[這篇貼文系為2018 DesignCon IBIS Summit發表的同標題文章做準備, 相關簡報檔及現場錄音(英文)已連結於此文之末。]
研究動機:
AMI模型的主要部份是二進位檔.dll (dynamic link library, on windows) 或 .so (shared object, on linux)的函式庫, 這些檔案本身是非執行檔而無法直接使用;需要先有另一個”驅動程式”把這些函式庫讀進來才能開始運作;EDA公司如新思的HSpice裡就有這麼一個需要License才能用的AMICheck, 其能對讀進來的AMI模型做上升沿/下降沿及單一位元波的試驅動; 本司也提供了類似功能的SPISimAMI.exe但不需License且還可以用戶自定的波形來驅動。這些小驅動程式在簡易快速地測試所得的AMI模型可否使用上頗有助益、但若要拿來測試模型在完整通路/鏈路分析上的實際運作上則有不足之處。在理想情況下, 一個通路分析的仿真器會把TX及RX端的AMI模型都讀進來而後與通路的response運作並將結果做分析。如果一個AMI模型開發者的IDE (integrated development environment)可以讀入這仿真器並有其源碼可編譯, 則不論是在仿真器中欲讀入AMI模型時, 抑或是AMI模型裡, 都可設入break point並在除錯時暫停於此或步步前進(step through)以能完整地分析模型的實際運作。
即便是開發人員沒有仿真器的源碼, 至少理論上IDE也可”attach”到這仿真器的程序(process)而僅對開發中的模型做除錯。這”attach”的動作需在程式一開始還未讀入AMI模型函式庫時便需執行。現實情況則沒想得那麼簡單, 因為現今的EDA軟體多允許用戶透過圖形使用者界面(GUI)來對AMI的參數、分析模式(statistical or bit-by-bit)、擾動參數等等先做設定, 而在按下”Simulate” 或”Run”的按鈕後仿真的動作才正式展開, 在全部運算完後再把結果傳回給前端的GUI顯示。而在按下開始仿真鈕的那一瞬間, 另一個程序(process)是被”生出來的” (spawn, or forked), 所以事先不知道其ID為何, 故而也就連自己有源碼的AMI模型也無法偵錯。Windows下的visual studio也是直到最近才有”自動attach到spawn process”的功能, Linux上的GDB對此則是付之闕如。再者, 當通路裡有TX及RX端一同做優化(optimize)的動作時, 單單只偵看TX或RX端的AMI模型也是不夠的..無法得知優化是如何進行。凡此種種, 皆造成在AMI模型開發上的挑戰。
有鑑於此, 對於那些非EDA公司而無法得到仿真器源碼的模型開發人員而言, 開源的通路分析平台就是一種可能的方向了;至今為止, PyBert 及COM (channel operating margin)就至少是兩種可能的選擇;就我所見,這些平台大都已有基本的TX/RX演算法模組供使用, 故而把這些以AMI的方式來取代或許就可解決我們之前談到的需求且可縮短模型的開發時程上述兩者之中, pyBert己有初步的AMI架構在內, 則這篇文章就為如何在COM流程裡加入同樣的功能來做探討。
關於COM的背景資訊:
COM (Channel Operating Margin)是已確認通過的IEEE802.3規格, 有興趣的讀者可發現連結於下的COM原主要作者(也是我之前在英特爾的同事)Richard 的簡報:[Channel Operating Margin Tutorial], 若郤知更深的技術資訊及所用到的數學式, 則可直接參閱802.3的規格文件、Richard在2013年DesignCon發表的同標題文章甚或是公佈在802.3官網的COM程式原碼。
要在本貼文內短短的兩三段就把COM說清楚顯然是緣木求魚, 所以以下就僅以AMI模型開發者的角度來看COM對AMI的可能運用。
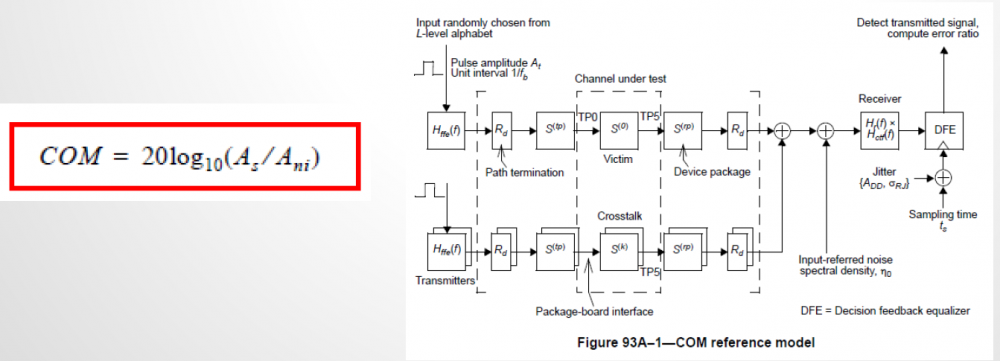
上圖所示即為COM的參考流程。右邊的上半部份講的是through type的inter-symbol-interference (ISI)影響, 右下半的部份則是遠端或近端串擾(cross-talk)的部份, 這兩者之外, 其它可能的系統雜訊、諸如擾動jitter等等也都有列入考慮; COM本身算的即是這廣義的信號/雜訊比, 信號強度是以單一位元脈波, (Single Bit Response, SBR)的最高點來定義;由於COM也已界定了一同傳訊速度/界面下不同參數的內定值, 所以在使用上很直接, 至於等化EQ的部份則用TX端的FFE、RX端的CTLE及DFE也都包含在內。
對一欲提供AMI模型的SERDES設計者而言, interconnect的S參數是如何而來並不是重點..其有興趣的是TX/RX兩端; COM直接能做的是能對所有FFE 不同TAP比重及CTLE DC增益的部份做窮舉式的掃描而回報最佳值,在每個不同EQ參數組合的試運算過程中, 有一個Figure of merit (FOM)值會被算出來以代表這個組合的最佳化程度, 在最佳EQ組合被決定之後, 完整的如BER般的SBR分析流程才會開始進行終於包括DFE及擾動等把所有的結果都算出來。
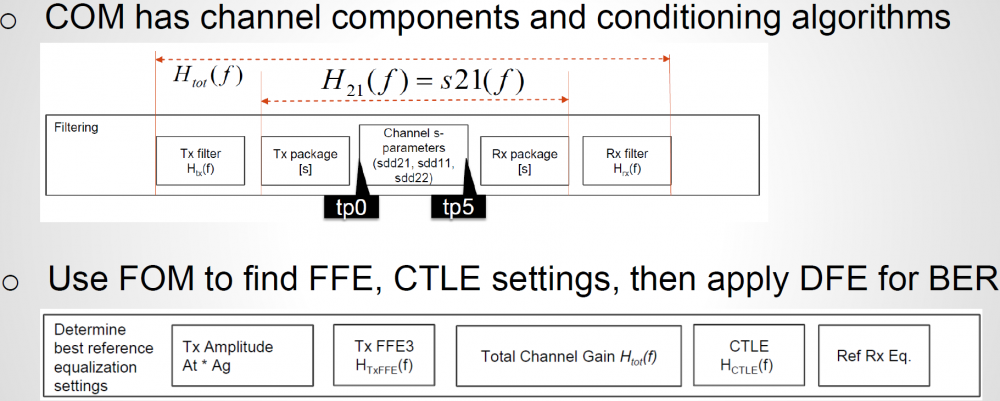
在通路分析的流程中, 第一步做的是對interconnect “characterize”的工作以便得到其impulse response, 這裡面其實魔鬼的細節很多:單端量測到的S參數要如何轉成差分S參數、不同部份封裝及breakout的部份要如何和主interconnect串接起來、甚至到串接後的S參數要如何先做conditioning以便其為passive, causal等等終能透過IFFT來得到突波響應, 凡此種種都是分析裡的重要環節且詳細研究起來要耗掉不少精力卻又未必與AMI建模正相關,所幸的是這些在COM裡也都有完整周延的考量及列作計算。
對於EQ的等化部份, 在早期(2014左右)的COM分析FFE的部份僅含有一個pre-tap及post-tap, 最近的更新已將其拓展為兩個pre-tap及三個post-tap, 至於CTLE部份, DC的增益是可以被掃的,除此之外的兩個極點及一個零點則用戶可以自定, 然後透過簡單的公司成CTLE的頻域響應再轉到時域來和突波做計算。也由於是突波被使用, 所以是以LTI為前提。接下來的流程就如IBIS規格裡的AMI流程敍述般一樣:interconnect的突波分別給TX及RX端算完後, 再與UI做計算形成SBR, 最後透過DFE完成對這一特定EQ參數組合的FOM計算, 所有的組合的FOM都計算過後擇最佳者做完整的BER-般分析流程。

如前所提, COM裡的EQ計算是窮舉式的, 所以當打開COM的源碼時, 讀者會發現在上圖的行數附近會有多層的迴圈, 黃色方塊裡可見到DC增益及FFE不同的比重在不同的迴圈裡被列舉(iterate)過去, 故而要把它們以AMI取代, 就是在這附近開始著手。
於COM流程中使用AMI:
由於AMI也需要參數, 所以兩個TX/RX在COM Matlab裡的函式要被取代為對AMI模型的讀取及運用, 除此之外, 在流程的更改上有兩種可能的方向:
- 線性非時變設計: 由於COM對EQ的計算是以突波為主, 所以如果模型是LTI (即運算不必然在GetWave裡做), 則以AMI_Init的部份直接取代相對應matlab 函式即可。
流程上來說, 第一步是把上述的多層迴圈以單一迴圈來取代, 這單一迴圈可以是對可能的EQ參數組合(未必是窮舉)一一列舉過去, 也可以是有一”stopping criteria”的決定式在內的(近)無窮迴圈, 一旦裡面TX/RX或一起的優化過程收歛之後即break而跳出去; 而由於是用自己的AMI模型,所以TX/RX的結構為何也就不受原COM設計所限, 比如說CTLE的部份可以是很多預先決定好的頻響曲線等等, 至於若TX及RX一起做優化, 則原COM 裡FOM的或可繼續拿來用也或可以自定的cost function來取代。
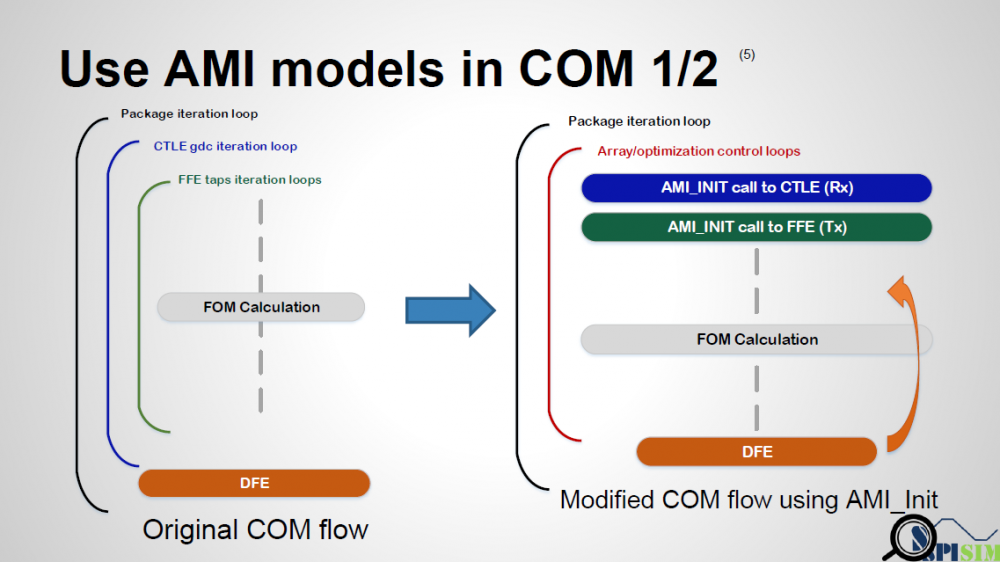
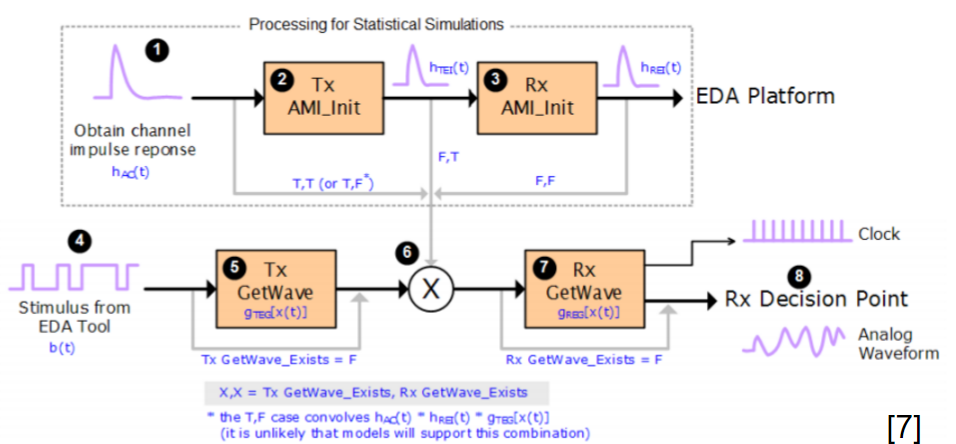
- 非線性時變設計: 在這情況下, 一類似PRBS的數位訊號需先被產生, 而後與interconnect 的突波convolve成波形後才能依序傳給TX及RX的AMI_GetWave函式; COM裡的DFE或可用也或可不用但FOM則需由用戶來自行對最後波形計算而得。

其次在實做的細節上, 因為COM原碼係以matlab 寫成, 故需以其相對應的讀取並呼叫外部DLL的程序來運作AMI模型, 簡單地說, 第一步是在Matlab的IDE裡用mex -setup來讓其自行找到系統上安裝的C/C++編譯器並做擇, 除此之外, 與C相容的AMI API 表頭檔(.h)也需事先準備(就把編AMI DLL時的header抓出來用即可), 而後依下列步驟進行AMI的操作:
- Load AMI model using: load(‘XXXXXX.dll’, ‘ami.h’)
- check libisloaded(‘XXXXXX’) and list functions in the library using libfunctions(XXXXXX’)
- Call AMI library function using calllib(‘XXXXXX.dll’, ‘ami_init’, htInput, rowSize…)
- Finally unloadlibrary(‘XXXXXX’)
最後值得一提的是因為我們只是要針對在開發中的AMI模型做偵錯, 並不是要把COM改成一個通用或給其它人也可以用的通路仿真器, 所以未必需要先建一個.ami檔案的parser. 我們可以事先把其會形成的key-value pairs以字串值存在一變數內再行使用即可, 至於PyBert則有其自己的AMI Parser。
實驗結果:
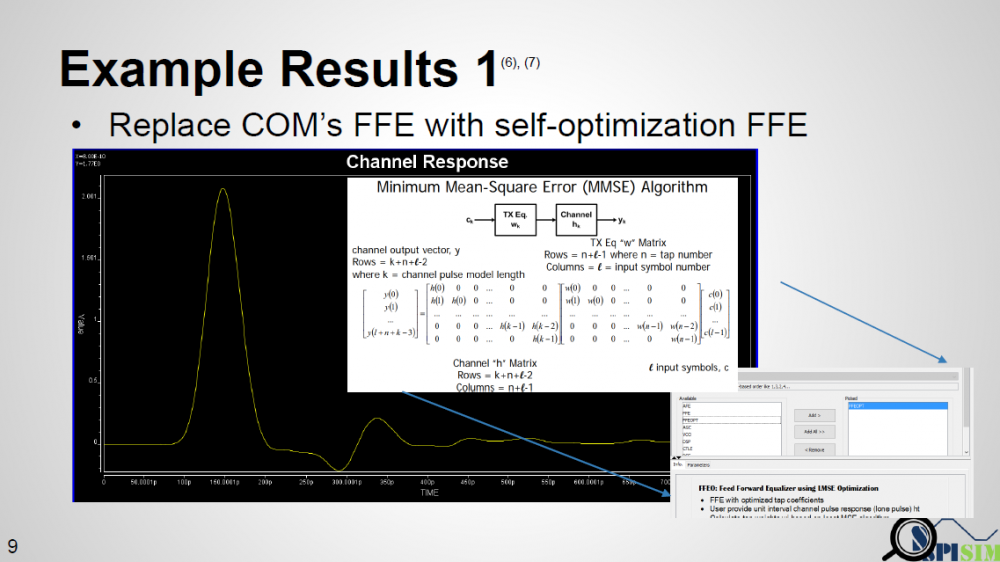
在此案例中, 我們不想要經過窮舉的方式來得到最佳的FFE比重值, 所以開發了一個可自行優化算出比重的FFE AMI模型並把它套到COM裡運動, 這優化的原理很簡單:當我們知道channel的突波之後, 因為所要recover的信號(bit-sequence)也就是一開始所傳, 所以FFE的比重當為何可以用pseudo-inverse及線性代數的技巧直接解出,這算出的結果是in the sense of Minimum Mean-Squared-Error. 我們想要確認做出來的AMI模型可運作無誤且其和透過原COM裡窮舉法得到的結果差不多。
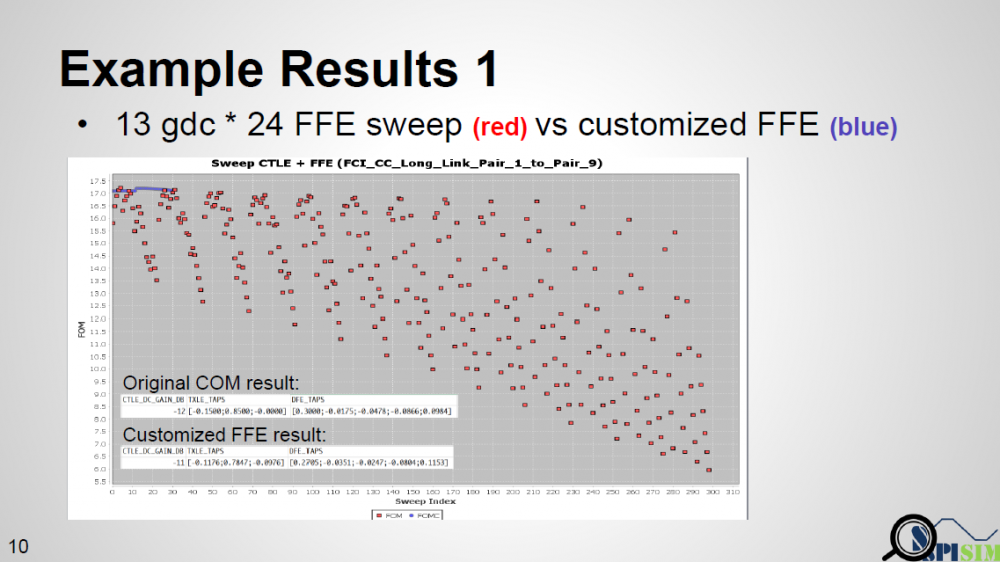
上圖所示為運算結果, 因為CTLE裡的DC增益有十三個值, 而且FFE的比種有24種不同的可能組合, 所以原COM總共要算三百多次, 每一次的FOM在上圖以紅點表示, 可以約略看出從左到右有十三個block, 每一個block內又冇24個值; 相較之下,我們的AMI TX模型只要算十三次(仍要列舉不同的Gdc), 其結果以藍點表示, 可以看到的是從左到右的每一藍點相對應那十三個紅色區塊大都是在最頂點或更高(高表示FOM好, 值可能更高是因為原COM的掃描有FFE GRID點的限制), 由此結果可認證我們的TX模型可操作無誤。另外可能的實驗案例包括做如PyBert般把TX及RX透過”Hula-Hoop”的優化演算法(2016 DesignCon paper)來同步做優化。
結語:
對於這個研究, 我們要先強調的是動機及需求….COM只是一個可能的方案。也就是對於一個模型開發者而言…不論是模型供應商或是被賦與建模任務的SERDES設計師而言, 能有一個完整的通路分析流程可透過IDE來讀取、偵錯開發中模型或與TX/RX同步偵錯是很有價值的,這一需求無法為簡單的驅動程式(AMI dll driver)所取代且也常不可得於一般商用的通路仿真器。
所幸此一需求已可以現有的開源分析平台所滿足, 其中 COM又因其已通過認證、逐漸廣而被使用、有充足的參考文件及最不可或缺的源碼而值得被列入考慮;其原有的TX/RX EQ部份架構簡單, 但要以我們所有或所開發中的模型來取代其實不難。不論是更改成適合LTI的statistical或是NLTV 的bit-by-bit都有可能, 而原COM裡的很多其它模塊或函式則可沿用;這種混合流程一旦建置完成, 將可大大縮短AMI模型開發的時程並增加模型在實際操作時的可信度, 所以很值得一究。
相關連結:
簡報檔: [請按這] http://www.spisim.com/support/paperetc/20180202_DesignConSummit_SPISim.pdf
現場錄音(英文): [請按這]


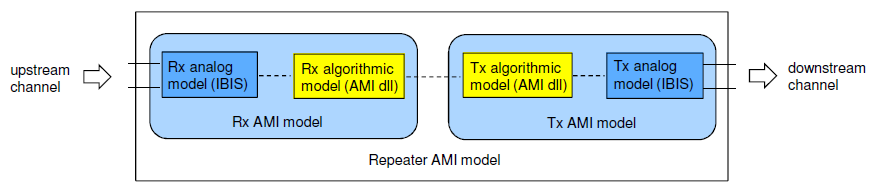
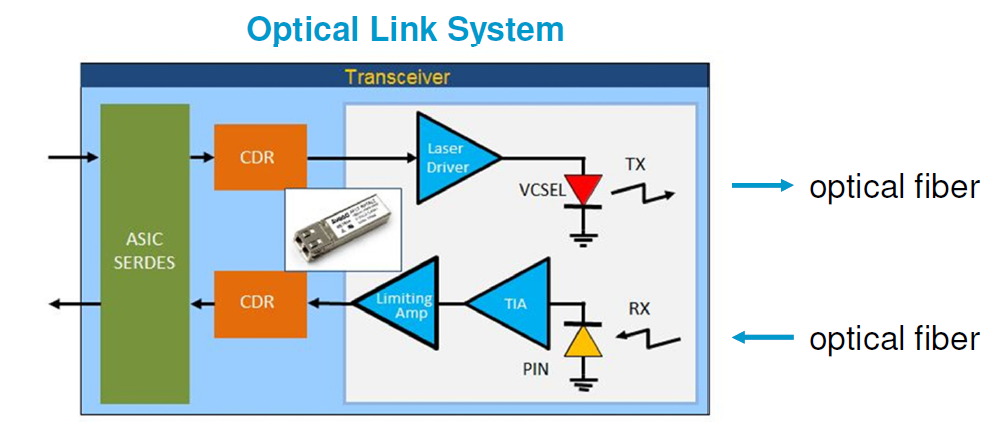
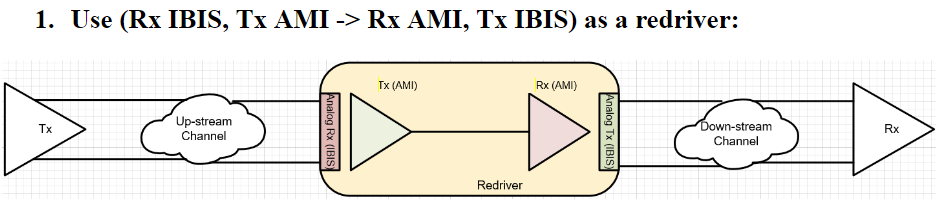 第一種情況中, 所建的TX/RX端就如實地在AMI裡呈現, 這裡的假設是用戶的通道仿真器可以充分支援TX/RX間的非差分信號,故而這樣的安排可以讓用戶對其間的效應做量測或做不同的安排(比如說不同長度的光纖走線)
第一種情況中, 所建的TX/RX端就如實地在AMI裡呈現, 這裡的假設是用戶的通道仿真器可以充分支援TX/RX間的非差分信號,故而這樣的安排可以讓用戶對其間的效應做量測或做不同的安排(比如說不同長度的光纖走線)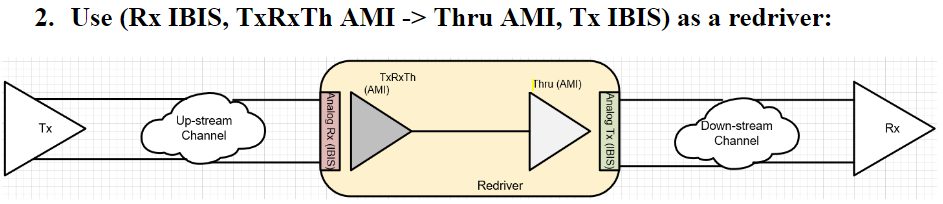 第二種情況中,我們假設用戶的通道仿真器只支援差分信號,則我們就把原TX/RX端的AMI模型”合”在一塊而置於Repeater的前端, 至於後端則是無味的pass-thru模型。如此一來, 由於進入光模組及其輸出均為電氣性的差分信號,便可以滿足其所用仿真器所需而能適當運作。
第二種情況中,我們假設用戶的通道仿真器只支援差分信號,則我們就把原TX/RX端的AMI模型”合”在一塊而置於Repeater的前端, 至於後端則是無味的pass-thru模型。如此一來, 由於進入光模組及其輸出均為電氣性的差分信號,便可以滿足其所用仿真器所需而能適當運作。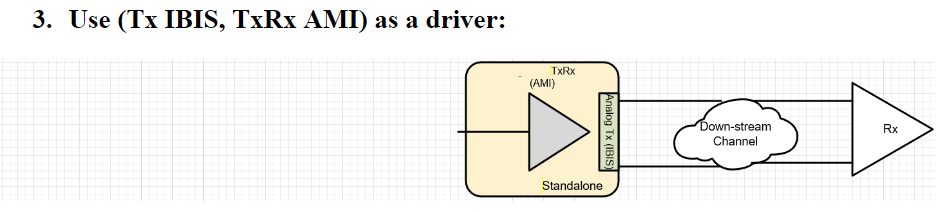 第三種情況中,我們假設系統廠的設計及現有模型是針對下游通道的部份, 所以做法上是把TX/RX端的AMI模型”合”在一塊而設計其成一個TX的模樣, 如此一來, 即便用戶沒有上游部份的設計, 其也可像一般沒Repeater時一樣做單一通道的設計。
第三種情況中,我們假設系統廠的設計及現有模型是針對下游通道的部份, 所以做法上是把TX/RX端的AMI模型”合”在一塊而設計其成一個TX的模樣, 如此一來, 即便用戶沒有上游部份的設計, 其也可像一般沒Repeater時一樣做單一通道的設計。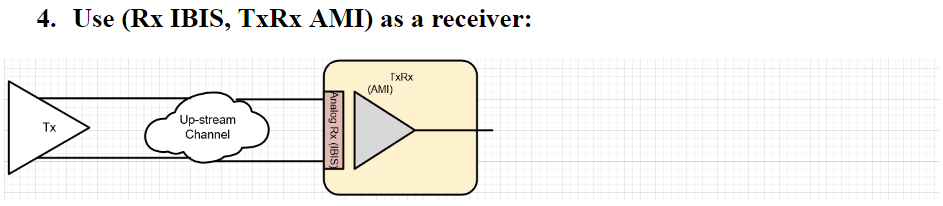 第四種情況和第三情況類似, 但用戶專注的部份是上游的部份, 所以所”合”在一起的模型是設置成RX的模樣當RX AMI模型來使用。
第四種情況和第三情況類似, 但用戶專注的部份是上游的部份, 所以所”合”在一起的模型是設置成RX的模樣當RX AMI模型來使用。