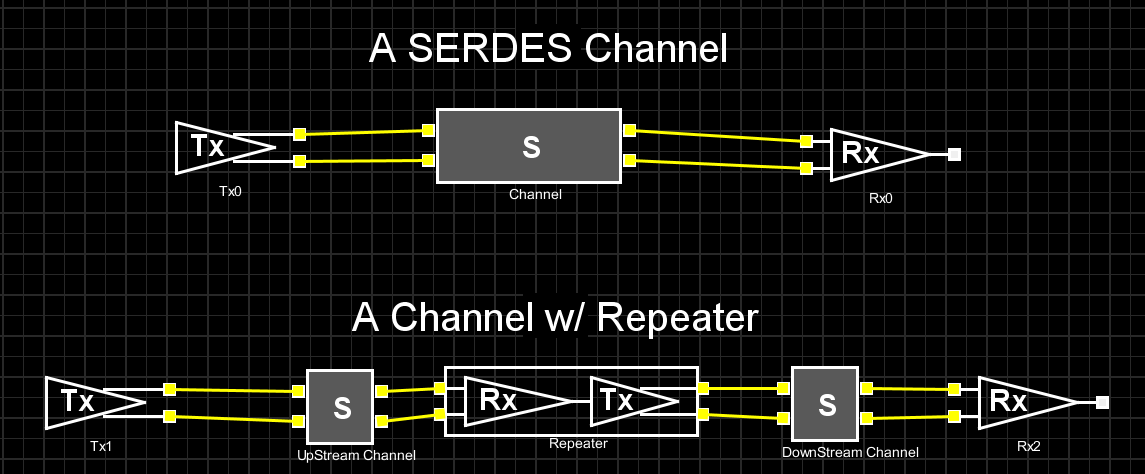
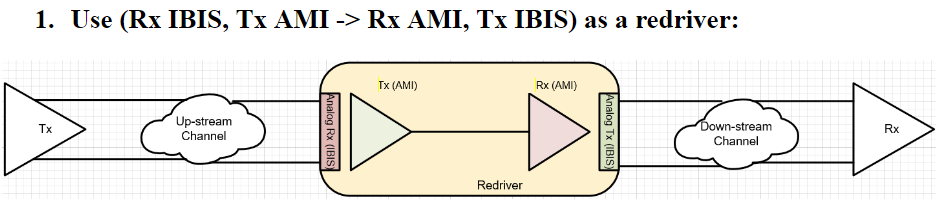 第一種情況中, 所建的TX/RX端就如實地在AMI裡呈現, 這裡的假設是用戶的通道仿真器可以充分支援TX/RX間的非差分信號,故而這樣的安排可以讓用戶對其間的效應做量測或做不同的安排(比如說不同長度的光纖走線)
第一種情況中, 所建的TX/RX端就如實地在AMI裡呈現, 這裡的假設是用戶的通道仿真器可以充分支援TX/RX間的非差分信號,故而這樣的安排可以讓用戶對其間的效應做量測或做不同的安排(比如說不同長度的光纖走線)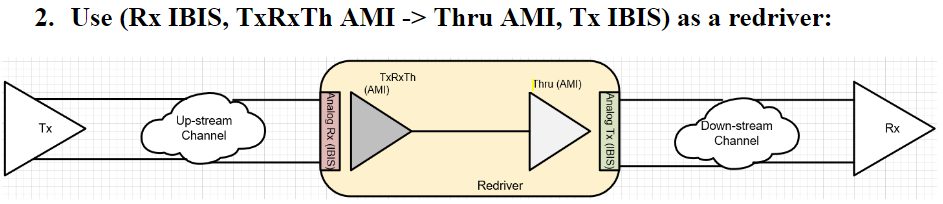 第二種情況中,我們假設用戶的通道仿真器只支援差分信號,則我們就把原TX/RX端的AMI模型”合”在一塊而置於Repeater的前端, 至於後端則是無味的pass-thru模型。如此一來, 由於進入光模組及其輸出均為電氣性的差分信號,便可以滿足其所用仿真器所需而能適當運作。
第二種情況中,我們假設用戶的通道仿真器只支援差分信號,則我們就把原TX/RX端的AMI模型”合”在一塊而置於Repeater的前端, 至於後端則是無味的pass-thru模型。如此一來, 由於進入光模組及其輸出均為電氣性的差分信號,便可以滿足其所用仿真器所需而能適當運作。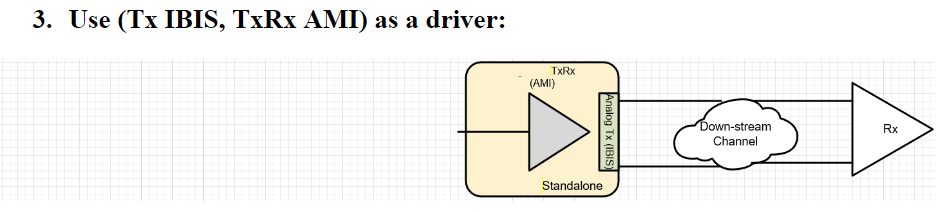 第三種情況中,我們假設系統廠的設計及現有模型是針對下游通道的部份, 所以做法上是把TX/RX端的AMI模型”合”在一塊而設計其成一個TX的模樣, 如此一來, 即便用戶沒有上游部份的設計, 其也可像一般沒Repeater時一樣做單一通道的設計。
第三種情況中,我們假設系統廠的設計及現有模型是針對下游通道的部份, 所以做法上是把TX/RX端的AMI模型”合”在一塊而設計其成一個TX的模樣, 如此一來, 即便用戶沒有上游部份的設計, 其也可像一般沒Repeater時一樣做單一通道的設計。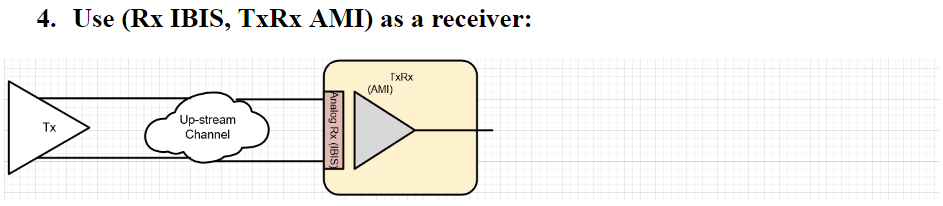 第四種情況和第三情況類似, 但用戶專注的部份是上游的部份, 所以所”合”在一起的模型是設置成RX的模樣當RX AMI模型來使用。
第四種情況和第三情況類似, 但用戶專注的部份是上游的部份, 所以所”合”在一起的模型是設置成RX的模樣當RX AMI模型來使用。