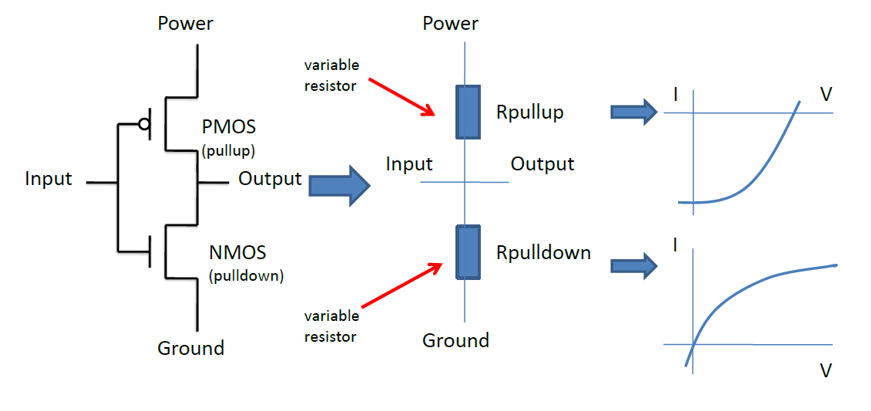
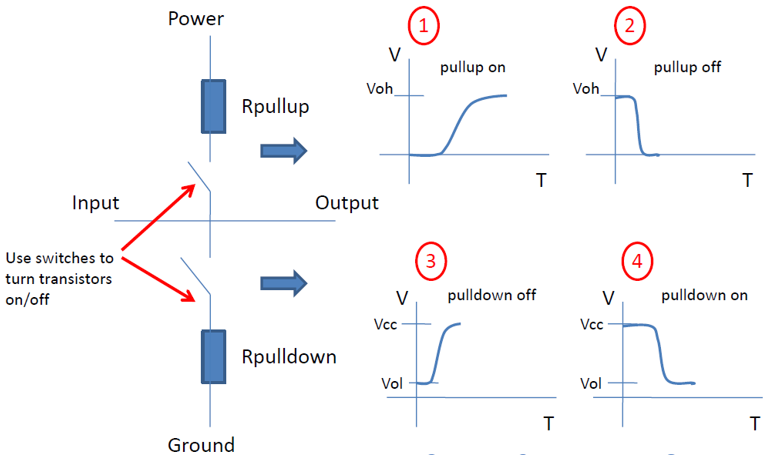
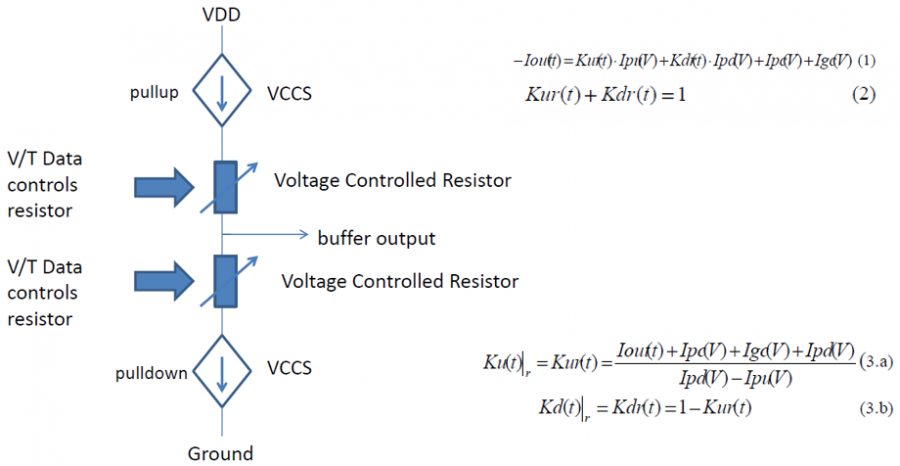
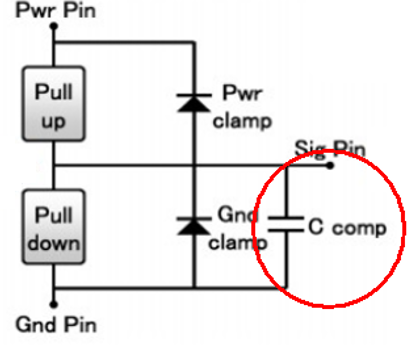
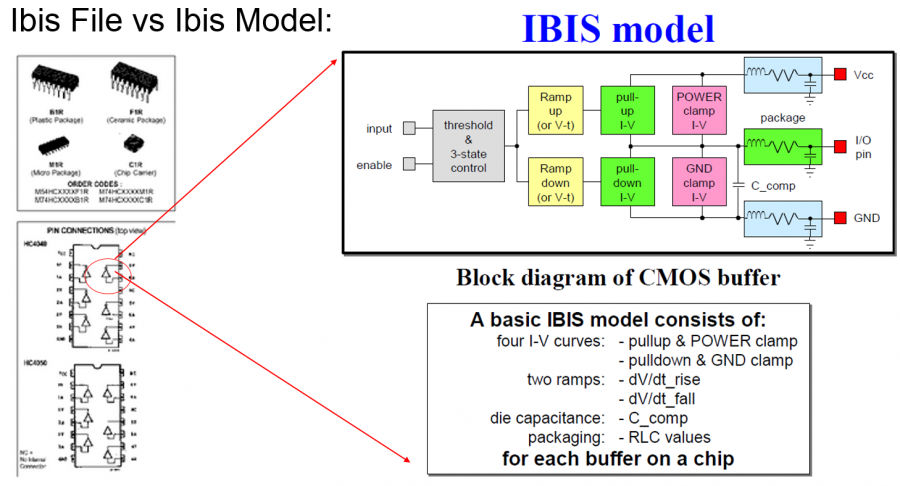
在上篇的貼文中, 我談到”IBIS cookbook”提供了IBIS類比部份建模的極佳參考資訊; 可惜在為EQ建模的AMI部份, 就我所知類似的cookbook則付之闕如! 要為AMI建模, EQ的理論部份需先導出其演算法、而後再以C語言將IBIS Spec裡的幾個API寫出來, 最後要把這些程式碼在不同的作業系統上編譯..Windows上是編成dynamic link library (.DLL), Linux上則是編成shared object (.SO), 由於不同的編譯器、不同的建檔程式(如make, cmake等)各個的操作指令又不同, 所以這些大都應歸類到資訊或軟體工程的範圍; 也因此其與此工作本質上的電氣/建模等重合性並不高。這也難怪要找到為這一切都寫有詳盡指示的教材或參考資訊實無異於緣木求魚。
在這篇文章中, 我打算略過這些”編程”的細節部份, 專以整體AMI建模的流程分享一些個人的想法。所有從頭到尾的步驟都希望能有所觸及進而能給讀者一個完整的介紹。大致上來說, 其依序可分為下列步驟:
- 建立IBIS類比模型
- 準備相關資料
- 定義AMI模型架構
- 實際進行編程建模
- 對單一模型做掃描測試
- 將模型置入完整渠道測試
- 編寫使用手冊
以下就分為各步驟做更深入的分享:
建立IBIS類比模型:
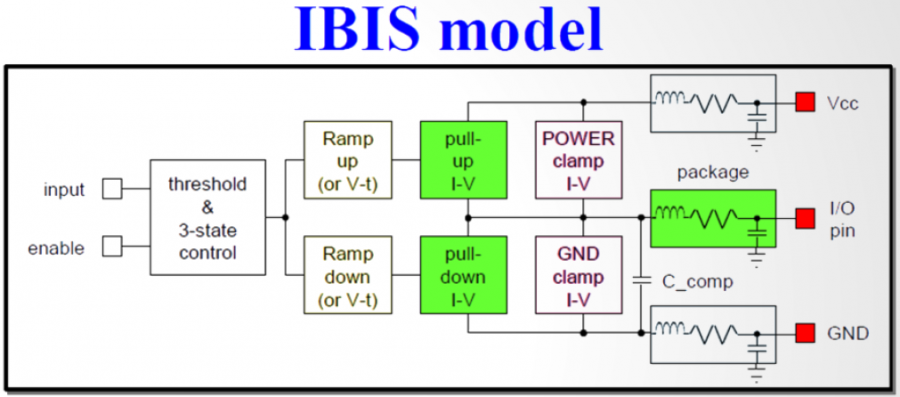
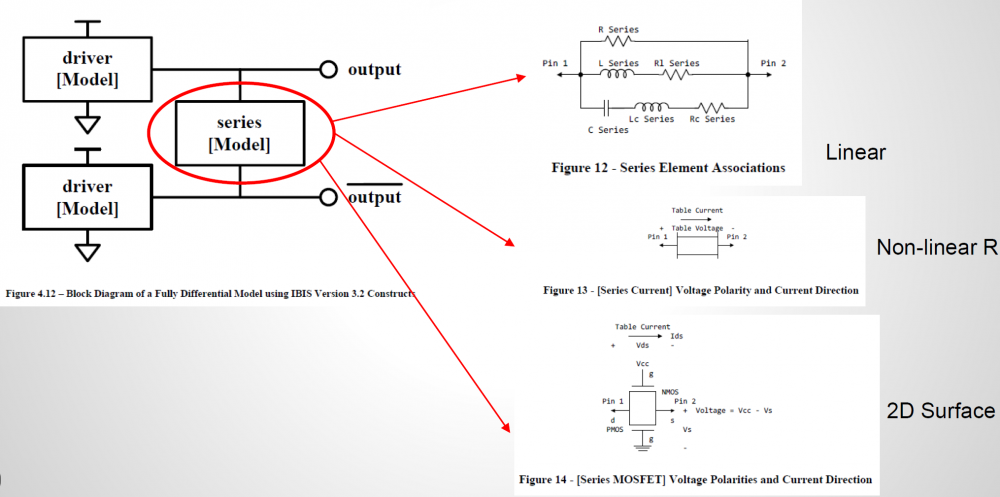
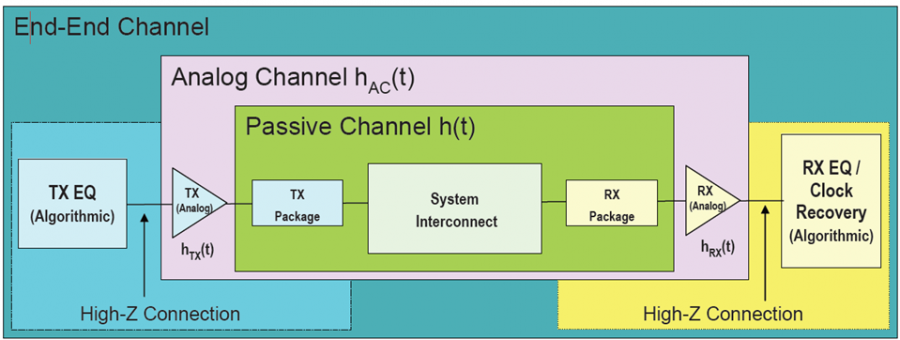
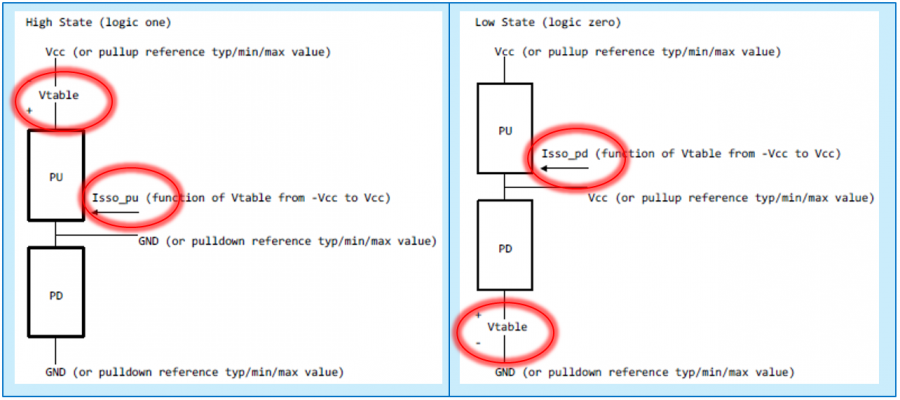
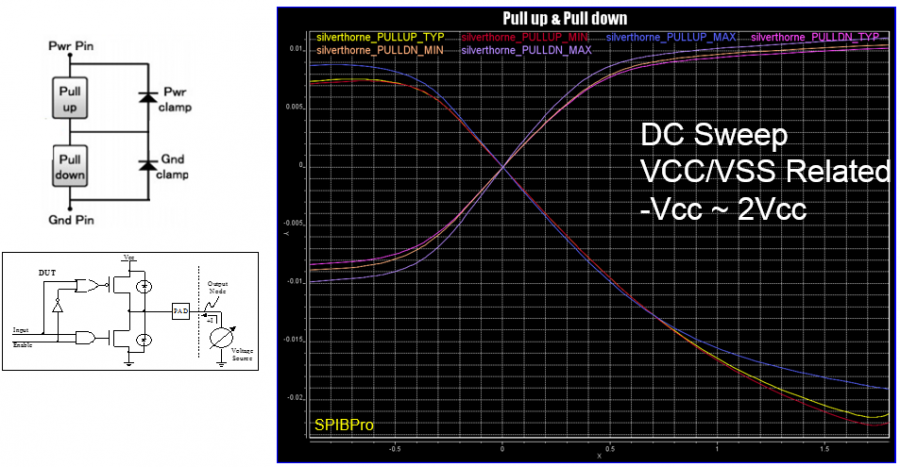
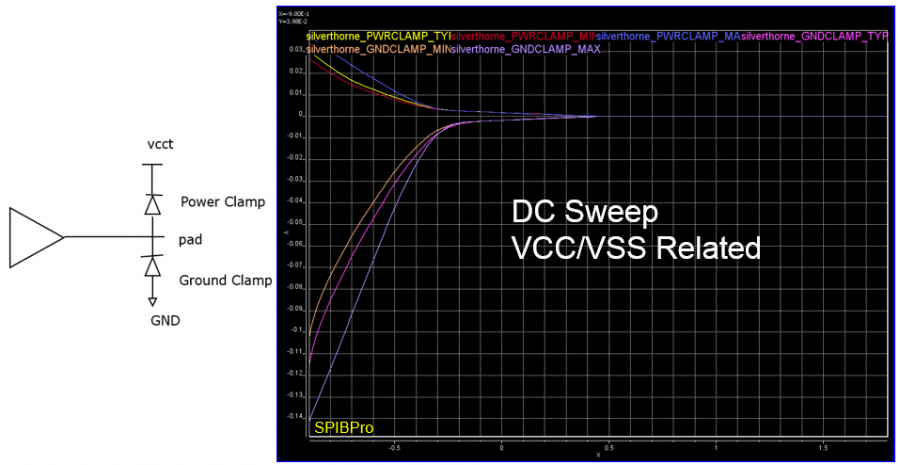
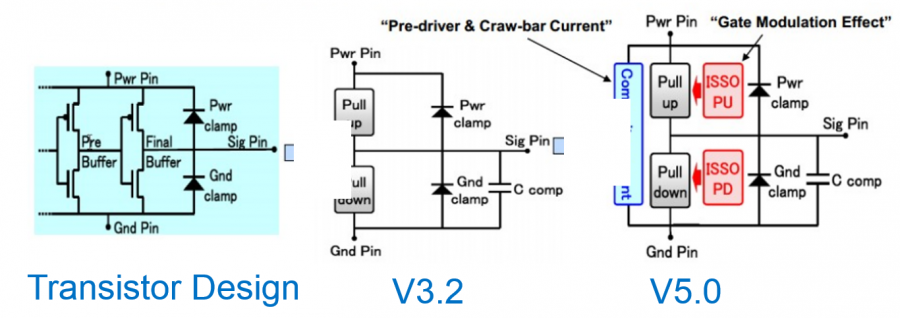
信不信…為AMI建模的第一步是要建出其類比的模型部份(也就是傳統的IBIS模型)。這點對於TX端來說尤其真確! 因為TX的EQ是要為”含有TX類比響應”的部份去做等化的, 也就是說:當連接TX及RX端的channel是pass-through時、且RX是TX的一般操作負載情況時, TX EQ要去做等化的等於是其本身的IBIS響應。 如果不事先知道類比響應為何, 是無法繼續算出EQ的各個參數值的。以下圖為例:
這是一個FFE 的EQ電路, 很明顯的是等化的de-emphasis部份為兩個黃色箭頭線所標示; 而為紅線框住的部份:其包含上升、下降斜率, overshoot/undershoot等信號細節, 以及dc的準位等等在在都是類比模型的結果。所以為類比部份精確地建出模型實為TX AMI建模的第一步! 除了IBIS之外, 最近也有BIRD194的倡議(其用S參數來描述類比行為), 無寧地..兩者都是同樣的意義。
對於RX而言, 問題則簡單得多。因為其IBIS模型大抵為ESD的clamp或是terminator外加差分電阻而已。所以不用在那花太多工夫就可實質進入為AMI建模的階段。凡此種種, 有興趣的讀者可見本司之前許多有關IBIS建模的貼文。
準備相關資料:
AMI建模的原始資料可以來自很多方面:比如說是電路的仿真、實際的量測抑或是datasheet等等。就仿真所得結果而言, 第一步當然是在確認仿真結果無誤之後為各個關鍵參數箤取出相關數據以便日後AMI建出來後做為第一步驗證的依據。
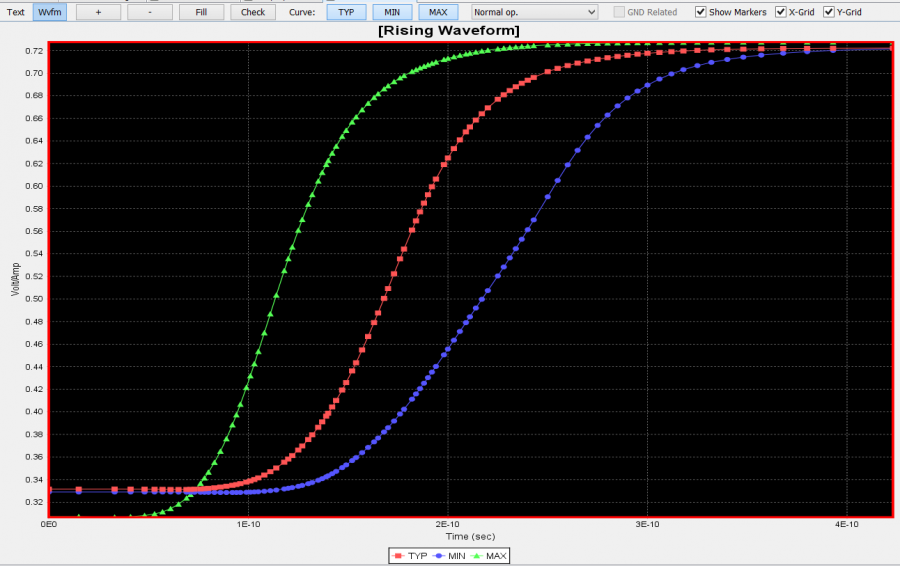
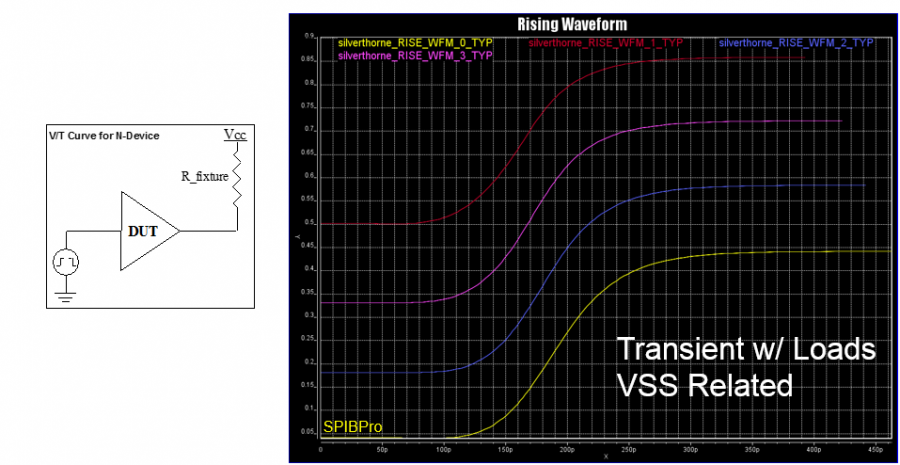
以下圖為例, 這是一個TX在不同EQ設定下的的圖型: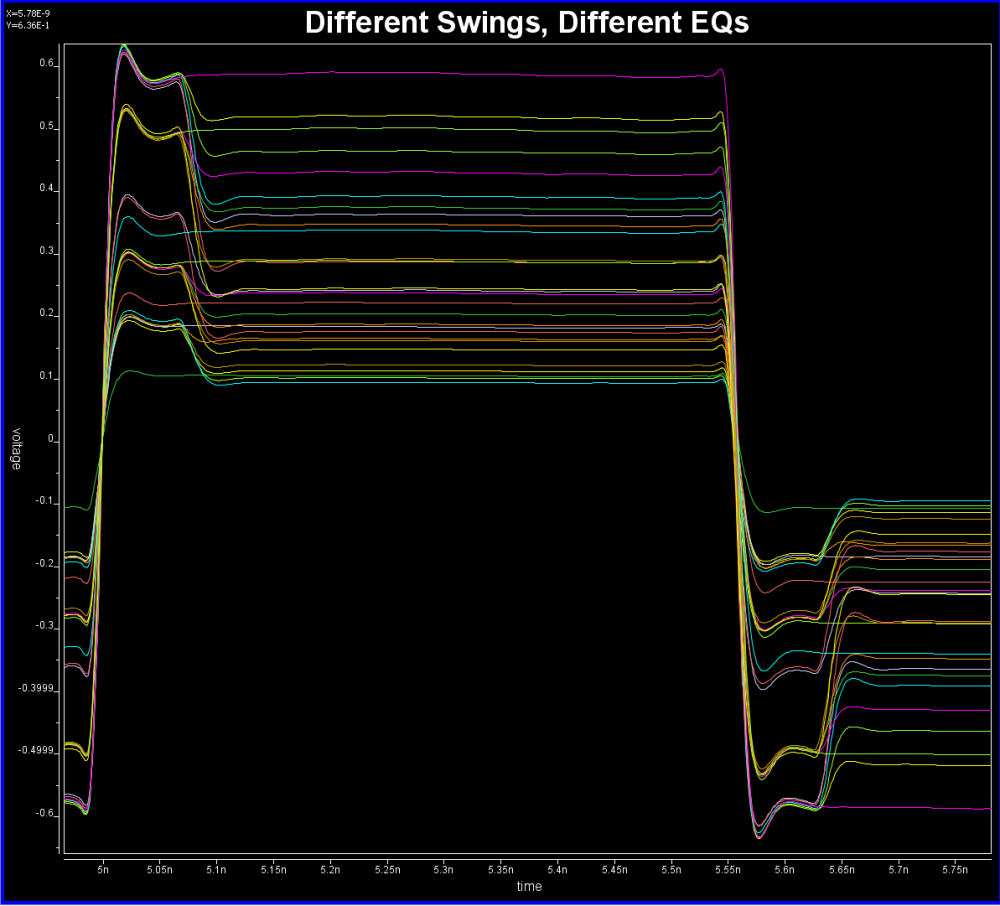
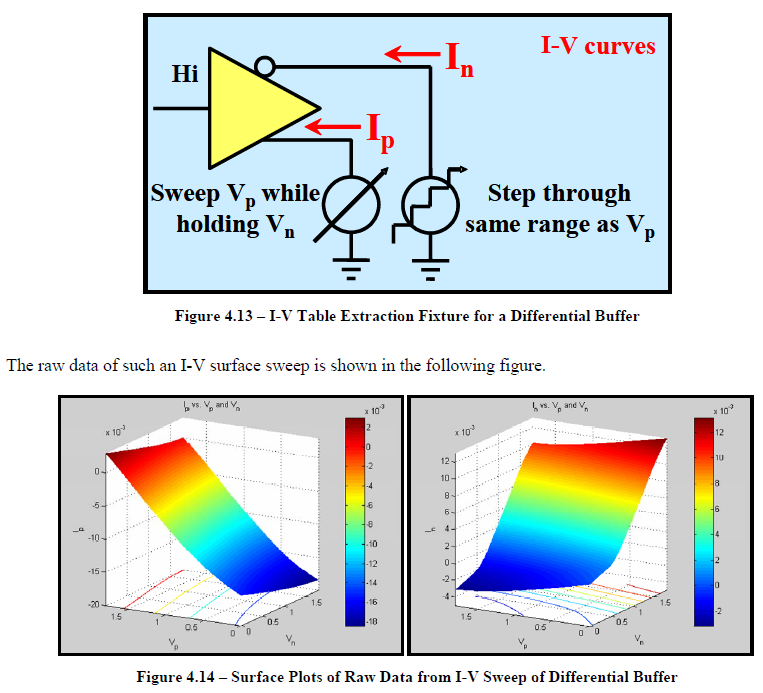
由於silicon設定上要激發出不同EQ的時脈未必相同, 所以得到結果後最好要把它們都對齊在某個時間點以便做批次的處理。利用本司的SPIVPro的話, 可以很快地為不同曲線在5.3ns時的值一下量出來並製表如下: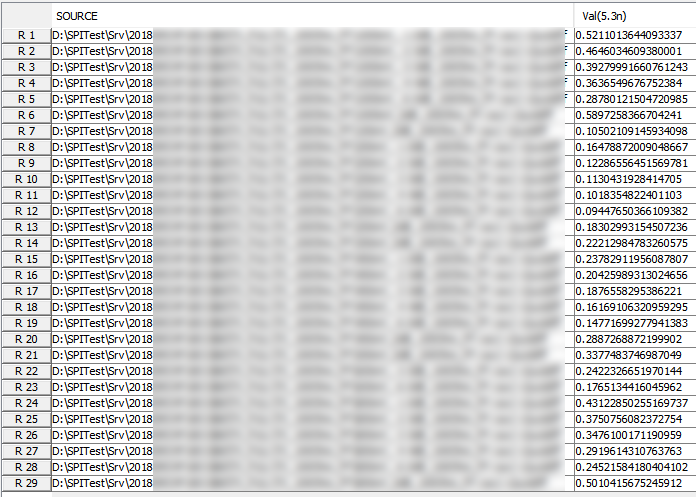
同樣地, 若是原始資料是lab裡量出來的波型, 則得加上手工的程序去量出不同的EQ值, 這點由於多少會有雜訊的緣故會比由電路仿真的流程更加費工且精確性較低: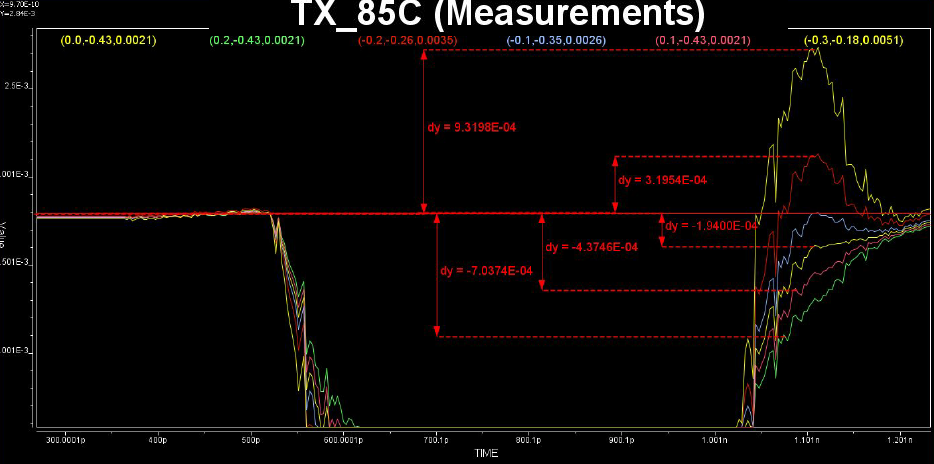
有些原始設計的效能部份得在頻域才看得出來, 所以在此情況下上述類似的程序就得在比如說DC, 5G, 10GHz等地方進行: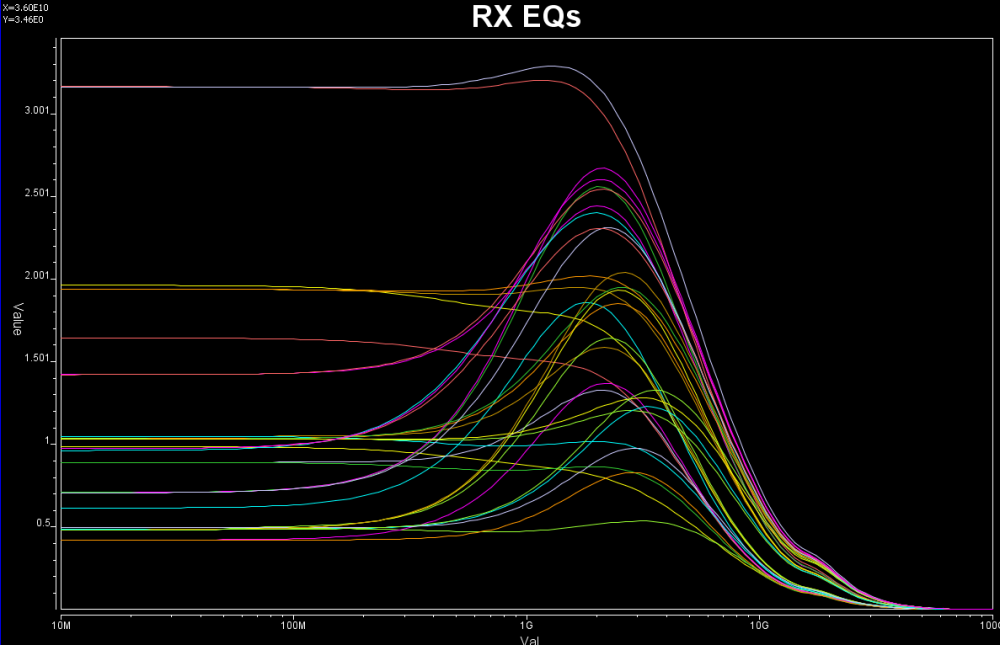
如果原始資料是元件的datasheet的話, 則建模的自由度較高。比如說不同的極點及零點的位置, 都有可能在同樣的頻率點得到極近似的響應, 則用那組資料就都可以, 也或許就要再參考一些其它的限制條件。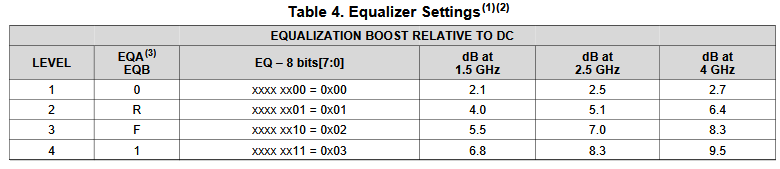
定義AMI模型架構:
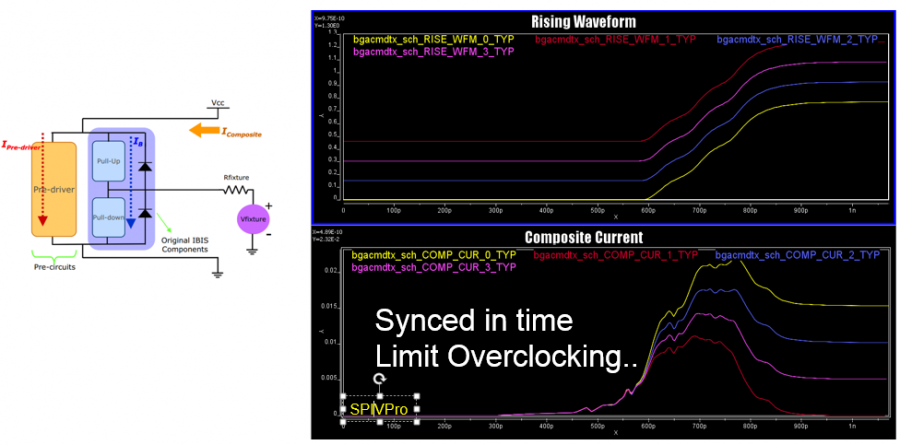
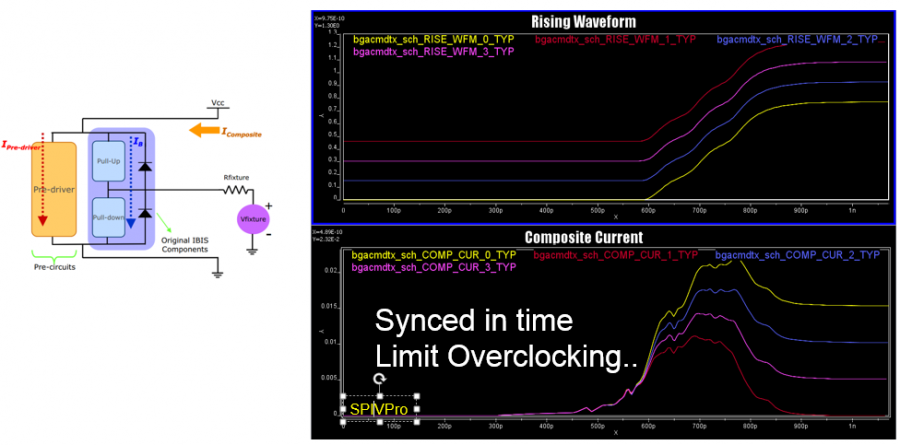
有了資料之後,下一步就是依資料的樣式來制定出AMI模型的架構。通當AMI的次要組成模組都得反應出原始設計的功能。比如說如果原來的設計裡有DFE/CDR的功能, 則AMI裡也少不了它們。但也有一些情況下, AMI的架構能有有不同的考量, 以下圖為例: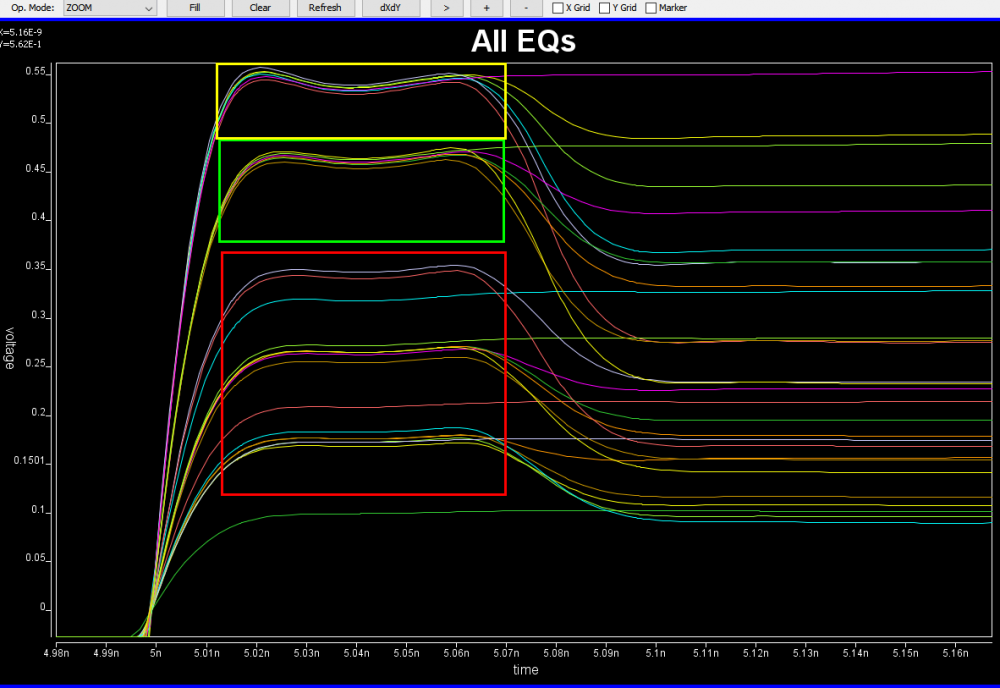
很明顯的是這裡面一定有一個post-tap的FFE, 但上面由不同顏色框起來的部份, 就可以用不同的方式來建模:如果你覺得這些波型都很進似, 則可以用同一個類比IBIS模型外加一個”縮放模組 Scaler”就可套出不同的振幅, 也可能這之間的斜率相差過大而必需由不同的IBIS來表示; 同樣地TYP/MIN/MAX之間的差異也可能用一個類似的Scaler就可以轉出來等等。對於一個repeater而言, 因為其同時具有RX及TX級, 所以EQ的那些功能放在RX那些放在TX也可以有一些彈性。在不同的使用狀況之下, 也很可能同一模型要以不同架構的形式來呈現才能順利被使用, 這樣的一個例子我也已在之前的貼文裡討論過。
實際進行編程建模:
定義好架構之後, 再來就是實際地編程了。如果這不是第一個專案, 那幸運的話可能之前已有類似的設計其源碼可直接拿來運用, 如果是新寫的話, 要注意的是是否夠模組化以便日後能再輕易地重覆使用。由於同一個AMI模型可能被建構多次(several instances)而同時被仿真, 故若用static variables/function的話就要考慮到會不會在不同的instance (相同的class)之間相互干擾, 對於不同的instance是否會位於同一個記憶體空間這個問題可以說每家仿真器的做法都未必一致。再者, 模型裡不要有hard-coded的數值…我就曾經見過一個模型其只能在某個速率下且每UI有32個取樣點的情況下跑…任何其它不同的設定都會造成有誤的結果甚或是crash, 這表示原建模者沒有把用戶不同的取樣、速率設定考慮進去而在內部做適當的up/down sampling。最後, 軟體工程內的許多標準技巧如unit testing, revision control, dependencies check等等也都要弄好。Dependency的部份在Linux尤其重要, 因為在那作業系統上的很多函式庫都是放在lib\之下共享的。也就是說如果模型源碼裡有用到某個外部函式但在編成.so時又沒有做靜態的連結, 則原來在建模工程師電腦上運作無誤的模型拿到另一使用者的環境下就不能跑了。這種情況下,大部份的時候我們都要準備好幾個電腦(可用虛擬機), 裡面只裝有不同distro的OS最開始裝好的情況(所以所有的函式庫都是最基本的)且是吾人所願意支援的最古老版本, 再在那之上去編譯模型的源碼。
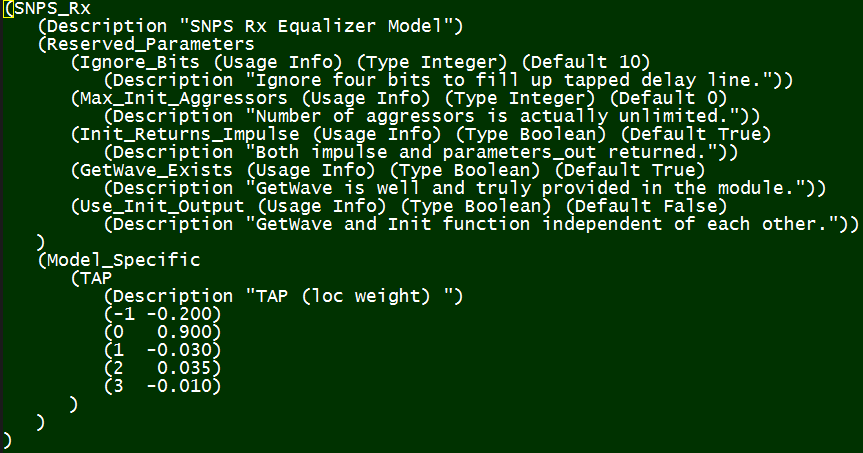
有了二進位.dll/.so之後, 再來就是寫純文字格式的.ami檔;這裡沒有一定的格式…有很多不同的語法都可以拿來讓用戶設定某個AMI參數的值及範圍。又由於不同EDA的仿真器對呈現這些AMI參數及其選項的方式都不一樣, 所以通常要先選定一個主要支援的EDA軟體再以那為本來編寫。最後, 由於IBIS本身就有TYP/MIN/MAX不同的CORNER, 所以在寫AMI時若其也有類似的CORNER則也要一齊列入考量, 否則用戶選MAX的IBIS來套上MIN的AMI就出錯了, 也就是說它們之間需要能同步”Synchronize”。
模型都準備好之後,再來就是參數的調效, 之前有提到源碼最好能重覆使用, 所以不同設計所會用到的不同參數就不應直接寫在源碼裡而應以外掛的方式讀進來, 在這裡就是建構這外部參數的步驟。有些界面…如PCIe, 其對FFE的不同tap值都有預先定義好了, 則這裡就沒有什麼變化的空間。更多的情況是有的是仿真或測量的結果而建模者需一個一個地去找出相對應的參數, 如果用手動的話可以說是煩瑣且曠日廢時又精確度不高, 記住..這裡可是有可能多達幾百甚至是上千組設定的, 最好的情況應是用如本司軟體的”Auto-Tune”來自動的調效: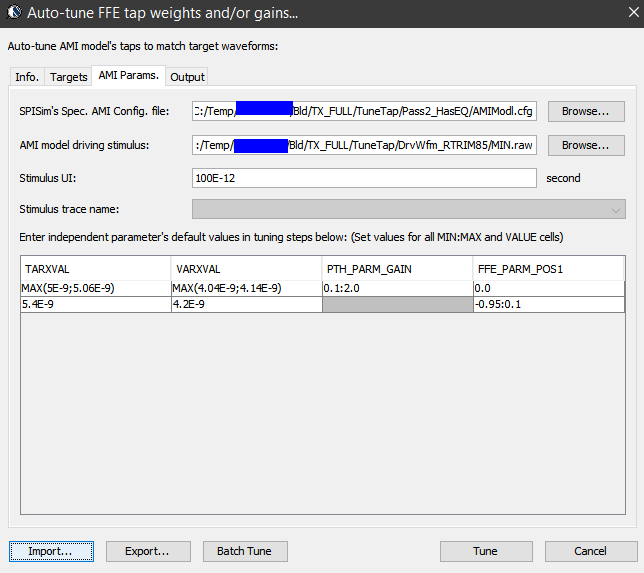
基本上本司程式會先把目標波形及時間點量自動出來, 而後透過二分搜尋的方式漸次地調AMI參數使其逼近至目標值至一個範圍內, 而後直接將結果製表。這樣的流程即使是上千組的參數也能在幾分鐘之內完成。
對單一模型做掃描測試:
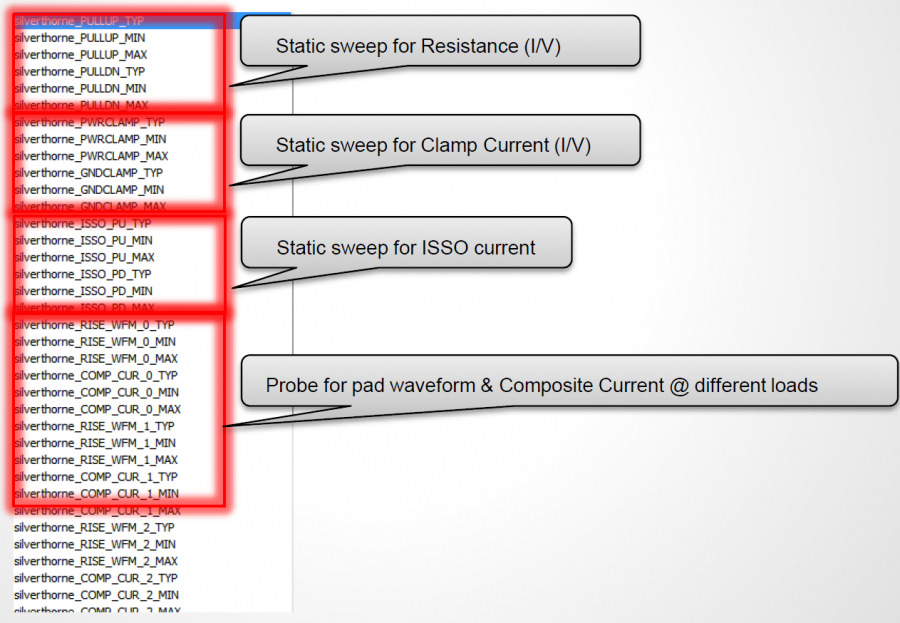
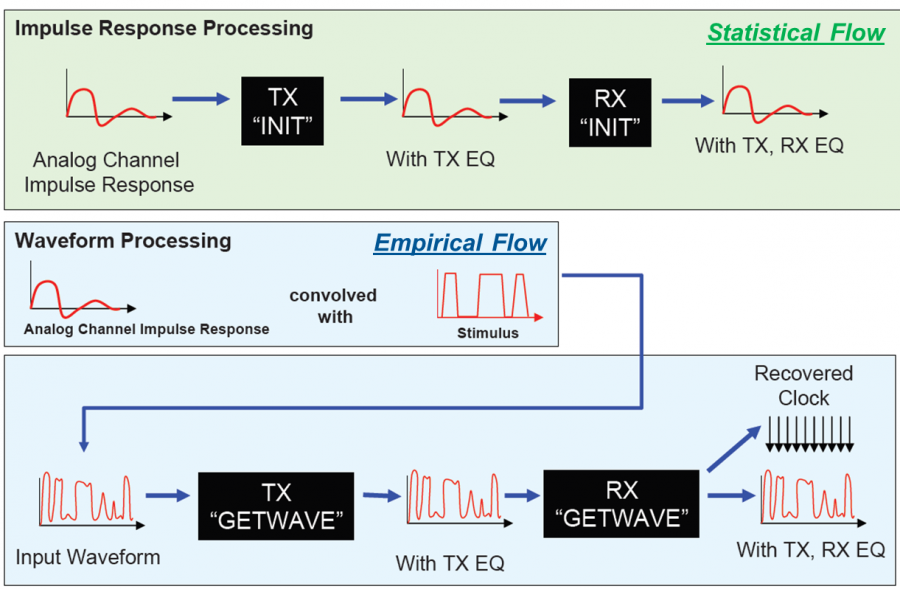
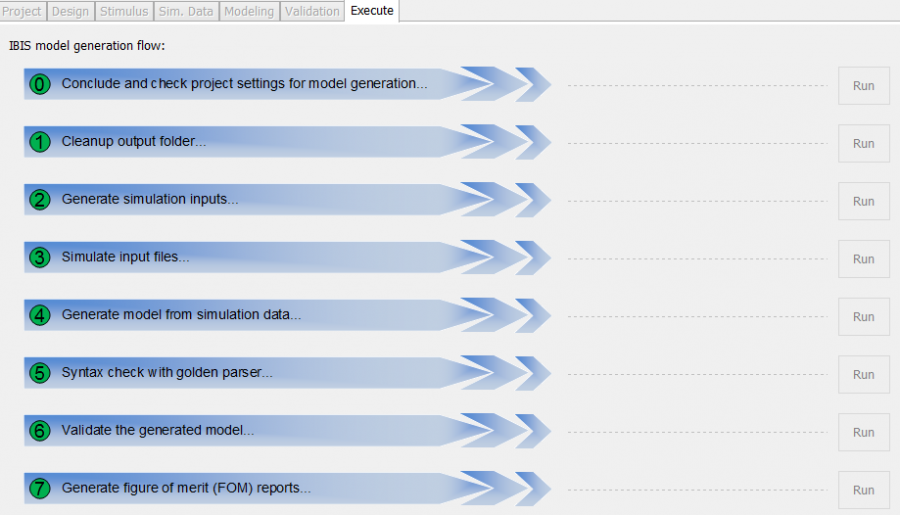
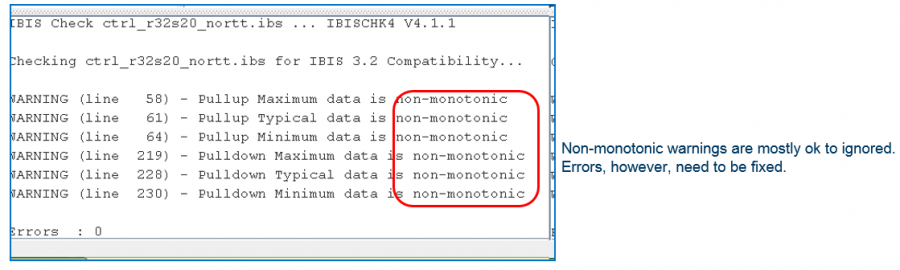
這裡要進行的是為單一模型驗證的程序。就如同為IBIS建模一樣, 有了AMI模型之後將其和IBIS部份連結起來再來做的就是用Golden Checker進行語法上的驗證; 由於不同的二進位AMI模型在不同的作業系統上載入的方式都不同, 所以這一步驟得分別在不同的作業系統上分別執行:
IBIS官版的golden checker是直到近兩年才有載入AMI模型的能力; 其所做的是先讀且驗證IBIS檔之後, 再看那個IBIS模型有用的AMI的部份而順藤摸瓜去把相對應的AMI模型也讀進來並測試載入, 要強調的是它們只做載入的動作而不會試著去驅動, 所以功能性的測試還是得另外做。無疑地, 尤其是在Linux上的dependency問題在載入的時候就會顯現出來, 所以這個程序在有釋出Linux版本的模型時是少不了的。
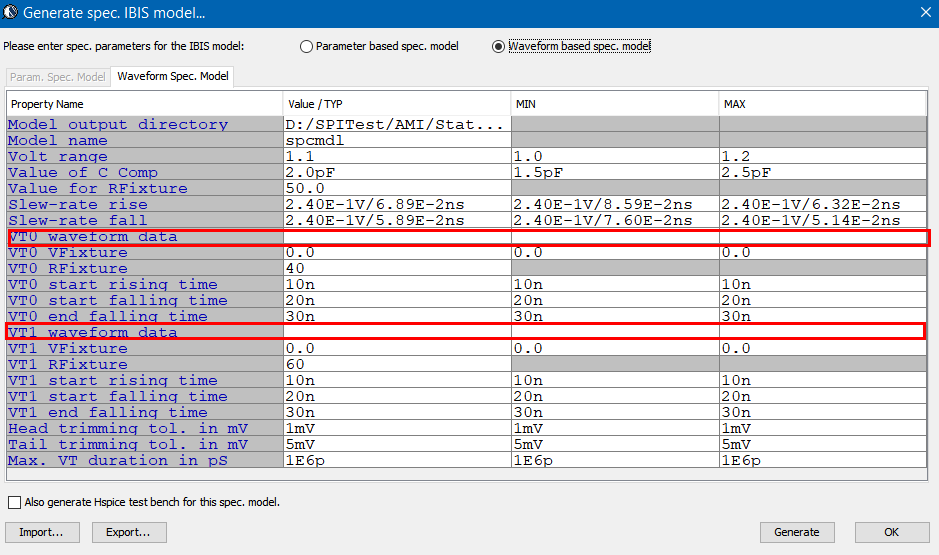
再者, 一個AMI檔可能會有好幾個參數, 且每個參數都會有幾個不同的值; 要完整的測試模型本身, 不可或缺的是要把所有參數所有值的不同排列組合都要跑過。本司的做法是先把.ami檔裡的變數”參數化”(如下圖紅框內, 首尾加入%):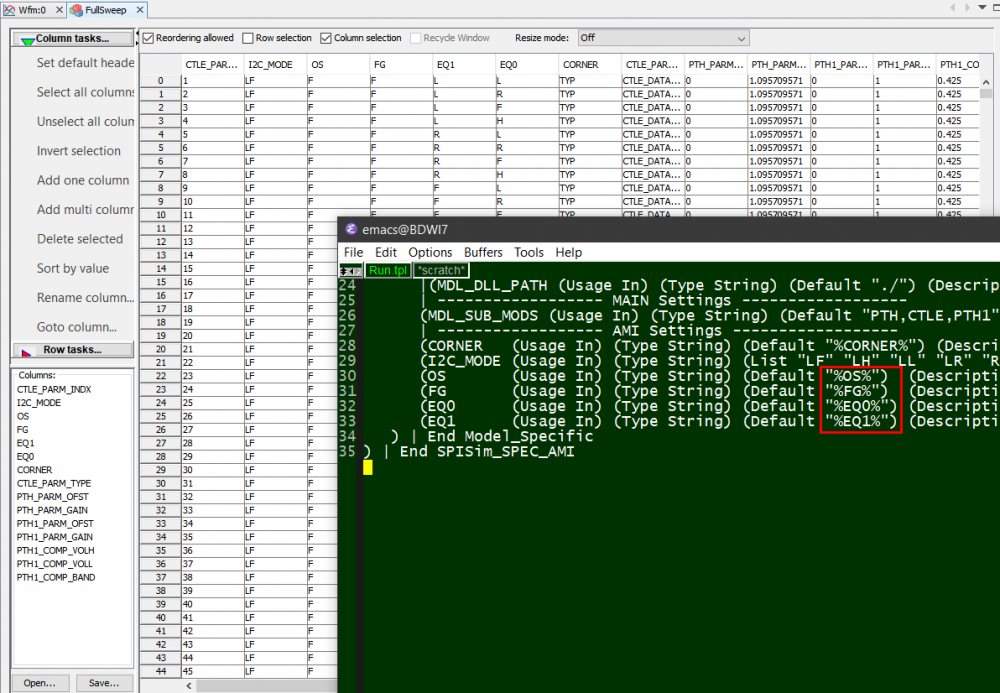
而後用像我們的SPIMPro把不同參數不同值完全的排列組合都列出來, 再來就每一個組合把AMI檔內的變數取代填值, 最後生成不同的.AMI檔案。就這個流程而言, 其很像是我們做SI時所用的系統分析法(探討於此篇貼文);而當有了這麼多不同的AMI檔之後,我們就可以對同一AMI模型做不同參數下的驅動。 取決於所用的EDA仿真軟體, 要能快速有效的批次執行這麼多次可能並不簡單, 、即便可能也是要透過腳本(script)的編寫, 所以非得先廢上一番功夫才成。就本司軟體而言, 這些功能都已內建於SPIMPro及SPIVPro裡, 所以可在一個環境下不寫腳本就成批次完成。此處用途廣泛的SPISimAMI 模型驅動程式也是不可或缺的角色!
當每一個AMI檔都被用來驅動.dll/.so模型之後, 就會又有數百甚至上千的波型檔待分析, 要做的就是一樣批次地把關鍵值量測出來: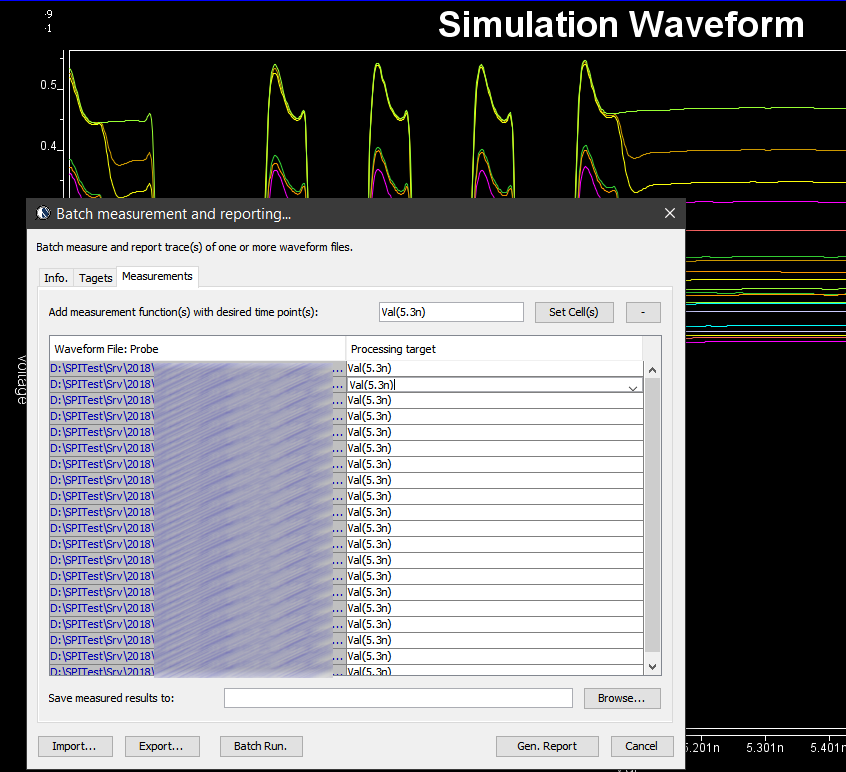
而後再與原始資料相減而得出delta的值或比率, 把這些點以圖形呈現出來就可以很快地看出在那些設定下誤差值較大, 如果有明顯的錯誤的話(比如說沒值可比…那就大概表示驅動AMI模型時大概crash了), 就又要回到前幾個步驟找出問題而後重走流程一次…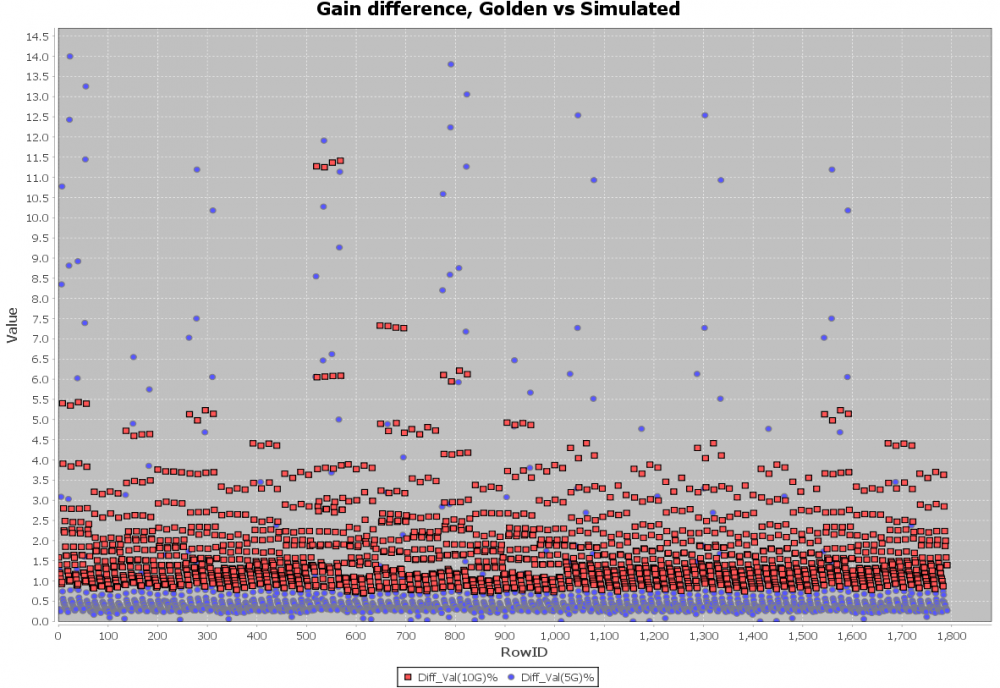
將模型置入完整渠道測試:
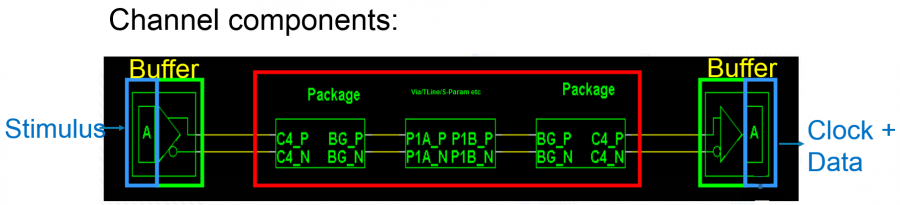
剛剛所提的模型驅動是單就其本身, 當然最後不可少的是也把其它的相關部份帶進來組成一完整的渠道或設計做全面的驗證。這裡有一個重點是AMI的仿真所呈現的結果都是在時域上的(不論是透過statistical或是bit-by-bit的方式進行), 所以對於有些響應是在頻域上的元件(如CTLE)等來說就不是那麼地直觀可驗證。一般的情況下我們會用一個相對應的原始元件(比如說一個S參數, 其Sdd12就是我們CTLE的頻響)來做:蘋果對蘋果的比較, 這樣來看驗證就直觀得多。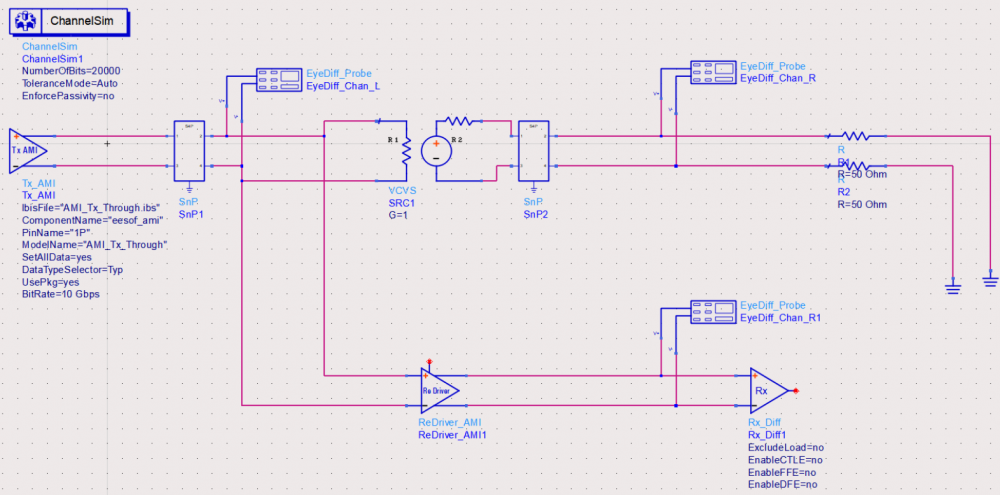
另一也不可少的步驟是把建出的模型在不同廠家的EDA軟體上跑過至少一次且確認結果無誤。這點也可能有其難為之處…因為這類的EDA仿真器不在少數, 隨便一算就有ADS, HyperLynx, QCD, SystemSI, HSpice等等, 每一項都花費不貲, 實際上即使是大公司, 也很少有見到會願意或有需要將它們買齊的, 所以就本司而言, 得串連其它的SI顧問相互支援。舉例而言, 同樣的DLL_PATH保留關鍵字有的仿真器傳進來的是絕對路徑、另有些則傳入相對路徑。如果所建模型用到這參數的話, 未對兩者做相同的支援就有可能會跑出不同的結果, 所以不走這步, 所建模型對其它未測廠家仿真器的支援程度便很難說。
編寫使用手冊:
走到這裡, 最後一步就是寫模型操作手冊了。一般來說, 會包括的資訊最先開始的就是類比IBIS模型的部份, 比如說那個針腳接到那個模型, 其AMI的部份為何等等, 最重要的資訊是AMI參數的名稱、值的範圍及描述等等; 對於如果所用仿真器不支援某些保留字時的應變等等也要提及(比如說如果仿真器版本較舊而不支援DLL_PATH/DLL_ID, 則模型是否有其它的AMI關鍵字可用來做相同的設定), 再者, SILICON或量測值與模型跑出的眼圖相較也應置於手冊之中, 最後一項是對主要支援的仿真器、欲使用所建模型的簡易設定為何等等, 凡此種種, 都是一個完整AMI建模專案所不可遺漏的。
結語:
本貼文與讀者分享了本司為AMI建模的一些必經流程。C/C++編程的部份自是AMI建模重點之所在但需另外觸及的..故不在上述之內。不論是AMI API的參數、設定抑或是編程所用的語言(如C/C++)都是一直在與時俱進且不斷演變的, 所以身為一個建模者, 就得時時去汲取相關的新知以便能最有效的建出精確的模型, 而不同軟體、函式庫或是作業系統的限制與運用也在在都是相關的課題。在看過此篇分享之後, 不知讀者是否仍對親自建模而感到興致昂然?…或者覺得乾脆委外於我由本司為您效勞? 祝您建模愉快! 🙂