前言:
近幾年來在IBIS-AMI建模討論上常被提到的課題一是透過back channel來對Tx或Rx或兩者同時優化, 目的是要找出一組最佳參數的組合以使channel的效能達到最佳化。至今為止的IBIS Spec並無法對此一流程做出定義及支援, 所以資料的交換僅限於仿真器及各個模型本身、而非模型與模型間。除了這點限制外,建模者也常常會遇到下列一個或多種狀況:1. 仿真器及參與運作的各模型間對Spec.版本的支援並不一致, 2.其IP來源可能是不同的矽智財供應商 3.可能核心部份所編寫的語言也未必一樣, 比如說可能是用matlab的P-code; 在這些情況下, 常因為程式源碼的不可得而必需遷就現有建好的模型或檔案, 則要進行不同模型間的co-optimization也就更困難了;為了克服以上所提到的問題,我們可以利用proxy 類別來進行AMI模型的分析或實驗。
本文係為在2017年DesignCon所欲發表的同名文章準備所寫, 連同發表的簡報檔案及屆時的錄音, 已於此文的底下加入連結以供向隅者下載參考。
AMI流程裡的物件角色:
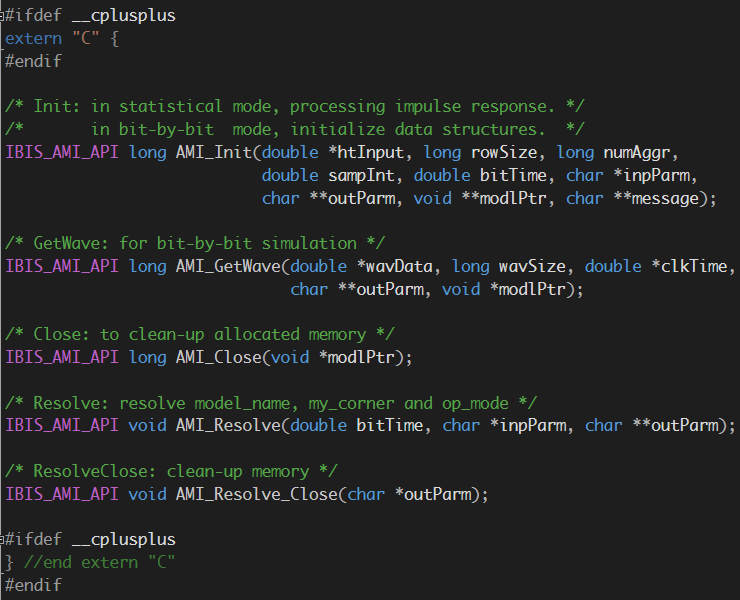
IBIS Spec.的讀者不難發現:在第十章(Algorithmic Modeling)裡所談到的都是參與AMI流程裡兩個物件角色的分責及應用;這兩個角色分別是1. EDA Tool (常是仿真器), 2.一或更多個參與仿真的AMI模型。AMI應用程式界面裡定義好仿真器需將以.ami為附檔名的參數檔讀進並做範圍及型態上的檢核, 而後將Model Specific的部份以資料對(key-value pair)的格式傳給相對應的模型。在模型與模型之間,並沒有可互相傳遞訊息的機制。
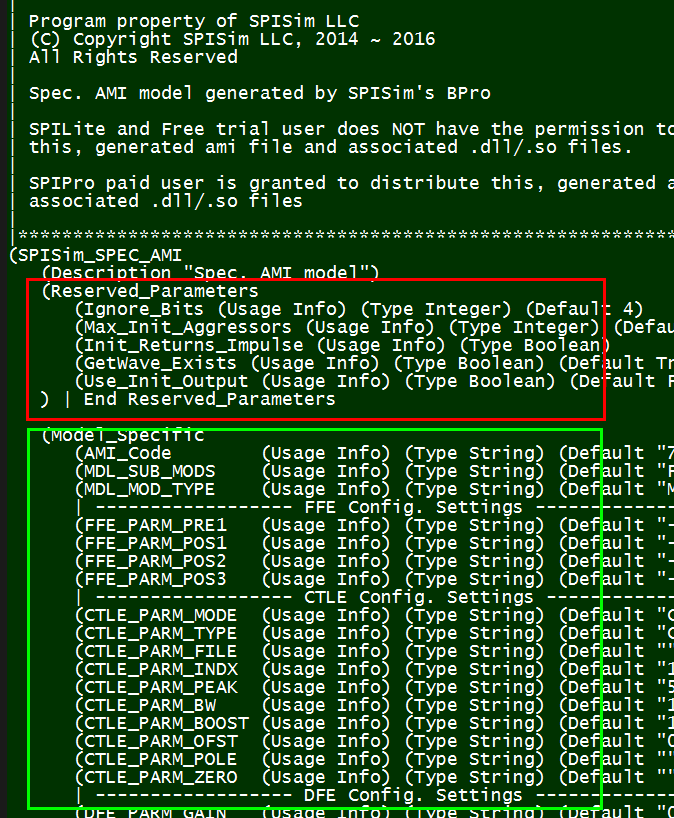
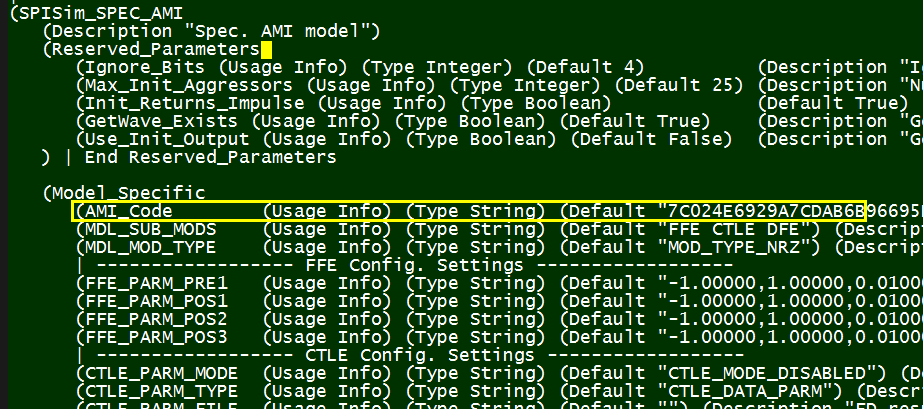
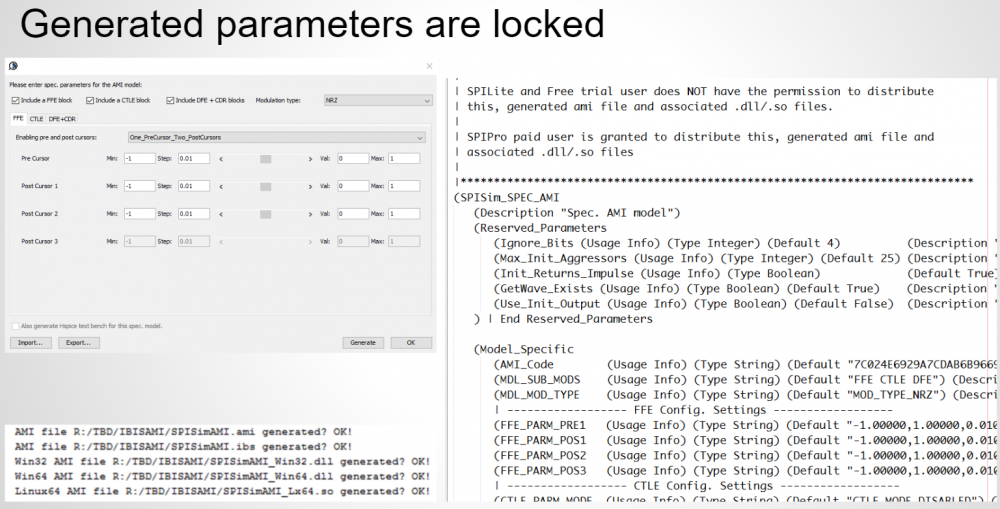
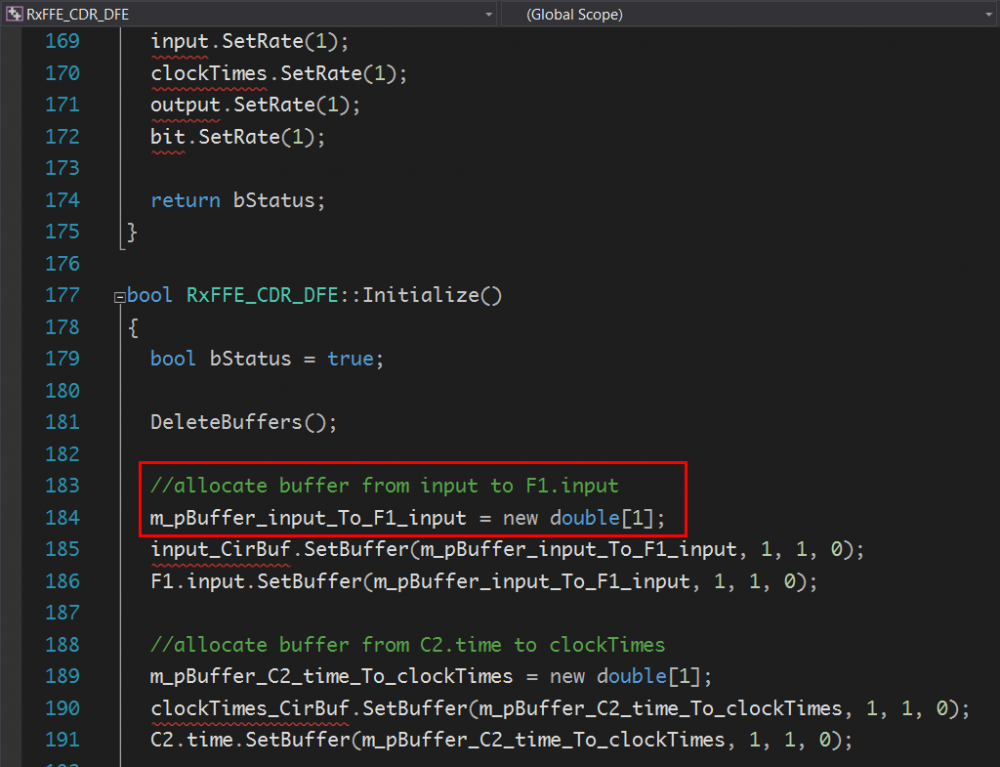
以上述.ami檔的內容為例, EDA軟體得負責讀入此檔, 然後因為”GetWave_Exists”設為True而了解到此模型有AMI_GetWave的函式的存在, 其次因為Use_Init_Output設為False故知在仿真過程中應呼叫AMI_GetWave來做資料上的處理而非透AMI_Init來進行。在此之外的Model_Specific部份則非EDA Tool所需考慮及了解, 而只需將其Parse成資料對傳入模型: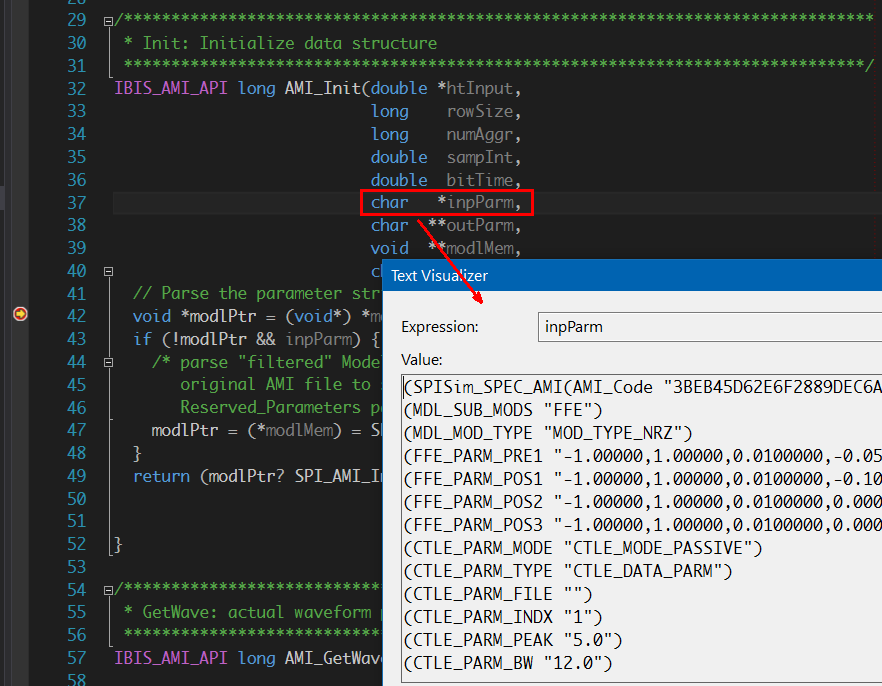
當我們用除錯器在API函式入口設break point後,便可看到由EDA軟體傳進來的值, 其格式已和原.ami裡的不同。這裡要強調的是如果建模者的函式原始宣告與API定義的不符,則EDA軟體是無法對這模型的.dll/.so進行加載而在這break point裡停下來的。
透過最近新加的back-channel interface (BCI)提案, 新的AMI API函式也有所新增及改變以便能支援不同模型間的相互資料交換: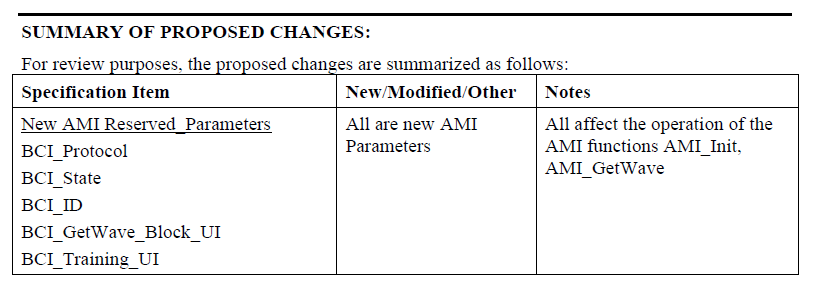
對此有興趣的讀者可至IBIS官網找到BIRD147.1_Draft的相關文件做更深入的了解。簡單言之, 各模型間可利用此新的協定以實體檔案的方式來交換資料。而由於這些AMI參數是新加的, 也就需要為所使用的仿真器支援才能開始運作。
過去幾年來幾間EDA廠商已為這BCI的運作模式進行角力…有興趣的讀者也可在這兩年IBIS Summit的相關發表文章裡找到資訊, 大略言之, 他們對下列幾種情況的見解有異:
- 如果舊的AMI模可無法重新編譯, 也就是說它們停留在舊版本的話, 則不同廠家所提供的AMI模型要如何一起運作?
- 對仿真器而言,其是否應主動地介入不同模型間優化的過程, 或是讓模型自己跑就好?
- 不同模型間優化的協定是否應成為IBIS Spec的一部份或只要參與模型自行設定、相互了解即可?
在此之外, 我們認為下列的情形也構成co-optimization流程的鴻溝:
- 做為一仿真器的研發人員(就是有仿真器的源碼),我如何用手上現有的AMI模型做co-optimization的測試
- 做為一AMI建模者而言,我所用的仿真器可能不會每年更新, 那我要如何測試現有的模型以確保其可使用BCI協定無誤?
- 做為一AMI模型的使用者言,我只能得到仿真器後處理後的結果,但若其有誤, 我如何能檢查仿真器及各模型間相互傳遞的資料以便偵錯?
凡此種種,都可利用Proxy類別的物件來做處理, 以下就為此一構想做更詳細的說明:
Proxy類別:
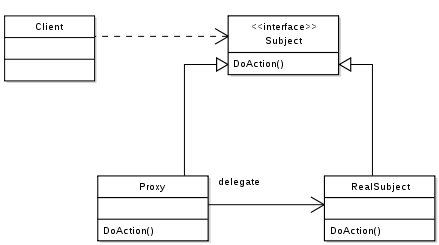
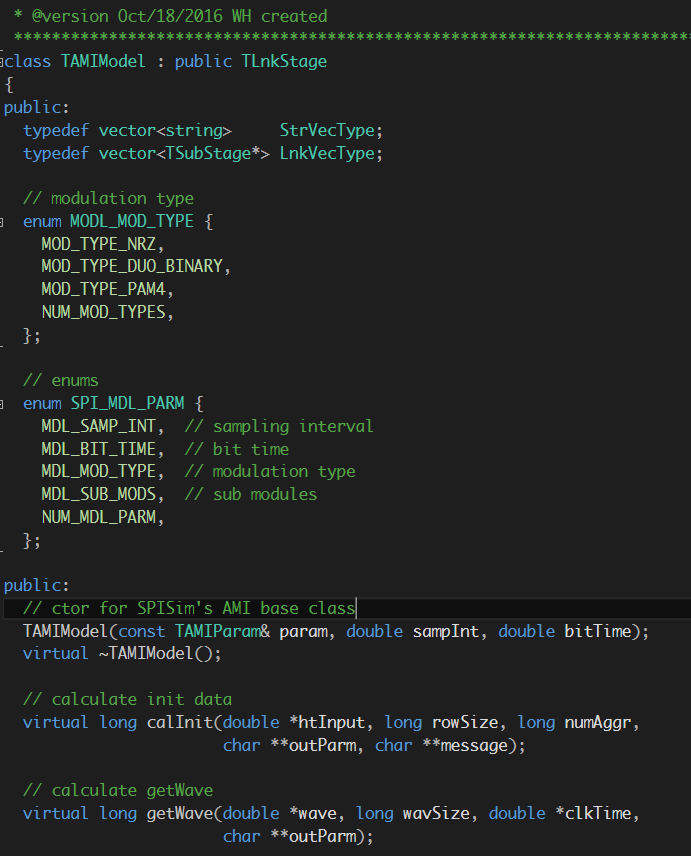
上圖所示為Proxy的UML, 最上方的虛線代表的是”has a”的關係, 而下方的垂直實線代表的則是”is a”的類別繼承關係,這UML可解讀為:”一個Client有一個或多個的Subject, 每個Subject都有繼承界面並執行DoAction的方法, 其中的一個物件是個Proxy類別, 當Proxy的DoAction被呼叫時, 其又轉而呼叫了RealSubject的DoAction函式”
把這種關係套到IBIS-AMI的關係裡, 則可解讀為:”一個EDA軟體可加載一個或更多的.dll/.so, 其每個都有合乎IBIS-AMI API的函式如AMI_Init, AMI_GetWave及AMI_Close等, 其中的一個.dll/so實則為Proxy物件, 當其API函式被呼叫時, 便轉而呼叫RealSubject (即實際運做計算的模型)的AMI-API函式以做資料處理“。
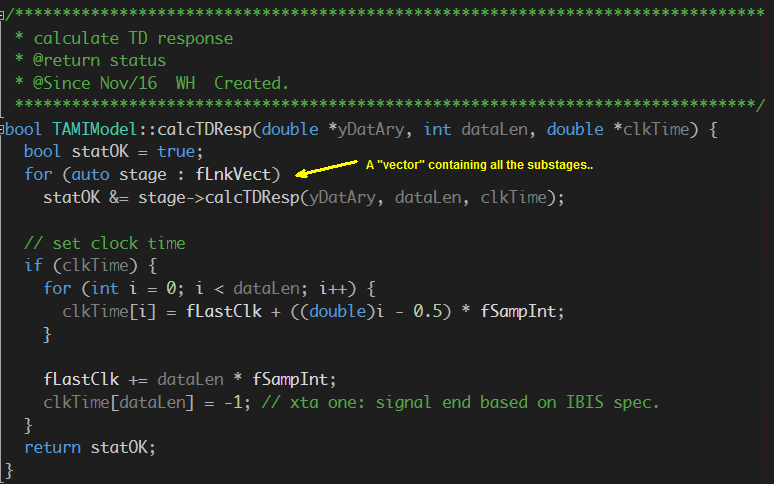
所以Proxy類別或物件可視為一個包在真實模型之外的wrapper, 這個proxy物件雖為EDA軟體所加載, 但它其實只是”中間人”, 而可在其間把要EDA軟體要傳給真實模型間的訊息加以截取、記錄或改變、或甚至是更改運作的流程。對於一接獲訊息的真實模型而言, 其也並不知道呼叫它的實際上並不是EDA軟體本身而是Proxy物件, 所以便有可能做出實際EDA軟體並不支援或尚未支援的工作。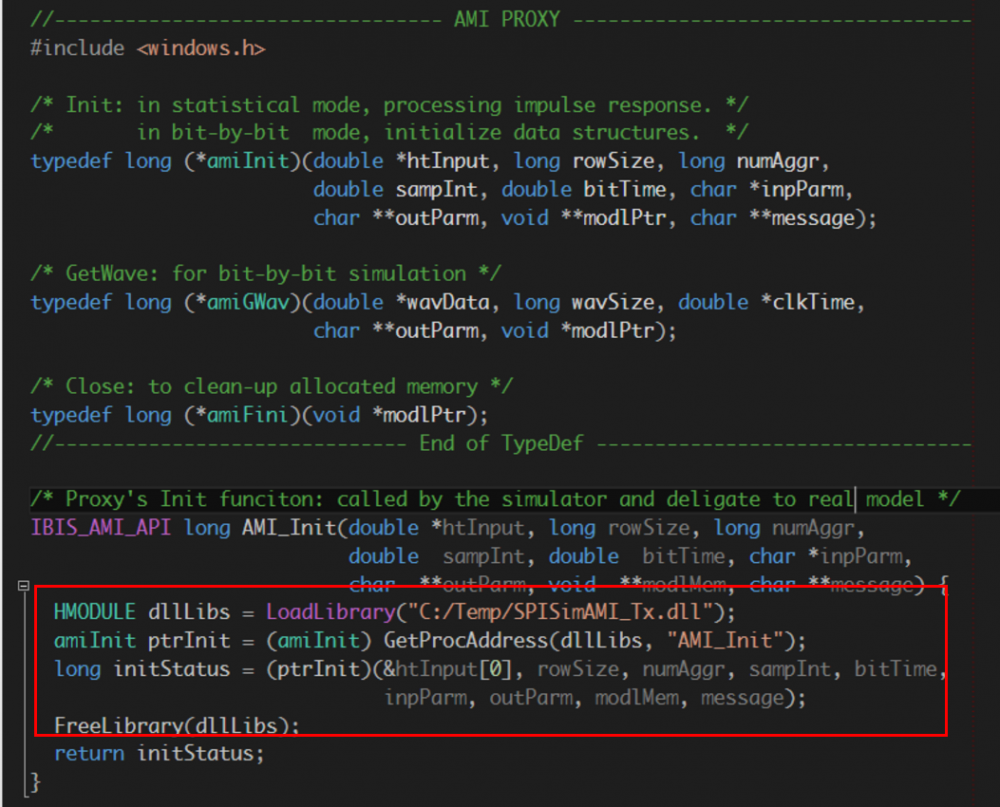 在上圖的源碼截圖中,可見到Proxy的AMI_Init函式做的是把真實模型的.dll/.so加載進來, 並轉而呼叫其內含的AMI_Init函式。
在上圖的源碼截圖中,可見到Proxy的AMI_Init函式做的是把真實模型的.dll/.so加載進來, 並轉而呼叫其內含的AMI_Init函式。
透過這種Proxy的類別或物件, 我們可以做一些有用的測試或實驗:
Consistency/Stress測試:
以下的例子所示範的是同一API函式及相同的資料被呼叫了許多次, 其目的是要做兩種測試:
- Consistency test: 若給與相同的輸入資料, 其傳回的結果也應一致, 尤其如果這個模型是LTI的話(未與歷史記錄有關)
- Stress test: 模型所用的資源如CPU或記憶體等不應隨著被呼叫次數而一直增加,除非有memory leak等的臭蟲
之所以要做這些測試, 是因為在IBIS Spec裡有特別提到, 當EDA軟體或仿真器欲對一長串的位元資料(比如說數百萬位元)做計算時, 其可以把這長串的資料分隔成不同的區塊再依次對同一AMI_GetWave函式做呼叫計算。也就是說, 一個良好的AMI模型應要能通過這兩種初步測試。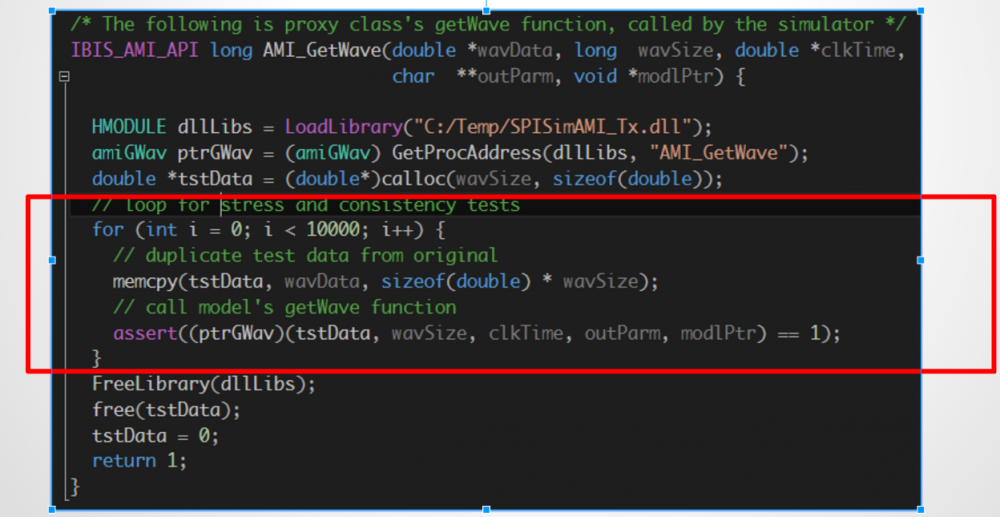
Co-Optimization(程序內):
第二個的實驗是把Tx及Rx的模型綁在一起以便一起做如優化的工作 (巡迴直至某種組合的參數能讓整體的功效最佳化)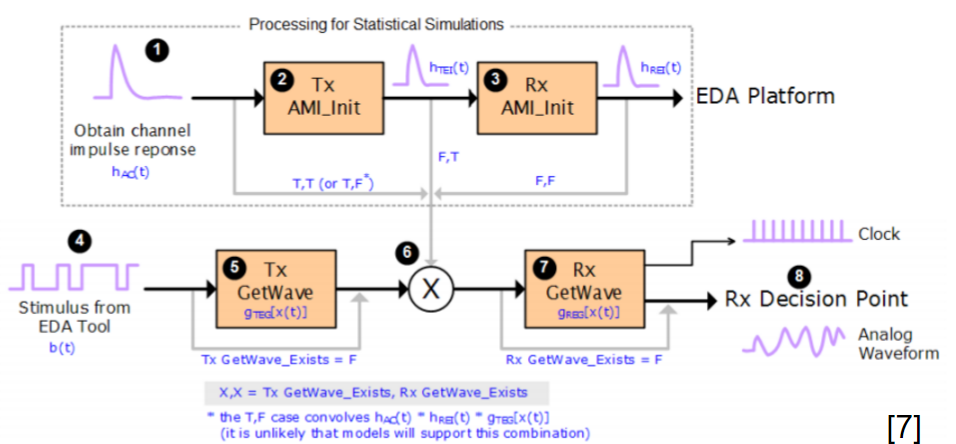
首先, 從IBIS Spec或是上圖中可見, EDA軟體會以輸入1或4做來先對Tx傳值並在模型裡做響應計算, 之後再把結果和Channel做Convolution而最終傳值給Rx模型的GetWave做計算。這些計算主要是Convolution, 而Tx端大都是LTI的如FFE功能模組。
因為Convolution是具可交換性的,也就是說先後次序並不重要: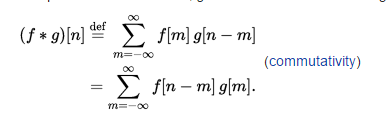
所以如果我們在Tx端以一Proxy物件直接做Delta響應的計算, 也就是直接回傳EDA軟體所送進的資料而不做改變, 就可以在Rx端的Proxy物件裡把這Tx與Rx綁在一起做計算也不會改變最終結果。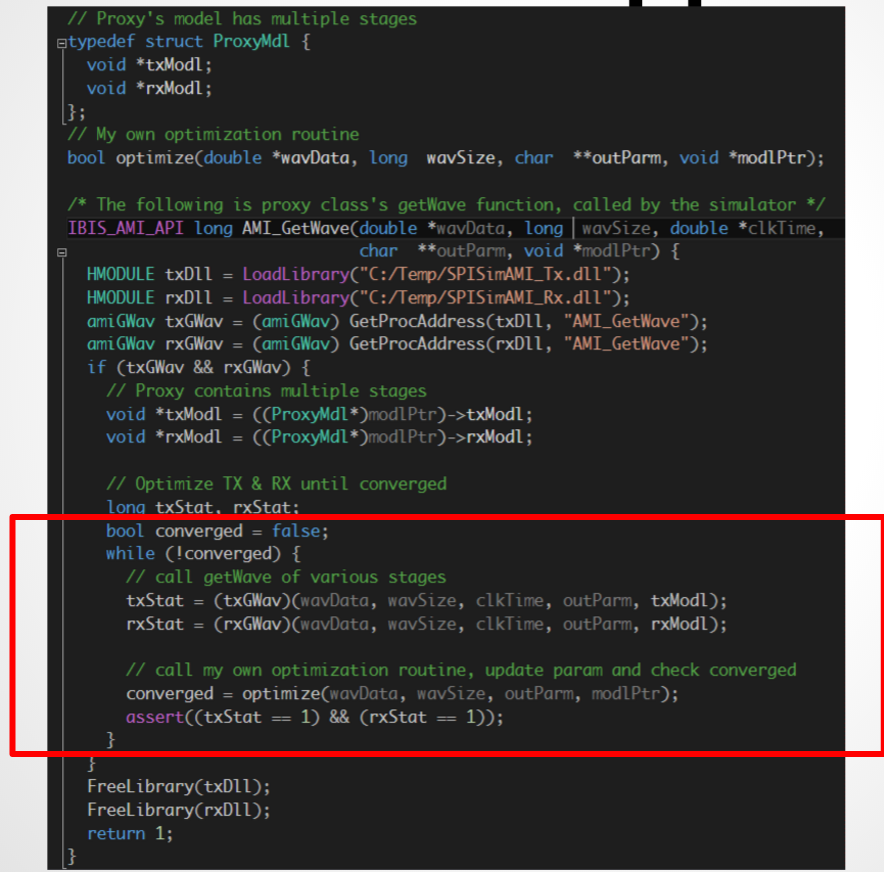
如上所示, 在Rx端的Proxy物件裡我們改變了原來運作的流程, 也就是透過可直接操弄兩者模型的記憶體位址來對內含參數做改變, 再加上一個外包的迴圈且於迴圈內不斷地做優化直致收歛為止。對於上層仿真器或EDA軟體來說, 它並不知道它呼叫了一個模型的GetWave函式後在這裡面竟進行了這麼多的工作, 也就是說:透過了Proxy物件, 我們可以把EDA軟體及AMI模型間的藕合給打斷而隔開來了。這也證明了Proxy類別可拿來為運作流程做客製化的改變。
Co-Optimization(程序外):
以上的兩個例子裡, proxy裡的運作仍是在同一個執行緒及process裡進行的,其實若是在其它的process裡進行, 不管是在本機或網路上的其它機器,這種Proxy也一樣可以讓原仿真流程繼續進行無誤, 以下圖為例: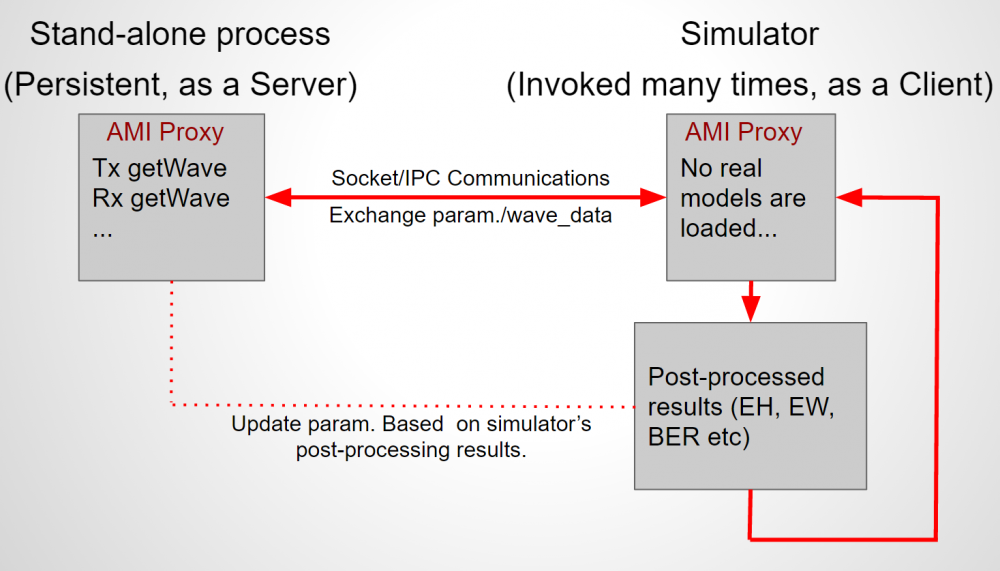
我們想要利用EDA軟體的後處理能力來得到某組設定參數的效能結果, 可以讓右邊的這個程序反覆地進行,但因為呼叫的是Proxy物件,這proxy可透過某種通訊方式來向遠端的(即左方的)真實模型來送及取值, 則左邊這process便可一直長駐(persistent, 如server般), 每次右方的Proxy送值後, 它就做運算且把結果傳回去,而後等待EDA軟體做完後處理後把結果讀進來並為下一次右邊Proxy再次呼叫做準備, 如此便達到了仿真器和真實模型的所在相隔的效用;之前所提到的兩程式間的通訊可以是透過共享記憶位址(shared memory)、波包傳送(socket communication)或是程序間呼叫(IPC, inter process communication)等來進行, 而所謂的server端, 也並不需要有一個如仿真器的程式來載入proxy物件, 只要有個如SPISimAMI, AMICheck等的模型驅動程式來對.ami檔案做前處理並載入proxy的.dll/.so即可。
上圖源碼截圖中間的部份即是透過socket通訊的方式來與不在同一process的模型做連結, 呼叫這proxy的仿真器並不知道模型的運作不在同一process裡。
其它Proxy類別的應用:
除了以上所提及的幾種實驗外, proxy類別的AMI模型也可做為下列的運用:
- 可做為一wrapper以便對由其它程式語言所實作出的模型做支援, 也就是說, 實際SERDES的運作部份可以是用matlab, p-code, perl,或其它執行檔所寫成而透過這proxy來和上層的EDA軟體做AMI流程的連結;
- 可拿來當做一Server以集中管理所要支援的SERDES AMI模型智財,這server可以比如說是在IC智財商的公司裡, 如此便可保持模型的隨時更新及資安上的安全因為模型並沒有發佈出去, 客戶端所用的只是PROXY而已
- 可以拿來支援舊版的模型, 很多現有的模型也就不需要重新編譯, 只要透過這Proxy把要新增的功能加上去再轉譯成原有模可也可了解的參數即可, 或是將新功能即時地在本地proxy處理後回傳而不透過原有模型, 兩者都可以達到新加功能的效果。
我們在AMI的專案中用了不少這種proxy的軟體設計技巧來做分析且發現其甚為有用;隨著AMI模型運用愈來愈廣, 我們也相信這種proxy類別可在更多的情況下為更多的新加的spec及通訊協定來與現有模型做連結。
相關資料:
請[按此]下載當日於會場有關此簡報的錄音。
請[按此]或到IBIS官網下載有關此簡報的PDF檔。