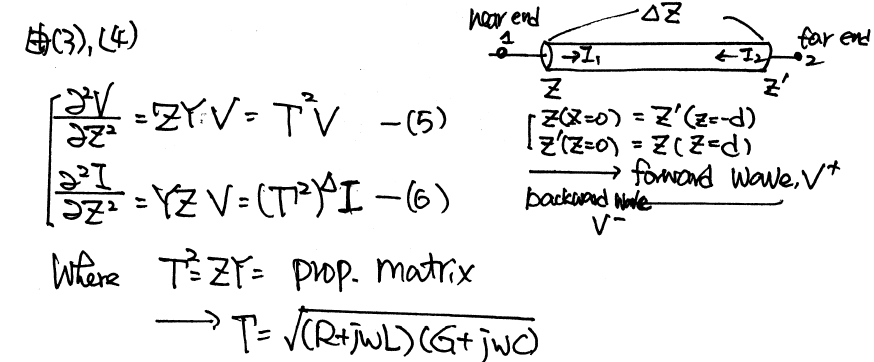
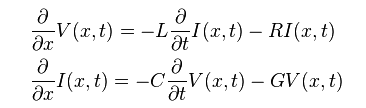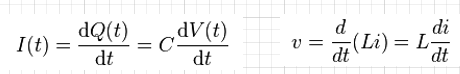系統上的channel及很多個別元件都是以S-參數來表示,其可能是用三維場解器依實體結構(導孔或連結器等)算出、也有可能是利用我們SPro的工具一級一級串結計算(cascade)而成。再加上LTI (Linear, time invariat即線性非時變)的假設,很多工具便可依channel單一脈衝(pulse)的波形來模擬數以百萬計位元的相疊加而得到如眼圖或BER圖形等的資料;無疑地,不論是單一脈衝波行的計算(在含IBIS情況下,未必都能用IFFT的方式來達成)、抑或是針對一些特定位元樣式(bit pattern)時域響應,一仿真器都應有能支援的能力。除此之外,在很多情況下我們所得到的spice電路是由頻域轉換而來、但其原始頻域資料又已不可得;故也常會有要能重現其原來S-參數資料的需要。這篇貼文裡,我們將簡單談談S-參數及相關的port 元件在SPISim使必信 SSolver裡是如何建模的。
S-Element… S-參數:
近十數年的研討會或學術論文裡,多有許多對S-參數時域建模仿真的研究;在最基本的概念上,S-參數是在不同頻域點的輸出入相關資料,其可被視為一頻域的轉換函式(transfer function)或是濾波器;故可套用數位信號處理的基本應用:在頻域上和輸入做相乘等於是在時域上做捲積(convolution):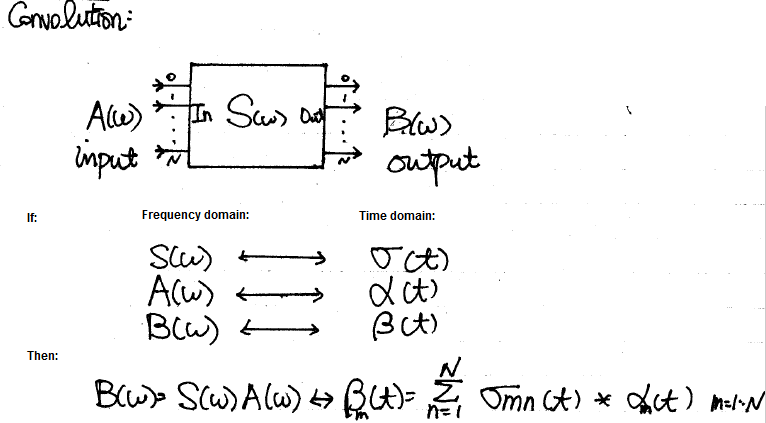
一旦轉成時域(如上圖的最底部方程右邊)則等號右邊則可進一步改寫分成兩項:一個是由元件過去的歷史值算出、亦即由-infinity積分至前一步t=n-1的項目;以及在現今時步t=n和當下輸入有關的項目。前者因是歷史值已發生,故可被視為是一常數而在牛頓迴圈裡不再更動;後者則因和當下輸入有關,故需在Solve及Stamp的熱迴圈裡不斷更新。總的來說,這兩者寫在一起便有了諾頓等效電路I = Y * V + J的形式。其中的Y和輸入V是連在一起的而J則可被視為常數不變。這兩者的值算出後便可自系統矩陣內更新來求解。
有興趣的讀者可參考HP多年前所出版的文件,其中對以這種捲積方式求S-參數解的過程及數學有更詳細的解釋:
Integration of Transient S-Parameter Simulation into HSpice
其中的第「18」及「19」式即為上述有關等效電路的部份。
因為捲積的基本理論是在每一時步之末,常數的值都需更新為-infinity to t=n以便為下一時步t=n+1所用,再者捲積是一種IFFT的樣式而在時域上的時步是固定的,這種要求限制了仿真器運行的速度,也就是為何近來有許多研究論文建議以不同方式來進行S-參數時域仿真。
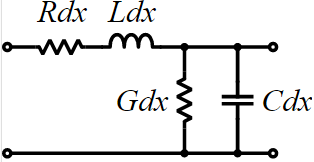
其中的一種可能是利用之前所提、用在傳輸線建模上的的vector fitting技巧:先利用如Pade approximation 般將S-參數頻域資料透過不同極零點的選取而轉成有理式(rational function),而後利用同一種basis function在不同極點頻率對時域的轉換而得到相對應的形式;這過程的一個附加效果是若原有的S-參數資料有non-causal的情況,便可在有理化的過程中得到修正;與為傳輸線建模同樣地:極零點數目的多寡和是否與原始頻域資料相近似、以及轉成時域後的仿真速率都有相關;再加上原始S-參數資料在某些點可能是ill-behaved,故在實務上常得用如pseudo-inverse的方式以minimum-square-error sense的方式來求得近似有理方程式。
P-Element… 埠(port)元件:
系統上許多元件、諸如晶片封裝package, 導孔via,連結器connector等等設計過程都是先有立體設計;而後用三維場解轉出S-參數,最後再用如broadband spice等的工具轉成相對應的spice 基本元件以便能在時域上仿真。對系統完整性分析人員而言,也在很多情況下所得到的元件模型多是這種已透過轉換得到的spice形式而其原始頻域資料並不可得;與其就直接把元件置入channel中來進行分析,較好的做法是先看看其頻域響應為何、頻寬是否足夠及是否有連結性上的問題等等。透過仿真的方式將spice subckt轉出S-參數在此便用應用的空間;而由於S-參數之轉出是植基於小信號頻域分析的,故一旦系統元件的AC模型建構完成,則轉出其S-參數也就近乎水到渠成了。
在此我們談的S-參數轉出是小信號部份,也就是在DC操作點附近的頻域分析,故而步驟上是先在輸入埠元件定義的地方先而對DC求解、加上AC信號後對其它埠測量,而後再進行下一個埠以至所有埠都掃過為止。
一般而言,埠元件(port element)都有幾個參數:DC偏壓、參考負載(reference impedance)、埠序(port order)及埠名(port name)等等;在輸入埠有DC偏壓時,其它的輸出埠都是連到參考負載的;在不同的頻率上求解後,輸入輸出埠間功率的關係可透過對埠的電壓及輸出入電流的量測而算得,而後依S-參數的測量公式:
便可得到輸入埠i對其它埠j的Sij值;重覆這程序掃過所有的i後(不同的輸入埠可能有不同的偏壓)不同頻域點的Sij就都有值了,最後再依之前定義的埠序把資料寫出(至touch-stone format)且在表頭註記埠名則S-參數轉出的程序即算完成了。若是有進一步的需要要將S-參數轉成其它如Y, 或Z參數的形式,則可透過公式(雖是只有雙埠,但若假設S-參數是廣義的2-n port 也可適用)或是如本司SPro的工具達成。
回到仿真器的部分:
除了至今所提的各個元件物理模型的建模外,回到仿真器的階層則又有如下列的相關的課題:
- 記憶區(memory pool)之管理:分配,擴張及清除
- 多執行緒
- 模組化外掛架構以支援新元件
- 其它種種。。
不難想見這清單可很長地列下去,而之中的編程的工作也未必簡單;即便如此,對於系統分析的方法及流程而言,仿真器的完成及支援實有其不可取代的價值:對很多日後的分析,我們都不用(很多情況下也不可能)再得事先導出所有的算式了,我們大可透過直接形成網表後呼叫仿真器後再後處理資料的方式達成。這不僅有助於軟體的模組化,在穩定性(仿真可在另一執行緒或透過simulation farm完成)甚或是可測試性上都很有幫助, 對於一以研發系統EDA的公司如我者而言,是一項值得的投資。