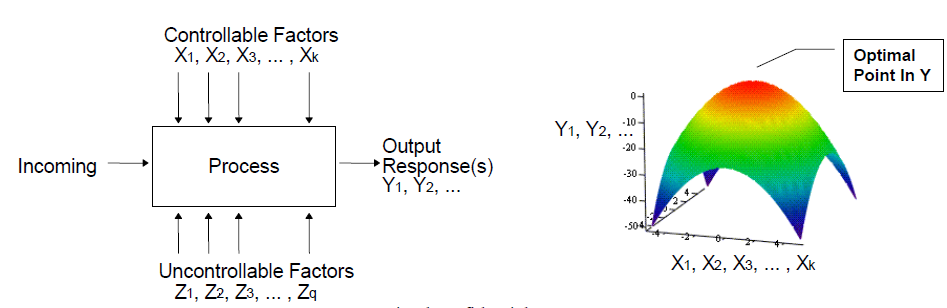
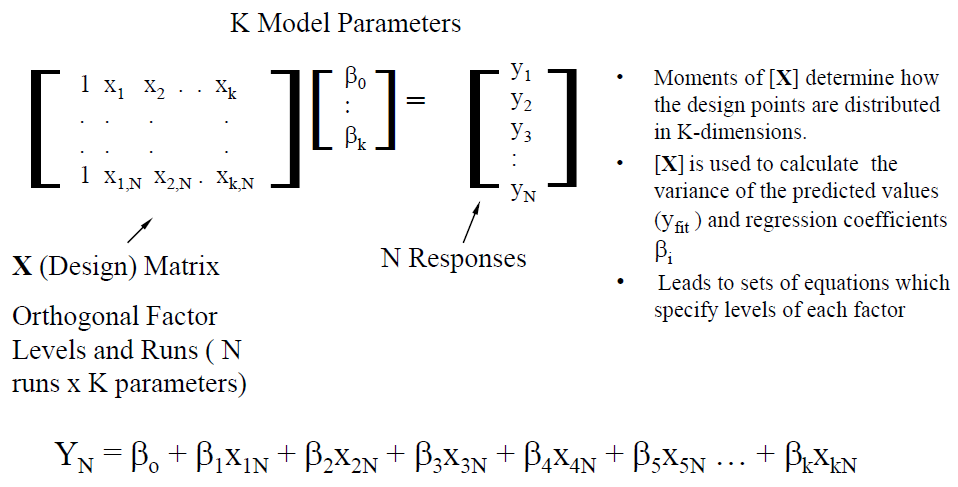
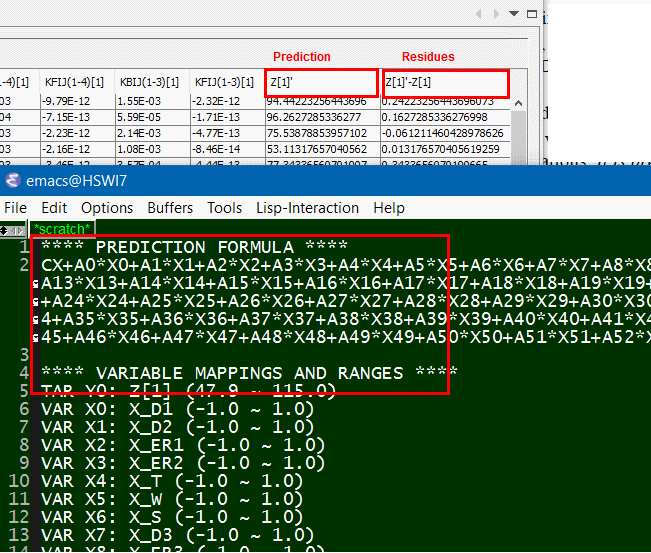
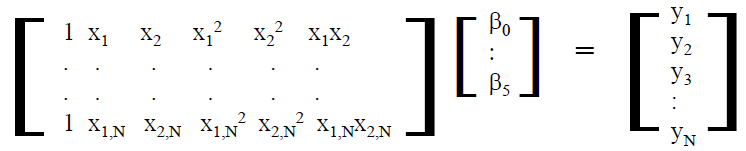在系統分析中,電源完整性的部分一般可分為佈線前及佈線後兩種情況,至於電源完整性, 因需由佈線後的設計來算出供電網路(power delivery network, or PDN)的模型來分析, 而這些佈線一般是由佈線工程師透過軟體手動製成,PDN的計算也多需透過費時的3D場解, 故在優化的過程上, 就與其在信號完整性(簡介於前兩篇貼文)不甚相同。
電源完整性:
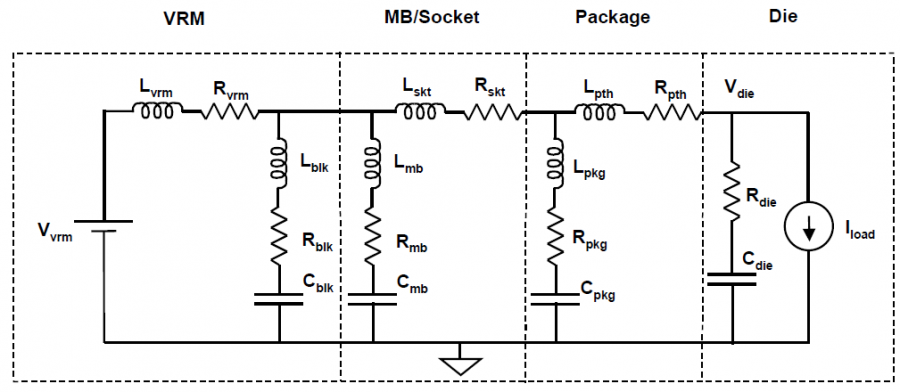
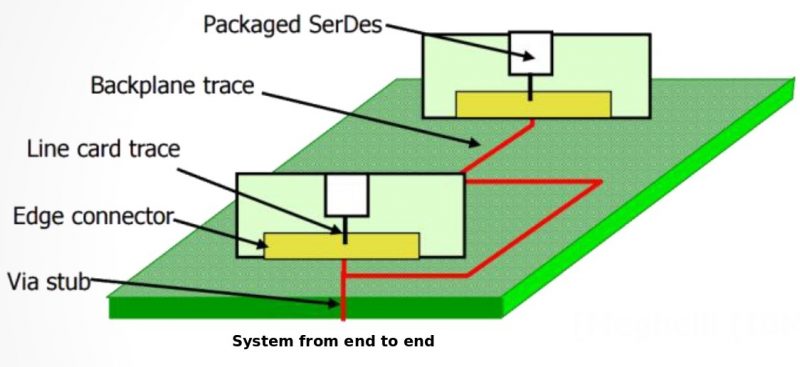
電源完整性的目的在於能將電力透過PDN來”乾淨”(即無雜訊)地傳到最右邊的裸晶部份(die), 以透過有源元件(driver 及 receiver)對系統進(即通訊通道)行操作, 以上為PDN的簡易模型,PDN從最左邊的穩壓器, 經過包含主機板、晶片封裝、終至於最右邊的裸晶;這中間的連接因為種種的阻抗, 會造供應電流在流過其中時形成壓降及漣波(ripple);這些供應DIE的電流最終是由最左邉的穩壓器所提供, 但中間的種種解耦電容(decoupling capacitors)也會在運作間儲能而與穩壓器一起提供瞬態電流。由於不同數目及在不同工作區間的buffer切換運作,整體的工作電流也會隨之變化而使得漣波的情形更加顯著。也正由於這壓降及漣波,使得連到DIE上的buffer驅動強度及速率會形成變化及顫動(jitter); 故欲達電源完整性, 就非得對在最右側裸晶DIE的部份能有的、含漣波在內的壓降做一規格上的限制。
一般而言, 這PDN上的阻抗可分為電阻性及電感性兩種成分;電阻性的壓降是用歐姆定律般而正比於通過其上的電流, 而電感性的壓降則歸因於電流在時域上的改變(di/dt), 故欲減低後者的影響, 就得減少PDN上的有效電感;一般減低的方式是在安排不同值的解耦電容使其在不同頻域上能發揮作用, 終至在工作頻寬的範圍內有均有較低的阻抗。
也正由於這PDN的模型是佈線後的結果,故而無法如給spice做仿真的網表(netlist)一樣,直接或簡易地產生由不同參數形成的設計; 而解耦電容一般也是由第三方廠家所提供(e.g. Murata), 所以工程師也在設計過程中也得面臨如何安置及選值的問題。一般而言,電源完整性的分析包括下面兩個項目:
- 封裝疊層、電源性通孔的安排及腳位輸出等(pin out)
- 解耦策略(僅能使用land side cap, die side cap或兩者)、電容值、數目及安排位置等
透過合成設計來優化:
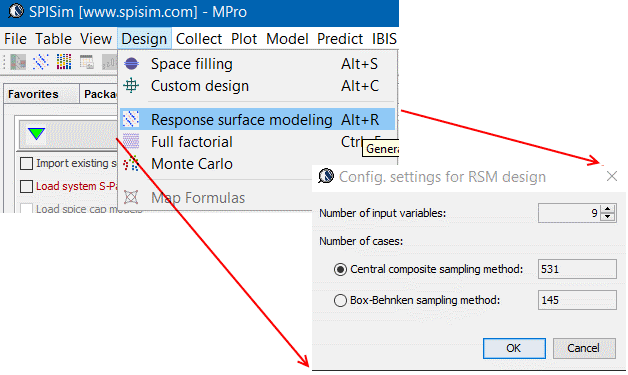
PDN 的佈線是透過3D場解來分析, 故若吾人能透過一事先計劃的規則而很快的透過軟體或AI合成的方式來產生多種不同參數的佈線, 則設計週期就能大大地縮短。其次, 以此產生的多種設計也可透過批次的方式(batch mode)平行地或依序做場解而在不費人工的情況下很快地得到不同設計的結果,透過對這些結果來做分析便可間接達成優化的效果。
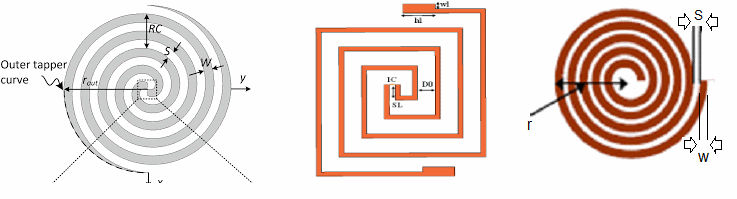
以上面的晶片上天線設計為例, 設計雖有不同, 但幾何關係可以利用不同的參數來界定出來, 從而軟體就可針對這些參數來直接合成不同參數及形狀的天線;相較之下, 若是由佈線工程師一點一點地畫出這些天線, 則不儘煩瑣耗時也不易精確。對於PD設計而言,其佈線當然不像天線設計般是以單一元件為主及簡單, 但同樣的精神仍是可以套用。透過最佳實作規範(best practice)及以往設計的經驗而將合成規則或指令設計於軟體內, 則其可達成如下自動化項目:
- 修改疊層厚度、界質係數(e.g. permittivity, loss tangent)等;
- 於特定的疊層上、依據net name或其相對於某一晶片腳位的位置自動地產生pin, node, trace, shape生等
- 依某種樣式產生power via並自動連到power/ground plane or nets, 其間自動地產生void及使用指定的pad stack
- 對特定區域的設計進行複製、轉向或縮方再以陣列形式產生於晶片上的其它位置
- 在這些產生的過程中做DRC並產生相對應的資訊(如警告等等)
由於合成的結果是透過特定的3D場解來分析, 故上述的流程一般是針對此一場解器所特別編程的, 也由於不同佈線格式對設計物件(pin, node, via, trace, shape 等等有不同的資料結構及語法, 故這類的流程要廣義化到能適用所有場解器是較為困難的。無疑地, 一旦這種合成流程建置完成, 透過參數性的分析來合成不同的設計再加以比較就不再是問題,也就更能產生優化的設計。
解耦分析:
一旦解耦策略形成後(即決定是Land side cap, Die side cap或兩者), 則接下來的工作便是依此形成佈線,3D場解後分析不同可能解耦電容組合的效果。假設事先不安置任何解耦電容,則場解出來的S參數可看作是”中性的”(neutral)而可透過後置處理的方式針對不同解耦組合用同一個S-參數很快地做分析。也就是說:如果疊層及佈線沒有改變, 是不需要再為不同解耦電容的安排重做3D場解的。
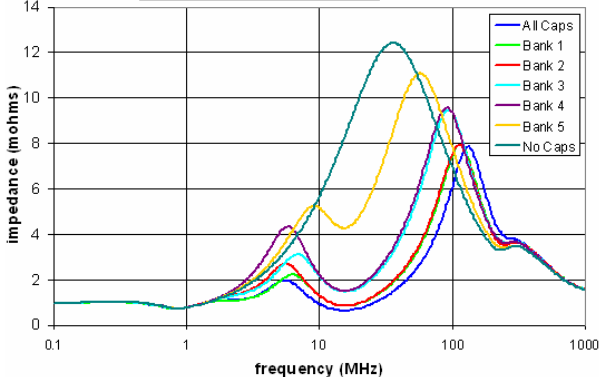
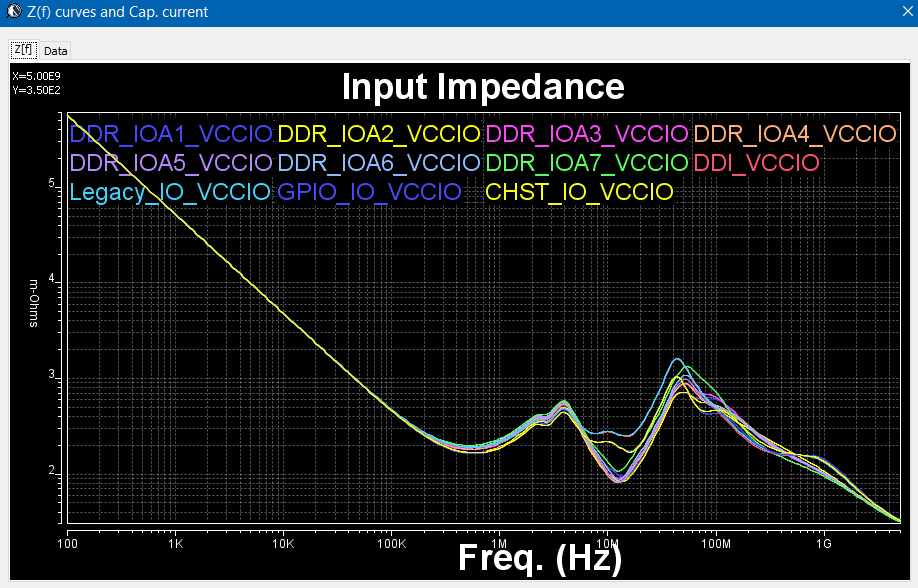
如上圖所示, 不同解耦電容的安排下從裸晶(DIE)上看進去的輸入阻抗也就不同, 概念上, 吾人可以把現有的S參數放到如SPICE的仿真器裡來對不同解耦電容的安排做頻域上的分析來得到輸入阻抗, 實務上, 這種仿真是沒有必要的… 因為可透過S參數的數學計算(如轉成Y或Z參數再將電容模型頻域上的響應一起含括便可很快地直接得到下列相關的解耦安排資訊:
- PDN的輸入阻抗(包含電阻性及電感性的):
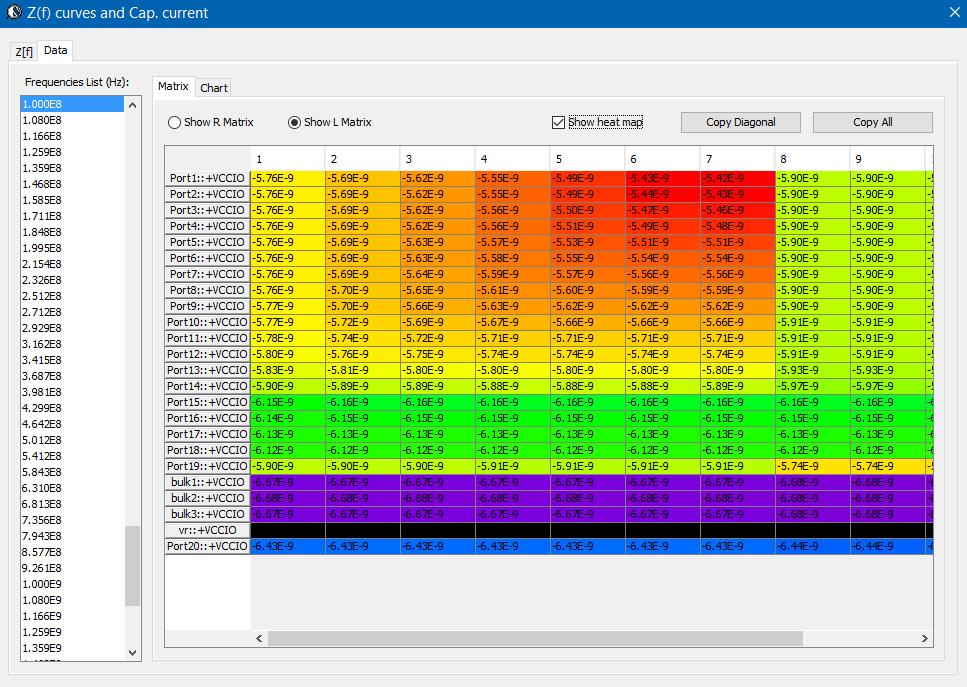
- 不同解耦電容在不同頻域上供應電流的能力:
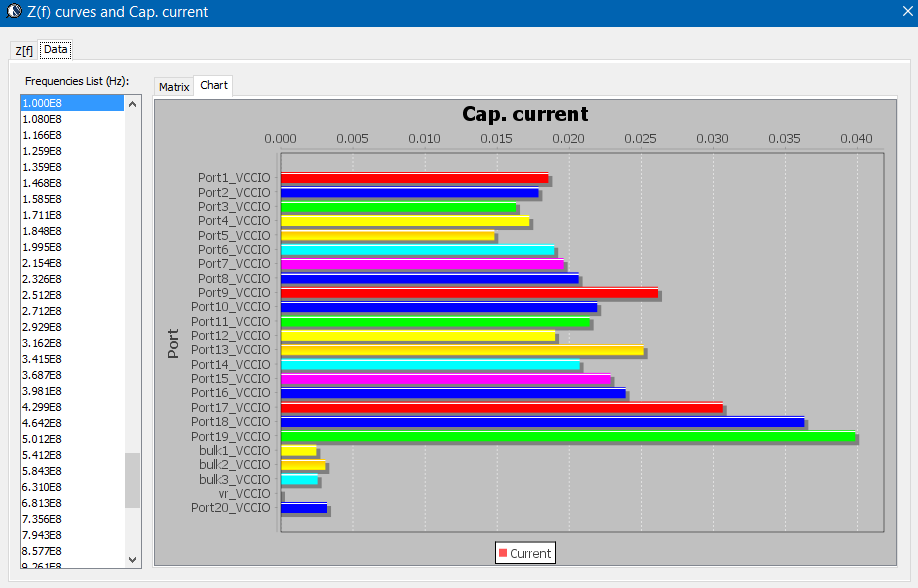
- 從DIE看入的輸入阻抗:
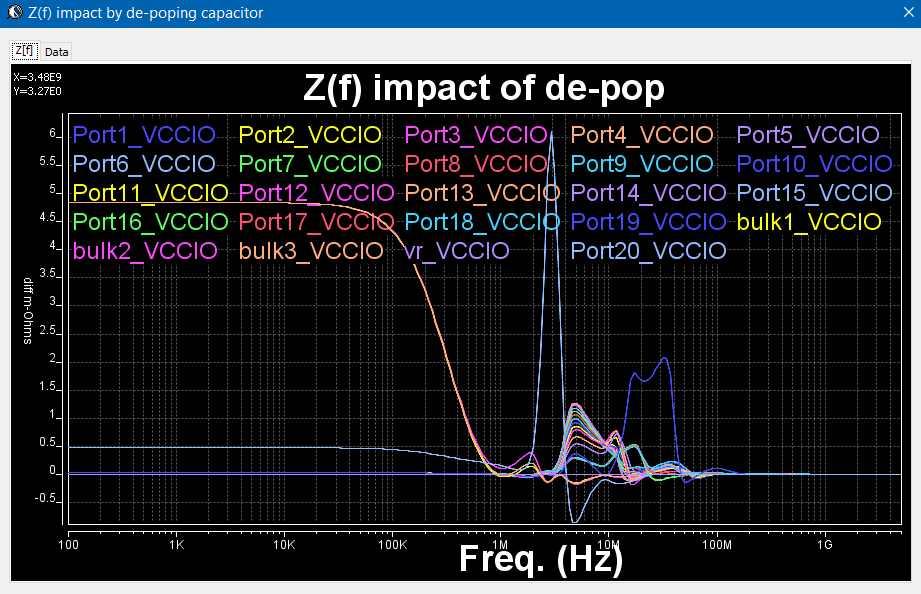
- 電容有效性分析, 即若將某一解耦電容拔除,其對DIE埠輸入阻抗會造成的影響:
- 不同解耦安排的假設性分析: 由於上述的分析均在很短的時間內可以完成,故而就能對不同解耦電容的安排(位置、數目及電容值乃至於其價格等)做假設性分析並依此而達到優化的目的。