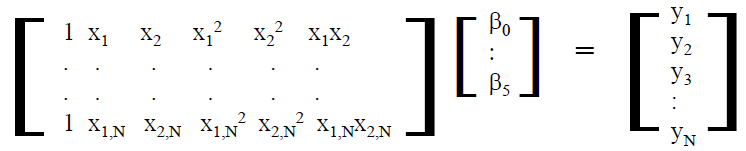對於新上手的建模工程師而言, “IBIS CookBook” [連結按此]提供了極佳的入門參考資料;最近的V4.0版本是在十幾年前的2005年出版的, 時至今日, 雖然其中所描述的大部份程序仍屬有效, 但也有許多其它部份或顯得繁瑣或未盡詳述。這些缺點在第四章”差分建模”的部份尤其特別明顯; 更有甚者, 近年來IBIS峰會上發表的文章大多是圍繞著新IBIS科技諸如IBIS-AMI等打轉, 對於傳統IBIS類比模型的部份著墨就相對少得多。在這篇貼文裡, 我打算首先替讀者重溫一下CookBook裡所談到的正式流程, 而後對其間的一些較具挑戰性的部份加以說明, 並以此倡議一個較為簡化又不失精確的建模方案, 最後提出一些正反意見讓讀者參考。
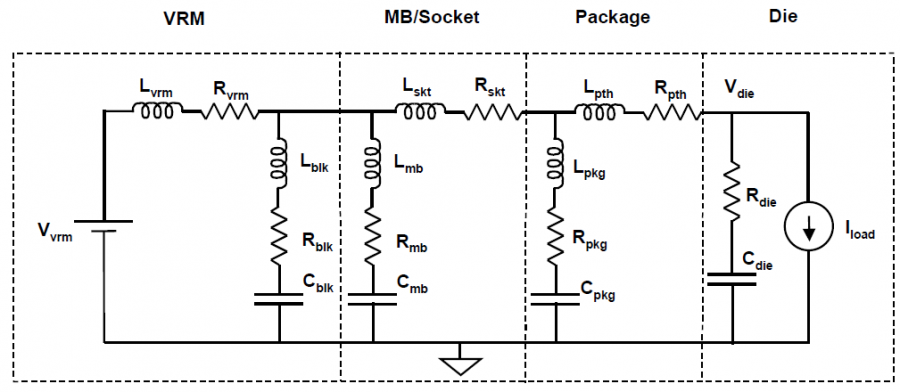
IBIS 模型組成元件:
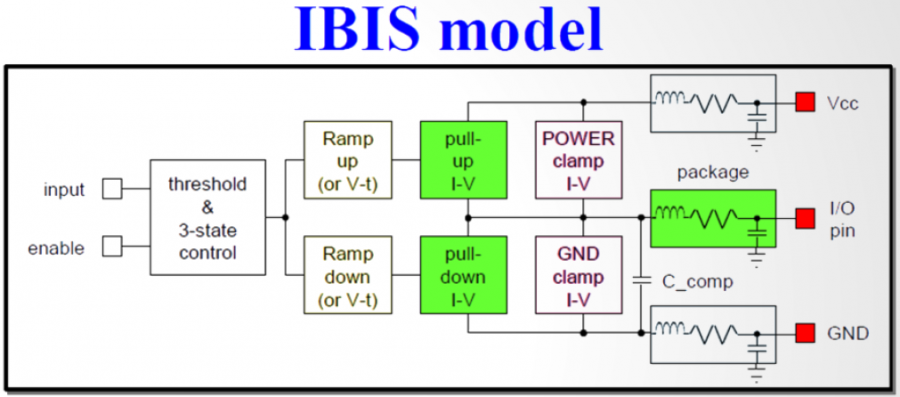
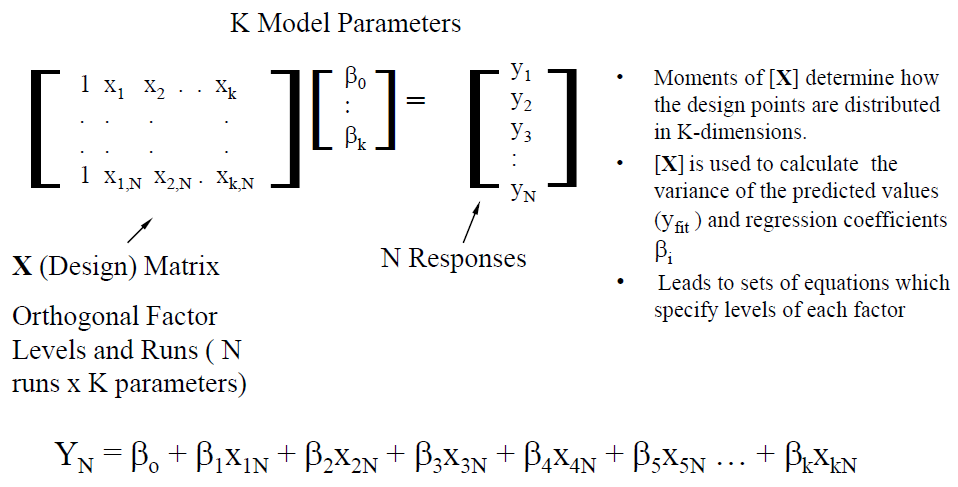
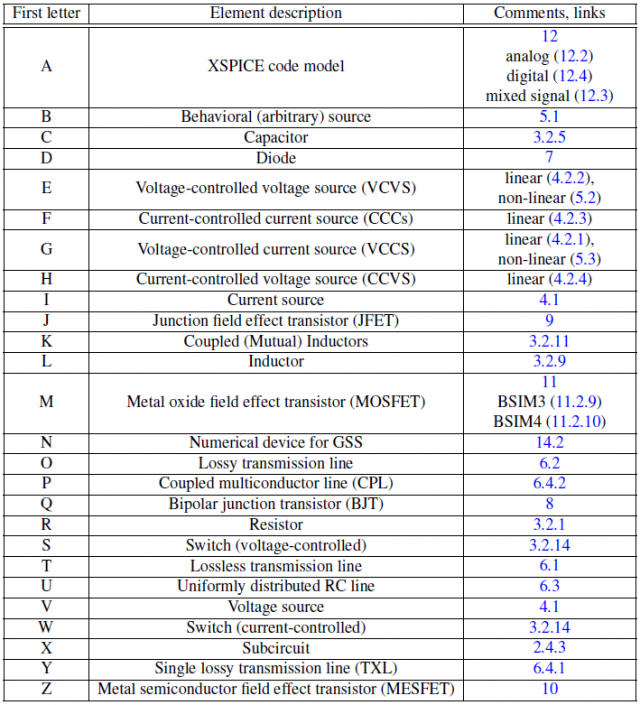
在IBIS V3.2中所定義的最基本組成元件如上所示; 對於一個輸出BUFFER來說一般至少要有六個資料表: 即IV資料如Pull-up 及Pull-down, 及兩組不同負載情況下的VT資料(Rising/Falling各一); 若是輸入態的IBIS模型, Clamp的IV資料或也要, 而IBIS V5.1又加入了新的IT需求並以ISSO PU/PD及Composite Current等來描述電源供應網路PDN的效應。要為一IBIS模型建模, 一開始便需對這些各別表格所表述的電路部份加以驅動以激發得到相對的響應; 有了仿真的資料後便做後處理以產生出如SPEC規定的表格等的格式才能加以使用。由於一個模型通常也有TYP/MIN/MAX三種組態,所以實際上需要仿真的次數便是上述的六(個表格)再乘以三(種組態)而至少達十八個之多。
我們以下列摘要的方式再對包含於上面圖形但未為即將倡議的新建模流程所觸及到的部分加以簡述:
- 封裝的寄生元件: IBIS CookBook裡並未談到這個部份, 一般來說buffer的封裝模型(package model)是由諸如HFSS或Q3D等套裝軟體由實際設計透過三維場解來算出來的, 其格式可為S參數或相對應的Spice等效電路; 一個IBIS模型可以用 Lumped R+L+C來對單一的針腳PIN來描述其寄生效應。或者也可把此lump值放在 “Package” 部份來套用到所有的針腳;需要更精確的描述的話則可用如下有樹狀結構的[Package Model]語法來描述。不論如何, 這些都是三維場解軟體所可以生成的而不在一般IBIS建模流程的討論範圍之內。
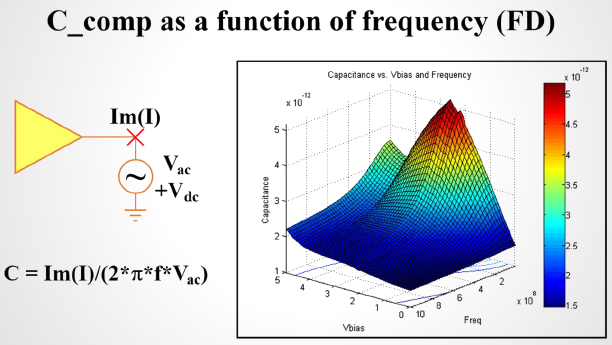
- C_Comp: 在IBIS剛制定之初, C_Comp只用一介於PAD及地點間的單一值來描述頻率性的負載; 後來HSPCIE等發明了一些語法來把這單一值打散並分到PAD與各個不同的電源端點間; 又到最近IBIS Spec.便納入了這些語法而成為標準的一部份;話雖如此, 一般建模人員從網上仍可能只會發現單一的C_Comp值是如何算出來的。簡單地說, 其不外乎是透過時域的仿真以RC的充放電常數來得值、抑或是由頻域的虛部電流除以頻率來得到電容值。至於之後如何把這單一值分開來以便更佳描述如下的頻域二維表面則得仍由各人發揮所長(意即:cookbook裡根本沒說)。最後, 這個C_Comp值的效應在建模的過程裡是看不到的, 唯有在信號從另端因阻抗不匹配的緣故反射回來後才能看到這C_Comp值所造成的影響。凡此種種, 我們發現一般上此buffer的IC設計師比透過上述的時域/頻域仿真所算出的C_Comp值了解得更精確, 也就是說常常問他們就可得到大概的估值。
- Clamp 電流: Power/Ground Clamp的電流和Pull-up/Pull-down的電流都是在穩態下得到的, 在仿真時這四者也是一同拿來做load-line的計算的;所不同處, 因為clamp所表示的是ESD的保護電路故其為總是存在 (always on), 當這兩組表格存在時, 為避免其又被在PU/PD表格裡又再被算一次 (double counting), 在做後處理時需把這部份自後者中移除。若要簡化這個麻煩, 其實一個有IO功能的buffer 在被拿來做輸出buffer使用時便可直接以output type buffer來建模而非io type buffer而可略過此一部份。
- IT 電流(Power aware): 這些是為了描述buffer 在非理想供電或接地情況下的運作而需加入的資料, 其應用則主要用在如DDR DQ的單端點模型裡, 因為它們對PDN的擾動所造成的時間影響最為敏感。對於諸如SERDES的差分模型而言, 因為在P及N點的輸出端會被PDN同樣的影響, 在相減之下效應就抵消了, 所以影響很小而未必有此需要。最後, IT在瞬態的部份其實是和VT一同仿真的, 其只是在PAD端加上一個電流的Probe便可取得相對應的資料, 而且這IT和VT的各點間是需同步的, 所以只要在同一仿真裡就可完成。
完整IBIS建模流程:
本司的BPro軟體已將於上述IBIS cookbook裡所建議的建模程序標準化而總結如下, 其有從0~7的八個步驟:
- 0, 搜集原始設計相關的資訊: 這包括了(PVT即製程、電壓、溫度)、矽智財、Buffer端點的偏壓及設定等等。一般的buffer設計都會預留許多腳位以便為日後調控所需, 因為一個IBIS的corner有TYP, MIN, MAX三種, 故建模者也得先決定那些組合的腳位設定對映到那種corner;
- 1, 準備工作的環境: 即工作目錄;
- 2, 產生仿真的網表: 即驅動不同buffer的組成部件及其仿真時的設定; 如前所述, 以一般的buffer來說, 最少就有十八個網表得在步驟末生成;
- 3, 進行仿真: 一般可在建模流程軟體內依序地仿真或將所有的網表散到不同的機器上(simulation farm)同時並行;結果出來之後得檢查一下看是否有誤, 若然則得回到一開始的地方檢查看是連接有誤或偏壓不對, 不做修正就繼續往下走就會變成”垃圾進、垃圾出”..產生的模型一定有誤。
- 4, 產生IBIS模型: 後處理由前一步所產生的仿真資料以產生IBIS模型。這裡面的計算或調整往往就是諸如本司建模軟體的精華所在, 很多步驟是可以用手動或人工去進行、但往往容易出錯又曠日廢時。
- 5, 語法檢查: 一有了模型之後, 最基本的驗證是用golden checker進行語法檢查, 它也會對dc電位等做基本的測試; 若一模型有根本上的錯誤(比如說vt波型是平的), 在這一步就可以檢查出來;
- 6, 用模型做仿真上的驗證: 把產出的IBIS模型連到 test load上進行仿真以便第三步由矽智財仿真出的結果相較, 理想的情況下, 除了信號從進去到能見於pad的Tco有別之外, 在波型上應是要能完全重合的;
- 7, 產生報告: 建模者最後往往需將諸如PU/PD阻抗及slew rate等的模型參數列出來, 以便和data sheet相較或者做為模型報告的一部份。

本司BPro裡的完整建模流程
單端建模資料之轉出:
對於單端點的IBIS建模而言, 上述建模流程的第一個具挑戰性的地方是要能把十八個不同仿真的網表都建出來且順利仿真完成且結果無誤: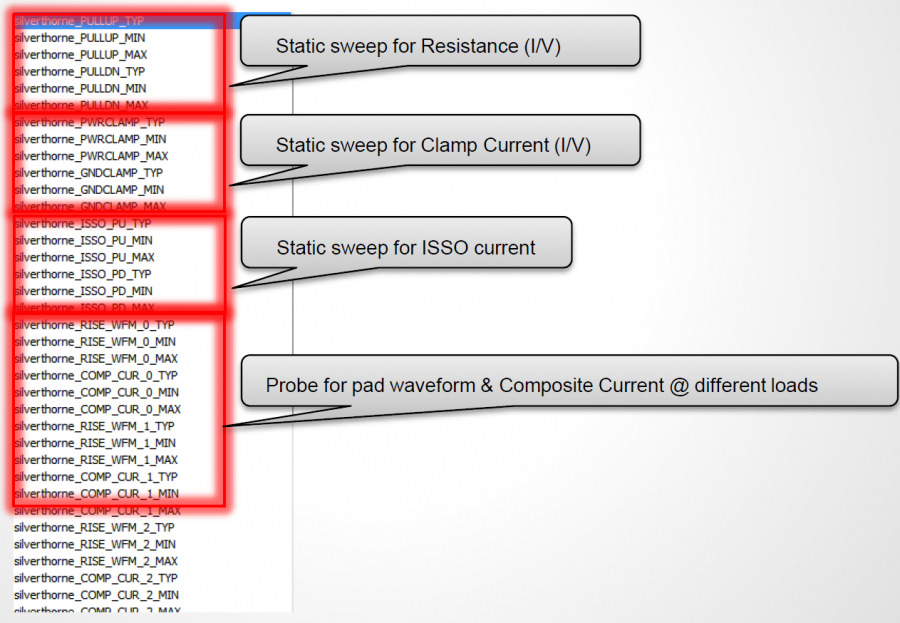
這裡面可能出現的問題很多在於DC IV的仿真部份: 很多的IC BUFFER設計裡都有clocking的信號, 這使得真正的dc掃描從-Vcc到2Vcc變得不可能而必需透過如pseudo transient的方式來進行, 其次, 若設計是於佈線後(post layout)的階段轉出來的則各個電路點之間會有一些寄生元件, 另一種情況是雖然我們只針對IO的buffer部份建模, 但電路是他人所設計而不是很容易把前級的部份和只有IO的部份分開來而最後必需一起仿真, 凡此種種, 都會使得仿真的時間變得冗長甚或是有時無法收歛。其結果是上述0~7的流程得從中間往返走上好幾回、每次調參數或除錯而終得費上好一番功夫才能得到所有建模需要的資料。以上雖繁瑣,但由於也就不過是那十八個網表, 所以大致上應該問題都能解決。
差分建模資料之轉出:
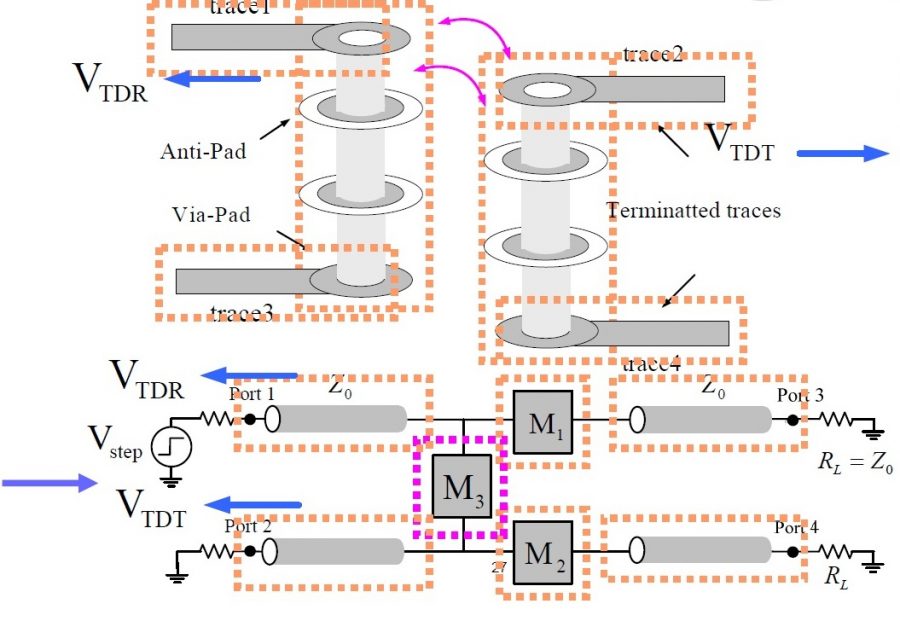
差分建模的複雜性就又比單端點的情況多上一個維度了(不只是多了一倍哦, 是多了一個dimension!) 首先, 依據IBIS規格…就像每一個IC的data sheet裡所呈現的一樣… 一個針腳只能連到一個buffer, 而不同針腳之間的連接是有很高的限制; 就差分模型而言, 一個series element能如下所示地用來描述p及n反相針腳間的相互情況。(本段落所用的圖型都出自於ibis cookbook第四章裡, 所以有興趣更深入了解的讀者可以按圖索驥以得到原始的描述)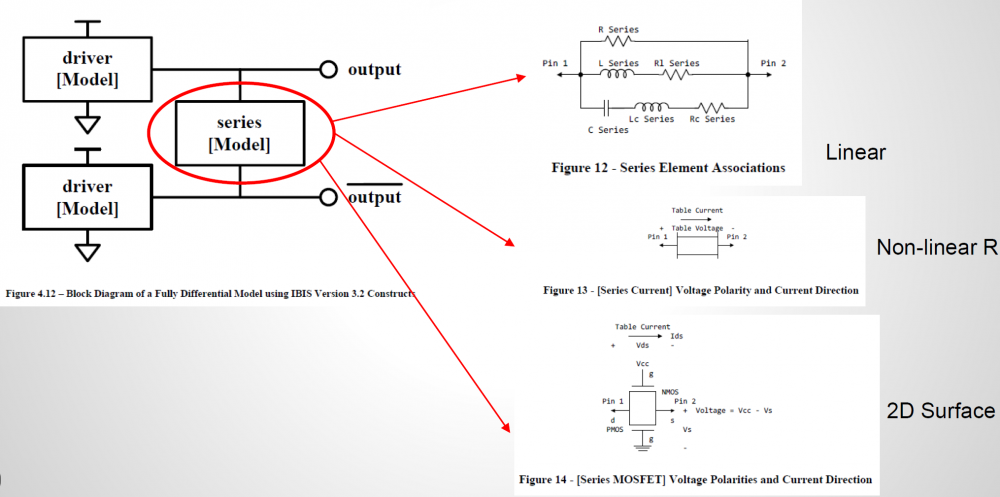
為了能建構出這麼一個series model, 就必需分就p及n輸出端點間做二維的dc掃描; 而且兩者的資料精度必需相近..也就是說如果就單端建模的p點iv曲線我們有一百點的資料, 則同樣在n點的維度上, 為了也要能得到一百個取樣點, 我們就得對一百個網表進行仿真;就三個corner來說, 就有三百個仿真要跑。這一dc iv掃描步驟的最終結果是一個能描述p及n點間dc相互關係如下所示的二維曲面; 唯有看到這二維曲面的形狀為何, 我們才能決定那個series element內有那些次組成元件(其可以是一或更多的R, RL, RLC, 非線性電阻或是一整個非線性平面), 而其中要能產生這二維平面所需先進行的處理步驟之一也包括了要能將同模的電流自P及N點間消去, 凡此種種皆算是第一道的難關。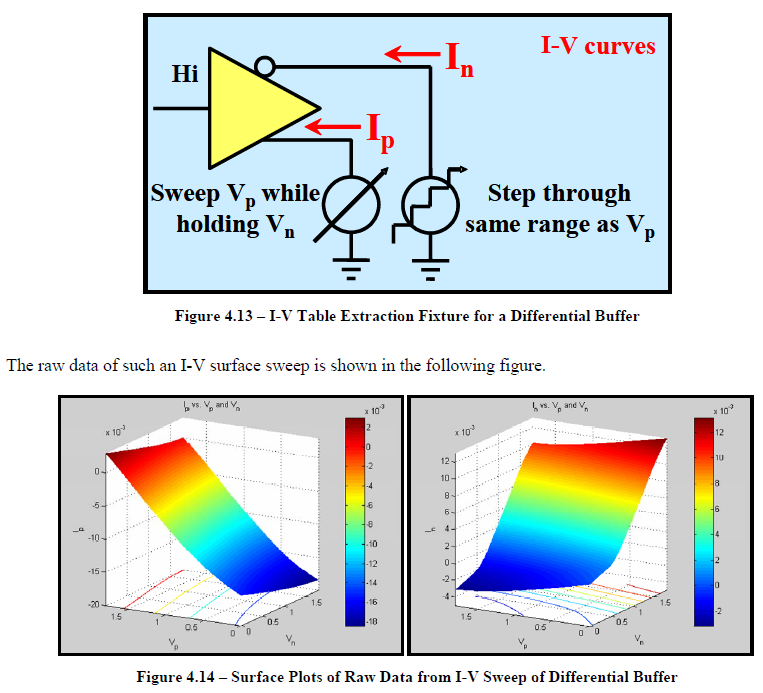
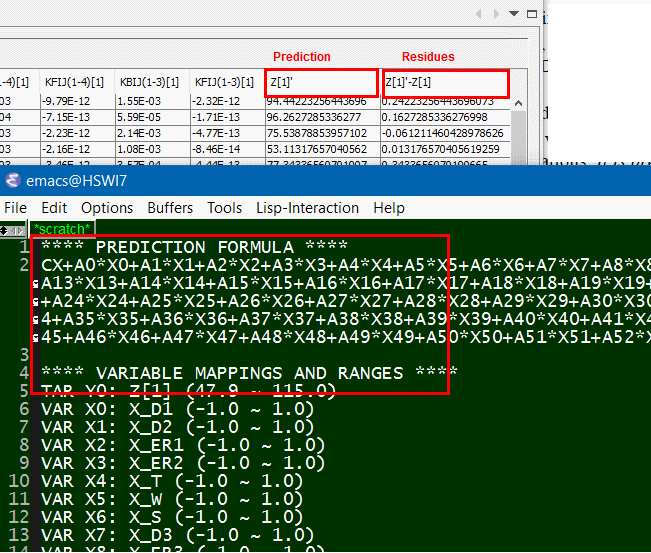
第二道的關卡在於VT的仿真部份, 由上述的曲面建構出series model 之後, 我們要能在VT瞬態仿真時將其消除才能不被算了兩次 (double count); 對於一個spice 仿真器而言, 大部份的情況其都不允許負電阻、負電容等的存在, 也就是說, 它們會把這些負值元件看做是用戶的輸入錯誤而不讓仿真繼續進行, 解決之道, 吾人可以用如本司在2016年Asian IBIS Summit所展演的Verilog-A 電路或是仿真器大都會提供的控制電源來達成這種”負電阻”似的消去目的;即便是如此, 在Verilog-A的解決方案上, look-up table上每個grid的大小係由iv二維描描所決定, 而控制電源的解決方案上, 為了要能算出適當的控制電源參數, 建模者還得利用最佳化的原理才能算出何種組合的參數最能描述上一步算出的反應曲面; 而這些不論是表格或是參數變化間的圓滑性(smoothness), 也都更進一步地決定了仿真的收斂性。凡此種種情況,難怪cook-book裡描述此段的部份(見下圖描述的前兩行)作者只是輕輕一語帶過而不做詳述, 因為真的是說得比做得還簡單啊。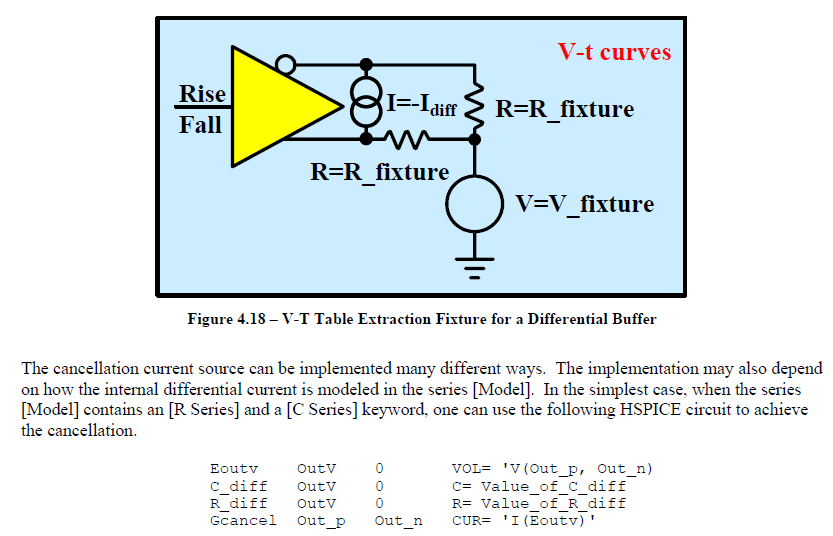
由於這兩大關卡及之間種種藏在細節裡的魔鬼, 我們發現差分的建模對一般的建模者而言不是那麼地簡單。讓我們更有此感悟的情況是: 當本司在提供建模服務時, 很多情況建模的仿真或因IP的考量、或因對原始設計的熟悉情況所限, 往往是由客戶所進行的, 我們雖已盡己所能地把這些該如何設定及其原理為何做最詳盡的描述,但在客戶端仍常常碰到問題或反應意見說要很久的時間才能得到所有需要的資料, 其次, 客戶之所以把建模工作交給本司就是不願去淌這混水…如果很多麻煩的地方仍得自己來過,那建模外包又有何益? 所以就本司而言, 對於去找出更快速有效的建模方式, 其實是都持續不斷地在進行的。如果我們建模的目的是為了能跑Channel Simulation (而非萬能地又做穩能又做時域依真), 也就是說如果了解模型的運用是在某種特於的環境之下, 那是否有更好(尤其是差分)的建模方案呢?
簡單快速的新建模流程:
在之前的貼文中, 我們提到了IBIS模型內部的資料在仿真時是如何被運用的; 簡單地說, VT的資料在得到波型一樣的負載情況下, 是做為一個目標(target)的; 在此”目標”之下, IV的部份則會被拿來算出一組時變的切換參數以便使適量的電流能自PAD點輸入或流出, 基於KCL/KVL的考量, 這適量的電流就會造成仿真矩陣運算時節點的適當電壓而終能符於VT的曲線; 其次, 由於分有Pull-up及Pull-down的切換參數要解, 所以就得有在不同負載情況下的VT曲線才能由兩組資料解出兩組未知;這也就是說, 其時IV的資料和算出的切換參數是互為表裡的, 做為表面、看得到的IV部份需由看不到的參數來配合, 如果IV某電壓點的值小些,則用到那電壓點的某個時步上的切換參數值就得大些才能使最終電流維持不變。從這點來看, 待算出的切換參數可以視做是IV曲線的加權或調整參數。
在另一方面, 每一組的VT曲線裡也內含了對IV曲線一些部份的限制, 在這些限制之下, 兩者之間(即VT及IV)必需要相符否則就會有dc mismatch的錯誤情況發生。最後, IV本身的資料限制是只能有最多一百個點且其間必需單調性的遞增或遞減否則就易在仿真時產生不收歛的情況(stuck-at local minimum)。這些都隱喻了模型裡各個資料間的相互關連性。
由上所述, 我們可以推出一個簡單快速的建模法所需的資料產生步驟為:
- 將原始silicon設計連到相對應的PVT及偏壓情況下後得到VT仿真資料, 而這VT是如此設定的:
- 就單端點模型而言, 僅用兩組不同的負載情況(test load)
- 就差分模型而言, 先做一般使用狀況下(比如說是一百Ohms的輸出差分電阻)的仿真, 得到電壓介在V1及V2之間
- 設V3=(V1+V2)/2, 以V3為VFixture, RFixture=比如說是40及60, 分做兩次仿真並以此為資料VT波型;
- 或者用RFixture=50, VFixture分為(V3+V1)/2及(V3+V2)/2並進行仿真, 以此為資料波型;
- 這一步驟的主要目的是要取得能內含正常運作情況下的兩組波型;
- 由IC設計師那兒得到C_COMP值;
- 得到不同Corner的電壓及溫度等參數。
就這樣,再透過不足外為人道也的數學運算及解析, 我們就能透過最少的仿真步驟而產生IBIS模型, 且這模型不會有語法錯誤又能在相同負載情況下重現上述所提供的兩組VT資料。
我們雖不能詳述這中間倒底是怎麼做的, 但可以分享的是在我們的BPRO上,如此的流程僅需填值到如下的GUI裡就可在幾秒之內產生出來, 過去這大半年來,我們已用此法建出許多為客戶所用的模型, 跑起來亳無問題!
優缺點及限制:
我們運用此法建模的使用場景主要是含有IBIS-AMI的差分模型且用於channel simulation情況下, 以此來看, 如此倡議的快速建模法會有如下的優缺點:
優點:
- 只要透過最少的仿真(即兩組VT仿真), 便能得到建模所需的資料;
- 就數學及電路分析上會絕對正確, 故而不會有如DC mismatch或monotonic等的語法問題, 在驗證時相同負載的VT結果一定能重現原始資料的波型。
缺點:
- 如果把這IBIS模型拿來做DC仿真/掃描的話結果未必會精確, 因為模型內的IV資料點是用演算法算出來而不是真的一步一腳印透過DC掃出來的;
- 沒有”disable”或”high-z” 的state, 因為所有的clamp電流都已內含在算出的pu/pd IV曲線中;
- 不能拿來做Power-Aware的仿真之用, 因為其中並無ISSO_PU/PD, Composite Current等的資料。
結語:
在這篇貼文裡, 我們首先重溫了在官版cookbook裡傳統IBIS的建模方式及流程, 而後談及了這流程中可能會遇到的困難…尤其是差分建模的部份; 以次我們提出了一個”簡單又快速”的建模方式….其運用了數學的演算來人工合成出模型的部份資料, 這倡議的方式僅用最少的仿真便可建出有效無誤的模型。它有些使用場景上的限制…比如說沒有High-Z State且不能拿來做power-aware的DDR仿真等。我們研發此法的主要運用是含有IBIS-AMI的channel analysis, 以過去大半年的使用來看可驗證其有效及方便性, 因此我們在近日的SPIBPro更新裡也加入了此一功能以使我們的軟體用戶也能同享此快速建模法所帶來的好處。