前言:
本司日前完成開發測試並釋出了數款可免費使用的網上應用程式以應通道分析的一些步驟所需 (相關資訊請按此) , 雖然這些軟體個自的產品網頁對其功能及使用上都有單獨的介紹, 但我們認為若也能在一套流程裡把它們串連起來則使用者就更能有個完整的概念並對背後的設計理念能有更深的了解。所以寫此篇貼文有雙重的目的: 首先我們希望對一般通道分析(channel analysis)的流程做個介紹,其次也希望展示讀者我們的這幾款APP可如何應用於其上。相較之下,一般要開發AMI模型並得到可做此類分析的仿真程式沒有十數萬美金起跳是不可得的, 現在直接從網頁就可免費執行!
概觀:

[Fig. 1, A SERDES system]
本文係以上圖的SERDES系統做為案例, 至於其它的界面如DDR, 則請見上篇貼文對有關本流程適用性的探討; 上圖中中間的藍色區塊所涵括的部分即為通道的部份(channel), 其主要的構成為被動元件如封裝、傳輸線、導孔、連接器甚至是cable等等,話雖如此, 主動元件如TX及RX端的類比前端也應被包含在內, 這些主動元件的模型一般都是IBIS或與製程或有相關的Spice設計呈現。另一種可能的做法是把這些主動元件排除在藍色塊通道的定義之外, 而將其與TX EQ, RX EQ等連在一起做;這種做法下的通道(藍色部份)即可以一S參數來描述。之所以會這樣做有可能是因為主動元件的IBIS模型不可得或是要得到通道響應的仿真器對手上現有的主動元件模型並不支援, 例如現今網上的免費仿真器以我所知都不直接支援IBIS。而如此因而和TX EQ及 RX EQ相結合的類比前端級就會加上AMI模型設計的複雜度所以可謂是收之桑榆但失之東隅。一般而言,這中間的通道部份的確是會把TX/RX的主動元件所包含內的。
有了透過仿真所得的通道響應之後, 接下來就是對TX EQ 及RX EQ的部份加以建模。最常見的模型格式是IBIS-AMI, 有關這些本司之前的大部份貼文都已有許多探討故在此不再多加著墨。
最後有關通道分析的部份, 首先仿真器會將通道的時域響應或S參數轉為突波響應, 而後取決於所選定的Statistical 或bit-by-bit模式,或者將此直接送入TX EQ也或者先和PRBS的位元列先做卷積再送入, 而後把TX EQ的輸出再送入RX EQ後把最終結果以眼圖或bath tub的形式呈現。之前有談到中間含主動元件的通道部份, 其整體來說雖是有源而非被動, 但在通道分析上仍是以線性非時變(LTI)為假設, 所以當EQ部份也都是LTI時, 光用一個位元波(single bit response)就可以拿來透過各種排列組何來算出所有可能位元序列的機率函式PDF, 從而再積分得到CDF而畫出bath tub曲線並能對不同BER下的眼高或眼寬做一量測。但若是EQ部份為非線性或時變(NLTV), 則就只能乖乖地跑上數萬至數百萬的位元再把如此所得的時域波形疊合起來形成眼圖再依此量測。於此尚未提到、本司釋出軟體也尚未內含的、是抖動(jitter)及噪聲(noise)的部份, 理論上而言也是將其各自的PDF再和現有的PDF做卷積而得到加乘的效果, 至於實務上的考量他日再以專文探討。
由上所述的通道分析流程細節可見於第IBIS規格文件的十章第二節裡。簡單地總結來說,一個通道分析的三部曲包括了1.得到通道響應、2.得到或產出EQ模型、及3.把這些都放到通道仿真器裡得到分析結果。
一、 通道響應:
通道分析第一步的是對通道做時域仿真以得到其響應,如前所說我們也把TX/RX的類比前端包括在仿真的原理圖或網表裡,並以全部響應會是LTI為假設。如果現有欲分析的通路是佈線後的結果,則第三方的全波場解程式則為必需, 因為諸如VIA或連接器等都需以全波的形式場解(field solve)才能得到精確的描述;broadband spice也常是需要的, 因其可將場解出的頻域轉成如RLC/EFGH的仿真器內建元件而於時域上使用;若通道是為佈線前的分析, 則這些Via/Connector的模型仍為必需但傳輸線的部份則可以現有元件代替。如果S參數會一同參與仿真的話則這裡沒做更多說明的部份、即藏在魔鬼裡的細節、包括了調適S參數以期為passive, causal, symmetric and asympotic 以及最終將單端的S參數轉成差分的形式。當所有的模型都就緒之後, 則可到我們的[SPISim_IBIS 程式]端並把IBIS 轉成免費仿真器可支援的格式: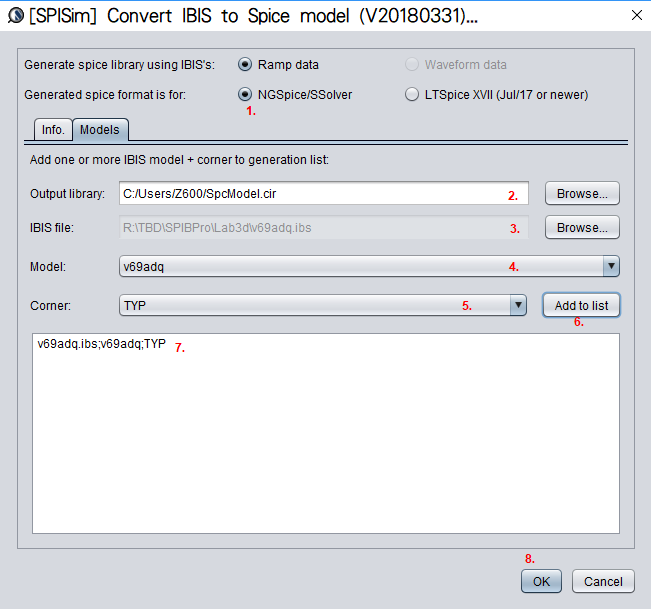
再來到Analog Device的官網免費下載LTSpice仿真器或直接用我們的SPILite:
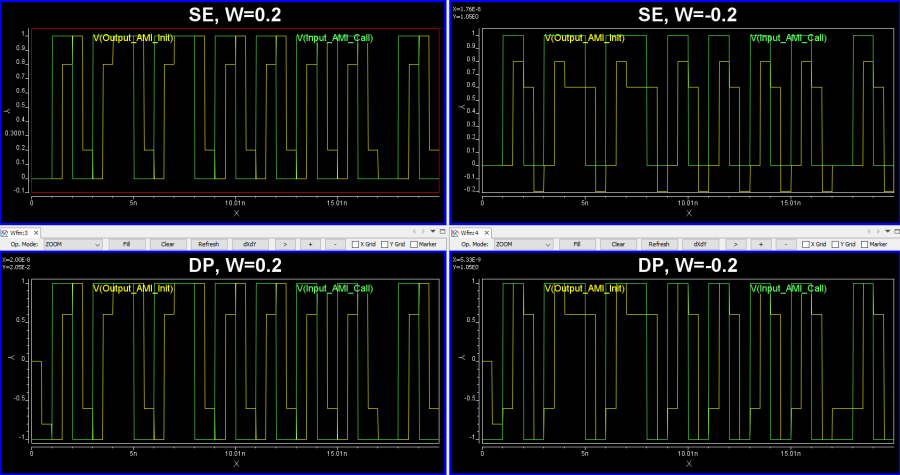
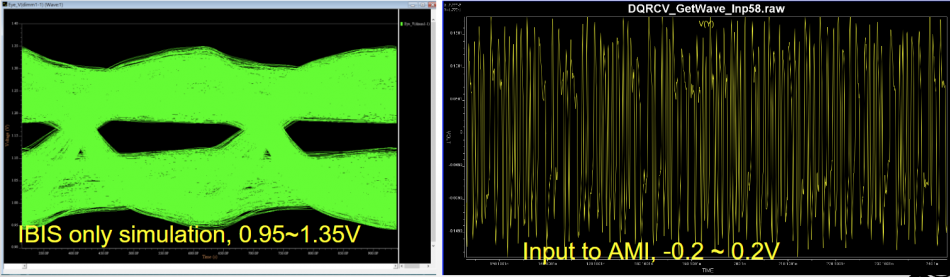
而後或是編輯原理圖或是用網表把所有不含EQ的通道的部份都建出來,再以時域做階波響應的仿真;若是一位元終將會有N個取樣點的話(這個設定值用戶可自行決定,一般是32 或40…以可整除整個bit-time為主,等一下分析設定裡會用到),那階波從0至1的變化就需以在這個取樣點所代表的時間裡完成, 仿真出來的結果(不論是LTSpice或是NGSpice, SSovler等,均為SPISim_IBIS所支援)會是.raw的波形格式而可為本司免費的SPILite來觀看確認。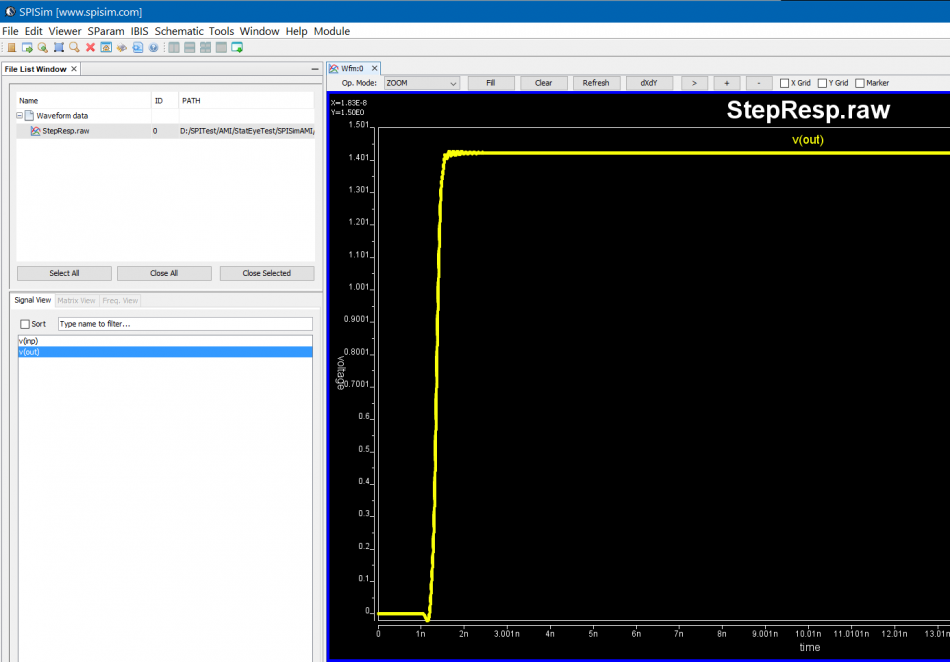
二、 EQ模型:
如果沒有EQ電路參與其中, 則用戶大可直接在上述的輸入裡更改相關的設定或激勵信號以而直接以傳統的SI分析方式在時域做多位元的仿真,再將結果做後處理及分析。但對SERDES或即將到來的DDR規格而言,EQ多為必要才能把眼圖打開, 而通道分析(一般是以StatEye的理論為基礎)之所以成為必要,即是因為其可在短時間內以卷積的方式把大量的位元和EQ模組做運算而得到可分析的結果, 也就是說, EQ模組(Fig.1裡綠色的TX及橙色的RX部份)也必需支援這種(以端點高阻抗High-Z為前提)的運算方式才能一起運作。現今這種EQ的模型多是以IBIS-AMI, Behavioral或是Spice的格式存在, 其中又以AMI為主流因其能為各不同廠家的通道仿真器所接受。所以分析流程的第二個步驟就是要得到或產生相對應的EQ AMI模型。
若是從無到有的話, 一般的做法是要以C/C++的語法透過合乎AMI API的格式來把動態函式庫開發出來, 所需不是三到六個月就是要更久;但用戶現在就可直接到本司的 [SPISim_AMI程式] 直接產生..完全毋需寫CODE及編譯: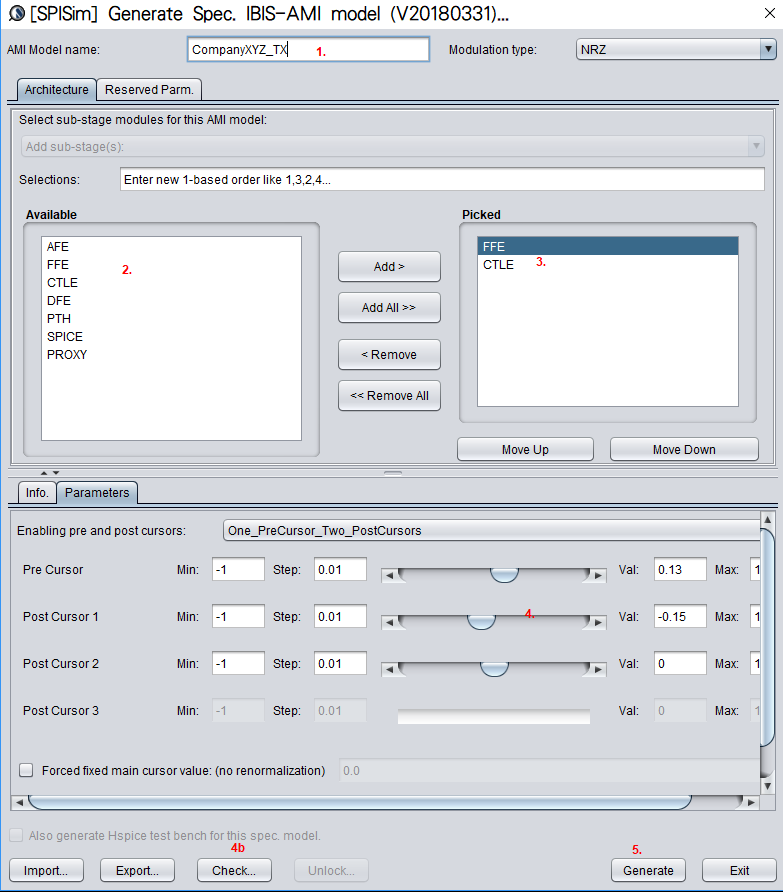
把TX端及RX端的EQ參數填入之後,甚至還可以直接在程式裡用內建的PRBS或用戶可提供的波形(唯一的前提是需為固定均時步uniform time step)來對所欲產的的AMI模型加以驅動: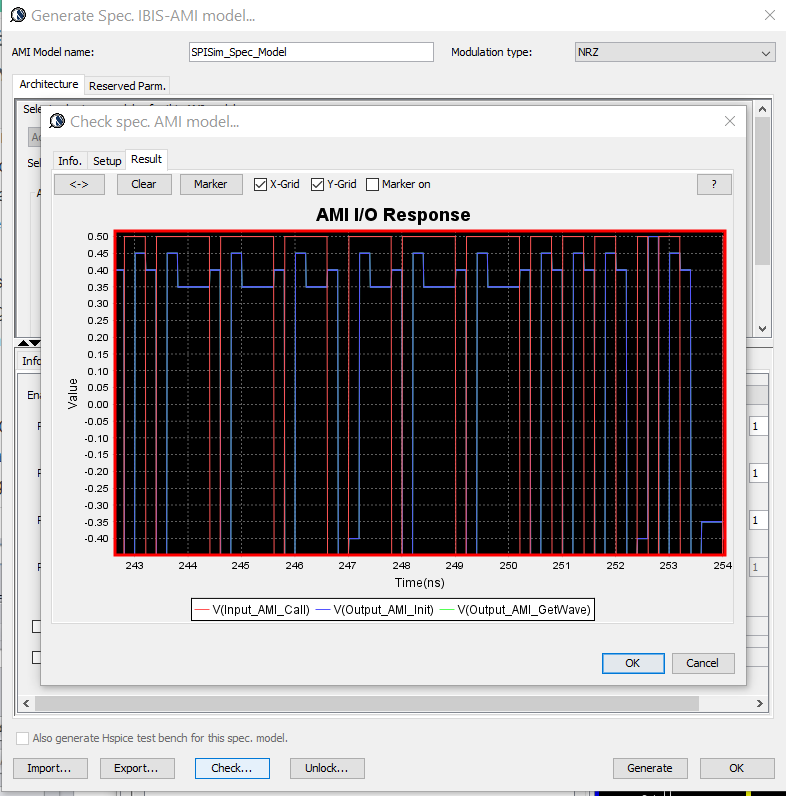
如果結果波形不合所需, 則回到參數設定處加以更改後再度即時測試, 最後按下”Generate” 按鈕相對應的AMI模可就產生了。這個模型不僅是可在本司的軟體上跑,拿到其它廠家的軟體(如ADS, HyperLynx, HSpice等一樣可以操作且結果都應一致;即便是用戶需要其它作業系統的AMI模型格式(如Windows 32, Linux 64)等,也可透過相同免費的SPILite以同樣的GUI操作而得之。
在本段落之初我們有提到很多EQ的其它形式是諸如behavioral或spice等(不論有無編碼加密), 在那種情況下,其很多含有細節的EQ響應(諸如有ringing等等)就無法透過如之前所示的預設AMI模型加以實現,則可以採用的做法是透proxy(代理人介面)的形式, 這點我們的免費SPILite也有支援且設計理代已揭諸於2017年的IBIS峰會中, 其概念是這代理介面AMI(Proxy AMI)會把用戶現有的spice檔案”包起來”, 而在仿真過程中透過用戶現有且指定的時域仿真器把這spice EQ的響應取出來,最後再以AMI API相容的格式傳會原始呼叫的通道仿真器, 以此形式的AMI建模以下圖簡示: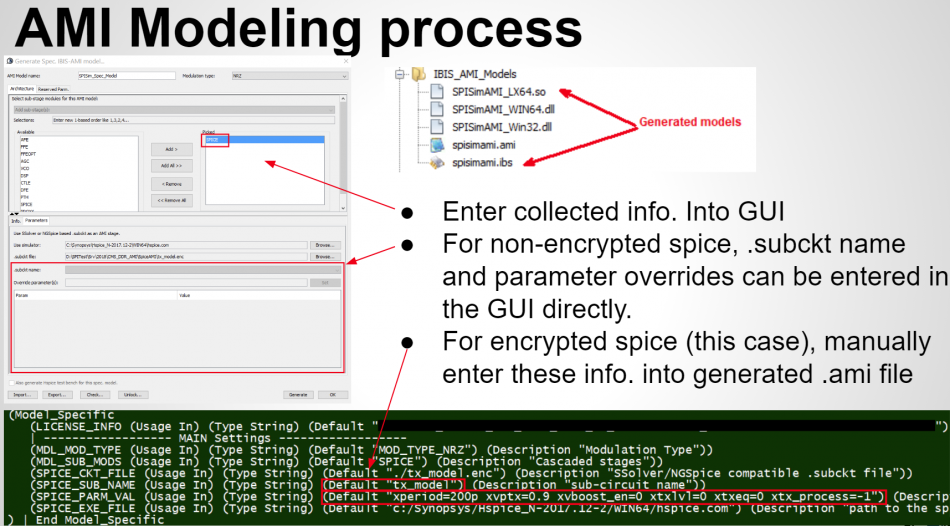
三、 通道分析:
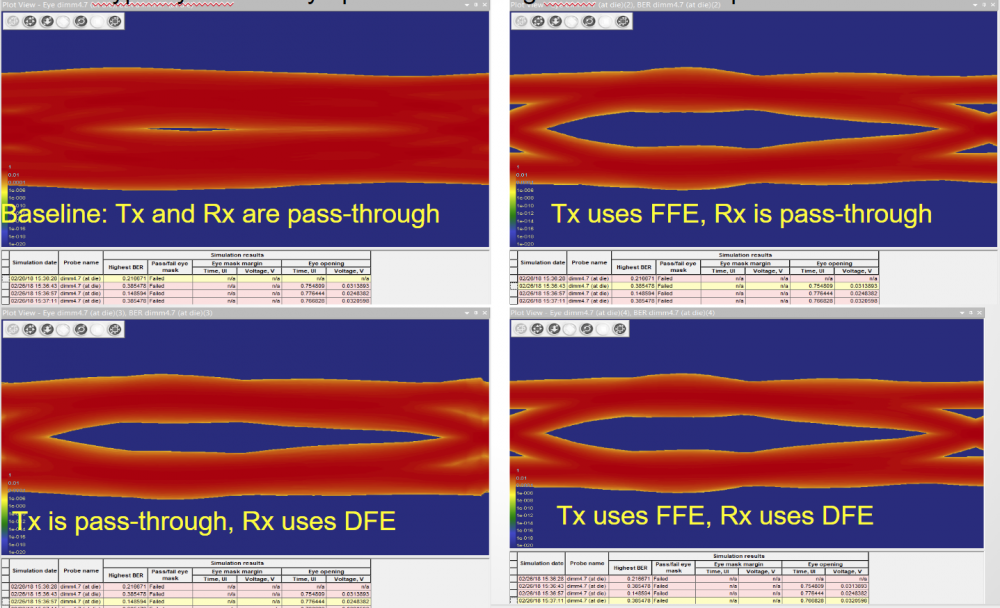
當TX EQ, RX EQ及通道時域響應都在前兩步驟取得之後,接下來就可把它們都放入 [SPISim_Link 程式]做通道的Stat-Eye格式仿真了: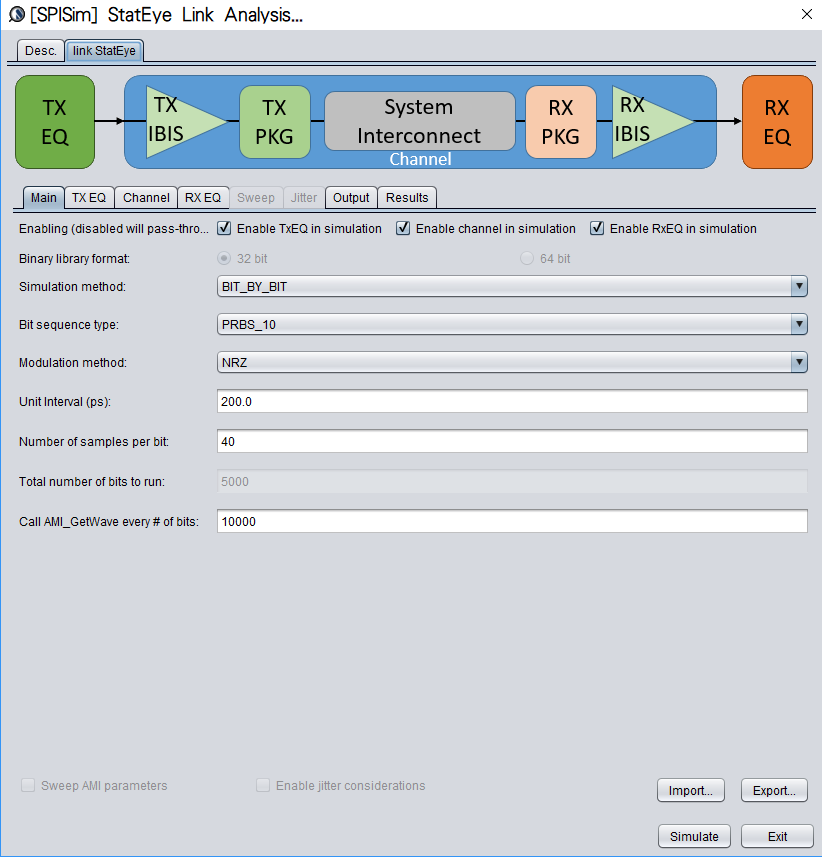
基本上就是把各模型及資料填入相關的tab裡, 再設定仿真運算模式(statistical or bit-by-bit)而後直接按”Simulate”加以計算;要注意的是如果所用EQ為非線性或時變(NLTV)如DFE/CDR之類的話,則仿法無法以statistical方式進行。凡此種種的程式詳細操作在其產品網頁已有視頻展示及說明, 故於此不再贅述。仿真數秒之後, 結果就會直接呈現: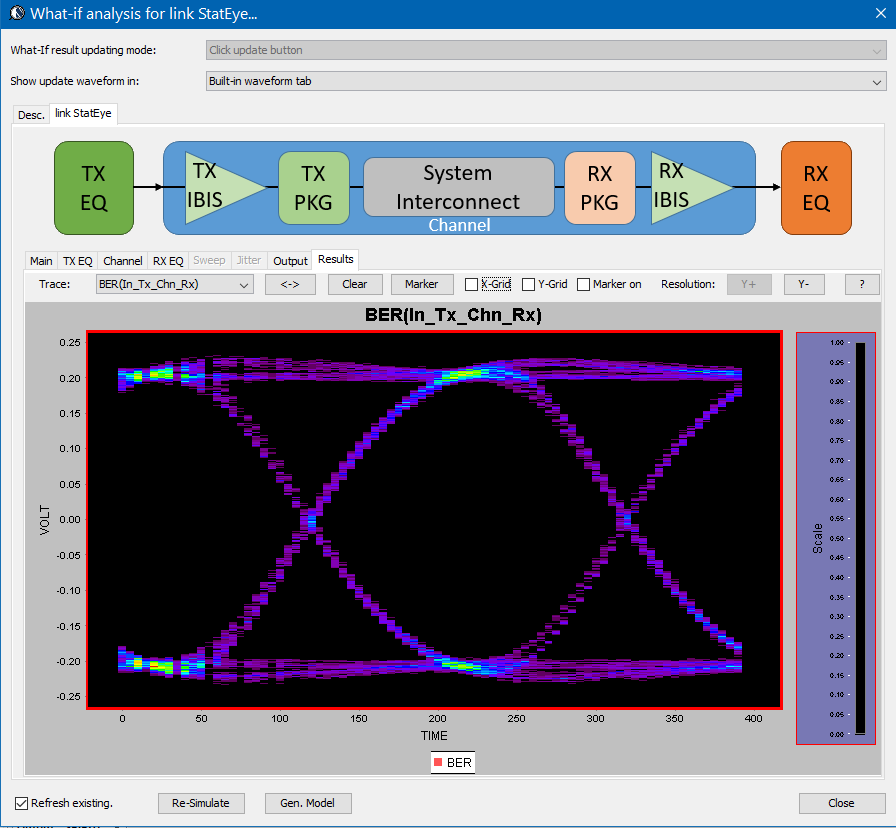
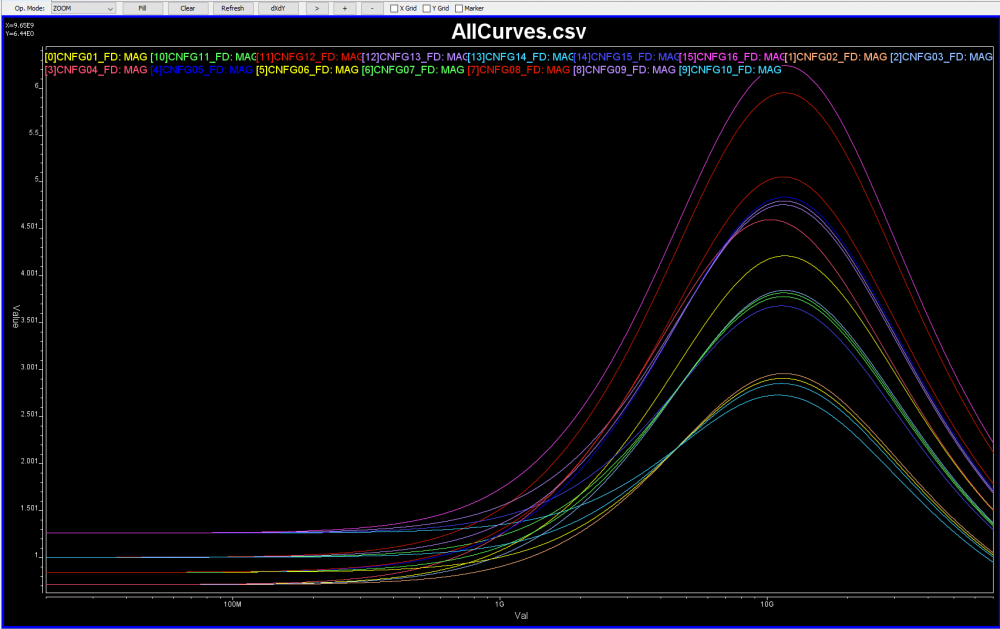
其它資訊如bath tub曲線等也會同時產生: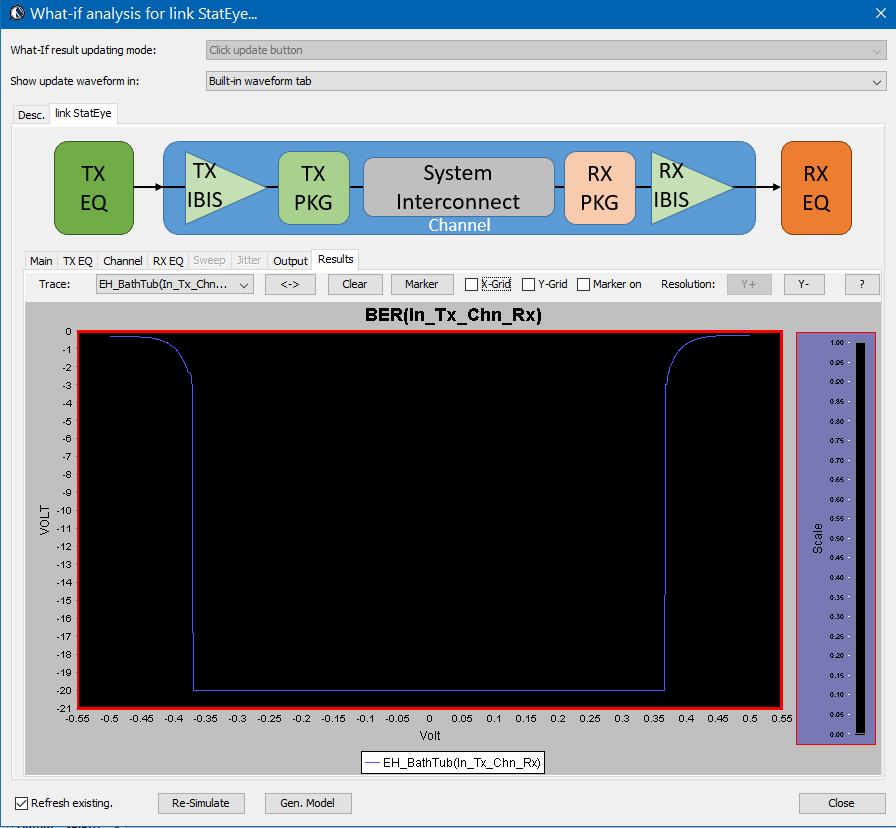
其實直到這裡才做的說明是通道分析的前兩步驟(取得響應及產出AMI模型)都可直接在這個程式裡進行,用處其中之一是可以直接對所要有的EQ參數就其對通道整體的影響直接做更改後再重新仿真, 而不用回頭先以SPISim_AMI產生模型再以本程式跑之; 比如說用戶可以直接透過簡易快速設定頁來更改TX端的TAB加權值: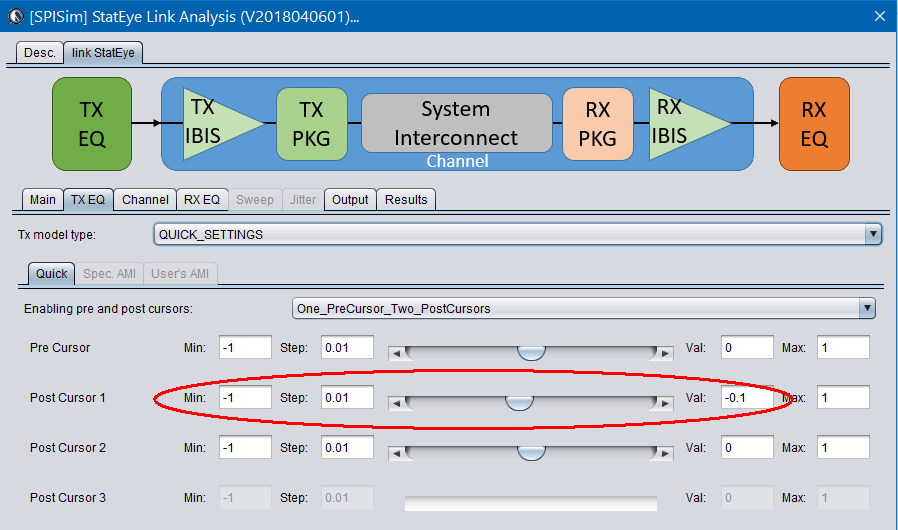
更改後再次仿真當就可見其在RX輸出端形成的效應: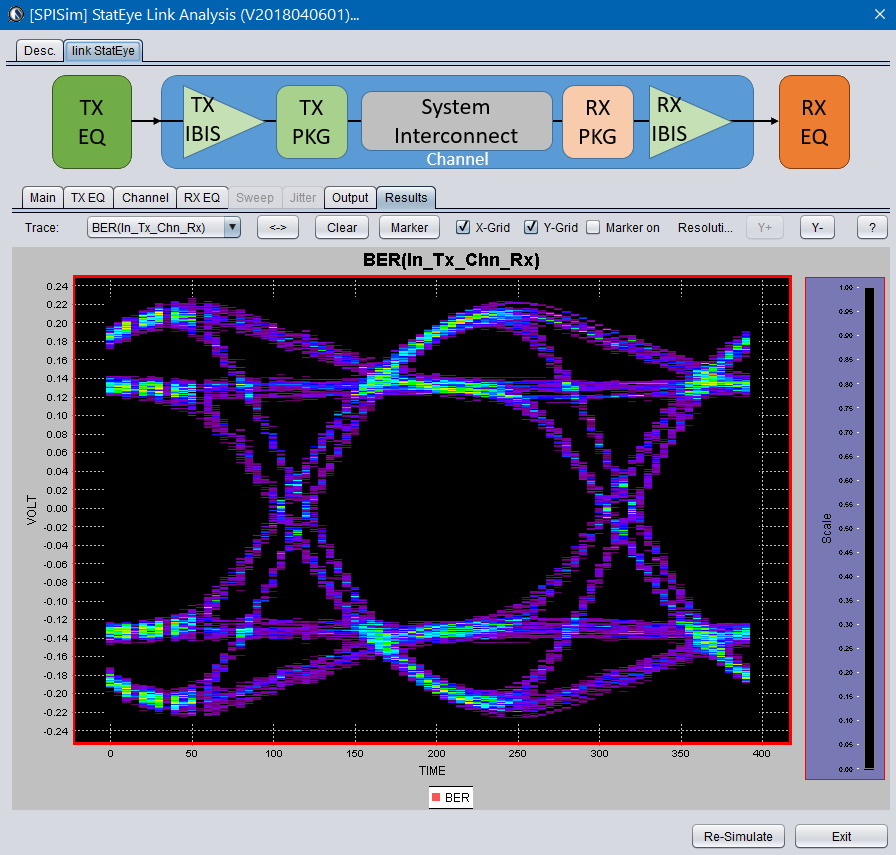
其次,對一系統設計工程而言,其也把從所用的IC設計商處得到的AMI模型置入本程式加以仿真;而對於IC供應商而言,如此產出的AMI模型即可馬上提供給下游的系統用戶在其所擁有的通道仿真器裡測試使用;本文討論至今,這一切的軟體都可直接透過所連結的網頁取得並使用, 用戶完全不用花一毛錢甚至是提供諸如EMAIL的個人資訊。
以上..一個經濟又快速有效的通道分析流程或可做為您設計流程上的考量, 也歡迎舊雨新知繼續提供本司意見及建議。