

前言:
這篇博客文章是為了即將於 EPEPS (San Jose, Oct/18/2017), 上海 (Nov/13/2017) 及台北 (Nov/15/2017)所舉行的IBIS Summit所準備,我將於這些會場上發表相同主題的文章。相關資料如簡報檔、案例模型以及會場錄音可下載於下:
- [MP3 Audio]英文, 43分鐘,錄音於EPEPS IBIS Summit San Jose會場
- [MP3 Audio]中文, 45分鐘,錄音於Asian IBIS Summit Taipei會場
- [PDF 簡報檔] [模型範例] 這兩者亦可於IBIS官網下載
動機:
許多年前當我剛開始做SI分析時,採用的標準程序是以spice的仿真器在時域上跑上幾百奈秒,之後再做後處理來得到一些分析的數據。那時一般channel的時脈剛過1Gbps。最近幾年由於高速SERDES的發展使得數Gbps的介面無不在,更不用談動轍50~>100Gb的新802.3網通規格。這麼高時脈的傳訊,若要有所本地談到bit-error-rate (BER)能在多少信心(CI, confidence level)之下有多好的表現(比如說有信心99%以上在1E-12BER以下), 則非得跑上數個1E12bit 不可。要跑這麼多bit,若仍想用以往那種Spice, Nodal-based的方式來跑是不太可能的…要花上太多的時間。所以一定要有新的方法來進行SI分析。在約十多年前2003左右, 如StatEye的分析法便被提了出來, 時至今日,這種用統計方法上對高速電路做的SI分析可以說是快形成了主流, 則吾人便不可不對其上大都會用到的Algorithmic Modeling Interface (即AMI, 是IBIS規格下的一環)模型來做個了解。
AMI建模可說是極具挑戰性的, 因為其牽涉到跨領域的知識及概念。舉例來說對C/C++的編程、上述利用統計法上的仿真、以及一些高速電路建構區塊上的應用等等都得有些大概的了解才能開始進行建模的工作。這也就是為什麼其相較於傳統IBIS的建模下要花上數倍時間或精力的原因。一般而言, 兩個對一般工程師來說最麻煩的地方就是一:要以C/C++的語言來編程, 及二:所編程式需與AMI Spec相容且以.dll/.so的格式來呈現。所以在相關討論中我們常會聽到的兩個問題是: 一:我們可否不用C/C++而用我最喜歡的scripting language來建模? 二:我已有Spice model, 可否直接拿來跑link analysis?
本文將對這兩項常見的需求提出一些理論及實作上的探討及示範。
背景知識:
通道分析(Channel Analysis): 現今的通道分析大多牽涉到TX或/及RX端的等化(EQ)。雖然傳統IBIS模型上也有一點和這有關的設定…比如說driver schedule, 但大致上而言早已過時或不合所需;所以這些EQ電路都是在IBIS模型之外的。之所以有需要加入EQ是因為若無其來對ISI (Self-channel interference) 及XTK (Co-channel interference)來做預加重,後加重等的作用,則其眼圖通當是不會開或很小的。也就是說,沒這些EQ電路,以S參數來代表的通道大都過於Noisy而不符通訊標準的要求。
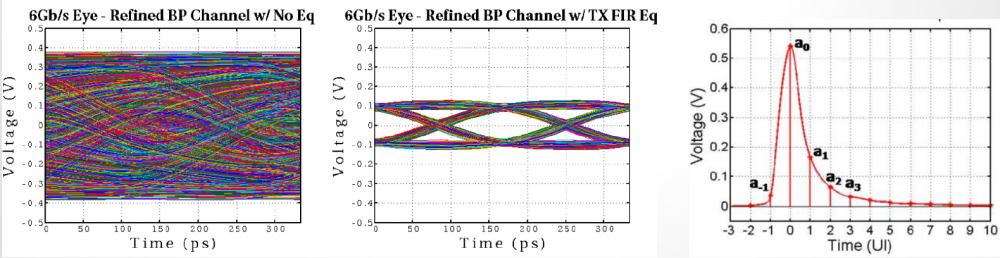
一般而言, 現今有兩種常用的方式來做通道的分析:
- Statistical: 若電路是線性非時變、及Linear Time Invariant (LTI),則僅僅用一個脈波(pulse or impulse response)即可得到相當多的資訊以供分析所需;這種方法通常是把含passive channel在內以及LTI Tx/Rx端的單一脈波在不同UI上做切割之後,利用和非main cursor之外的pre-cursor或post-cursor來做疊加(superposition or superimpose)而後得到機率上以及期望值上的統計, 從而能積分再得到Cumulative density function以對想要的BER值做一估計。
- Bit-by-bit: 若是電路具有時變性或非線性, 即Non-linear Time Invariant (NLTV), 則上述的疊加法則不可行,在這性況下,就得乖乖地用時域上bit-by-bit的方式來”跑”, 但有別於和spice, nodal-like地”跑”, 這新的仿真方式是有假設(High-Z, 稍後會提到)且跑得快得多的。進行上是仿真器會把一連串的數位bit sequence傳給NLTV的電路,由其內部做處理後把輸出傳回給仿真器,而後再由仿真器和是LTI的channel來做convolution. 值得一提的是因為要跑上數百萬個bit, 所以仿真器是可以將其打散成不同的bit chunk, 分別傳給TX/RX跑完後再組起來;組合的時候則要將相臨Chunk之間的aliasing考慮進去。
AMI模型對這兩種新而常用的分析模式都有所支援。
AMI Model: 一個AMI 模型通常包含有下列幾個部份:
- .ibs file: 在含AMI模型的ibis檔案裡,有一個”Algorithmic Model”的關鍵字區塊,其中指向了所用的.dll/.so, 及.ami檔案的路徑所在;其次,是在何作業系統、位元數及用什麼編譯器所編出此AMI檔的亦包含在同行的資訊裡。
- .dll/.so file: 這是二進位位元檔, 係以純C語言以合乎AMI API的要求所編譯出來而能為業界的link analysis程式來讀進驅動的。
- .ami file: 這是一個本文檔, 包含要給上面.dll/.so檔所需的組態資訊;如下圖所示, 此檔包含有兩個主要部份:
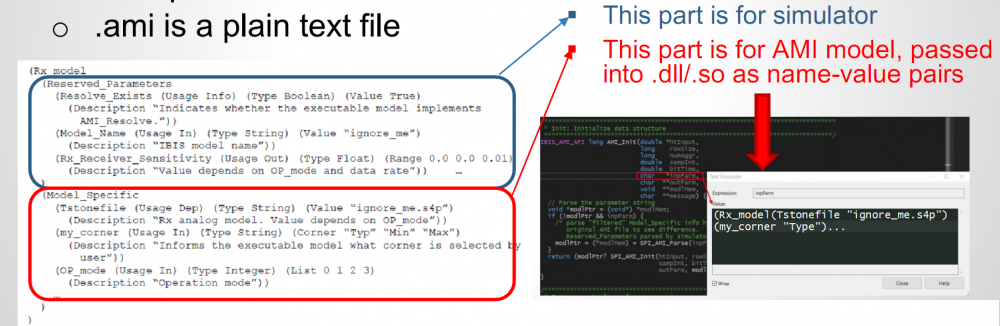
- Reserved Parameters: 即上面藍色方塊內的部份,資訊是給仿真器讀的…被呼叫的AMI模型看不到的。這裡面包含了必需要有的關鍵字如Resolve_exist 或GetWave_Exists等等,根據這些關鍵字所給值的真偽,仿真器再來對所對應的API程式(位於.dll/.so檔內)在呼叫。
- Model Specific: 此即上圖左以紅框包住的部份,這些設定是建模者自己定義而仿真器及/AMI SPEC上管不著的。又雖然字面上在AMI檔裡有一大串,但仿真器會加以讀取,並過濾成相對簡化得多的name-value對(上圖右的部份)後再傳給AMI模型的,也就是說, AMI模型所接到的組態就格式而言其實是已經簡化許多了的。其次、雖然在AMI檔裡的樹狀結構設定(以”(“做分枝開端)可以有很多層,但在其最簡單的格式中,AMI模型收到的資料可以是以根為模型名稱(以上例而言是Rx_Model),而其餘所有的name-value對都是樹狀結構裡”葉”子的末端部份。
AMI-API Functions: 以IBIS V6.1的規格來說, 有最多五個API函式可在AMI模型內被定義執行,如下圖所示:

其中AMI_Resolve及AMI_Resolve_Close都是有關組態參數的預/後處理,在一般情況下不太會用得到;而AMI_Close 則像是程式結束前的垃圾處理…也就是把所分配出的記憶體”還”給系統。在現今的作業系統上, 即便是我們在此函式內完全不做任何動作,所佔記憶體最後也會被強制歸還(所以現在的windows很少有BSOD了), 所以這個函式也只是次要的了, 真正重量級而需仔細考量的兩者, 即AMI_Init 及AMI_GetWave,已用紅塊表示:其主要的功是參與上述所提”Statistical”或”Bit-by-bit”分析方式的實際運作。也就是說:若是被建模區塊為LTI, 則其必要執行AMI_Init的執行,AMI_GetWave則可有可無。而若是電路為NLTV, 則其必要有AMI_GetWave的執行, AMI_Init的部份則只做初始化的動作。
其次,再對這兩者的的argument而言,如上圖右中紅框的部份,其第一個陣列是同時做輸入及輸出的, 因為是傳址陣列,所以是passed-by-reference, 也就是程式內任何值的改變終將能被上層的仿真器所取回。所以在AMI模型被呼叫之初,這些陣列內所含有的是之前所述的impulse response 及digital bit sequence, 每一個sampling point之間的時步是sampling_interval,而後AMI 模型依據傳入的其它設定來做計算, 算完之後再把算出來的值放回同樣的陣列裡,而最終為仿真器所取用。
AMI 建模流程:
綜上而言, 一般AMI的建模流程有列數步驟:
- 先取得欲建電路的行為方式,其來源則可是從算術式中導出、仿真或LAB信號量測所得。後兩者可能最終以look-up table的方式來呈現並建模而非close loop equations.因為我們即將要將此電路的行為模型以計算機語言來表示,所以一定得先知道其作用為何。
- 將上述的電路行為進行編程為AMI-API, 這裡又包含兩個部份: 其一是一定要用plain C語言以合乎AMI-API格式來編程的部份;另一個部份則是實際電路依想要的行為模式來運作的部份…後者可用任何語言或方式來產生, 未必要用C, 也就是說, 實際的電路運作程式其實是可以用非C的語法來編寫的, 只要用C編好的API那部份知道怎麼和這部份的程式溝通即可。
- 將第二中C的部份以.dll/.so的方式編譯並測試除錯。以WINDOWS上而言,通常只要改一下編譯器的設定以編出32及64位元即可。但在LINUX上而言, 因有眾多版本的不同(debian, red-hat…)甚或是GNU C對C99, C11等不同格式的支援,就要在很多不同的系統上都測試才能得到一致的結果。
以Script來為AMI建模:
有了上述的背景知識之後,我們來看看如何以Script來為AMI建模:
流程:
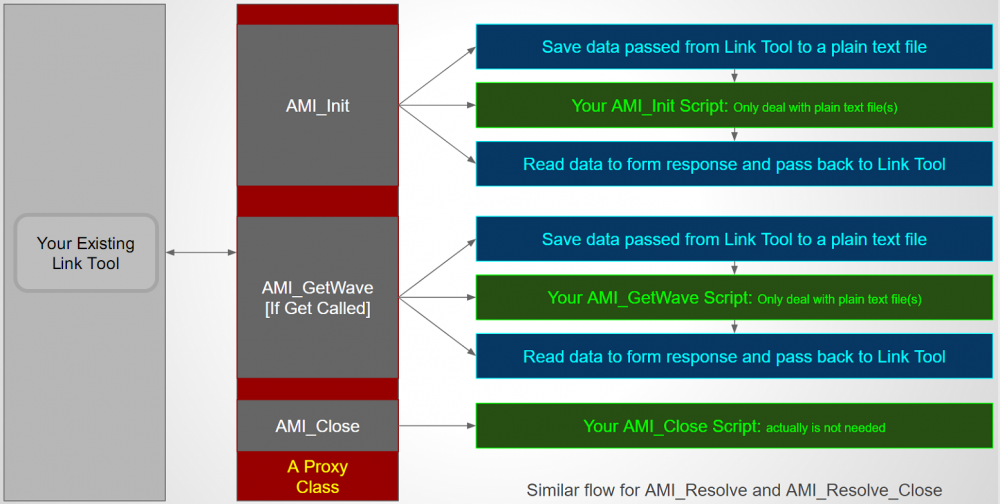
上圖為示範流程, 大略上來說, 我們先要有一個很”薄”的AMI模型..其為以C寫成,這一薄層模型不做很多其它的事..諸如任何運算; 它的主要功能只是把從仿真器裡接到的資訊以本文的格式寫成一個檔案,而後把這新寫出檔案的路徑傳給用戶的Script, 呼叫的方式則是透過System Call. 而其它相關要傳給Script的變數也可先透過.AMI檔來設定;用戶的Script被呼叫之後進行必要的運算…看其是得支援LTI的對impulse response的convolution或是對NLTV所傳進的bit-sequence做運算等。結果算好之後又把其寫到另一個本文檔;這新(或相同)的檔案路徑是”薄層AMI”所事先知道的;所以在系統呼叫這Script完之後薄層AMI就會把這檔案內容讀入,再把其內的值填入由傳址呼叫的變數記憶體位址內完成回傳給上層仿真器的程序。其次, 若是在AMI_Init, AMI_GetWave兩函式之間Script有要相互溝通的需要, 在以純C/C++編寫的情況下是有一萬用位址(void *)可在記憶體內直接互傳,但在此以Script進行的流程則需以File based的方式為之。綜上所述、簡而言之, 最上層仿真器和薄層的AMI模型中溝通方法和與其它AMI模型間無異,但薄層AMI和其下的Script中溝通法就都是File based, 透過系統呼叫及這種File based的傳資料,用戶是用什麼Script來編寫對薄層AMI來說就無關緊要而都能達成目的。
範例:

上圖所示為一以MATLAB所寫的範例, 其中左邊為薄層AMI的運作,其間的第二步正是呼叫用戶的Script, 而Script裡的第一步是叫parseInput的函式來讀值,接下來透過Matlab conv()的程序來和FFE做運算, 最後再叫storeOutput的函式把值寫到另一檔案裡, 系統呼叫完之後左邊的AMI模型就走第三步把在檔案裡的值讀進來而最後傳回給上層仿真器。
考量:
雖然以Script建模是可行又方便的,但在打算釋出此法建出模型時則有一些值得考量之處:
- 效能及可發佈性: 因為所有在薄層AMI及用戶Script之間的傳遞都是透過檔案為之, 所以在效能上就不免會打些折扣, 如果要進行運算之處只是在AMI_Init裡的話這就無所謂…因其只會被仿真器呼叫一次; 其次,取決定所用Script的不同, 可發佈性也就有所差異,比如說若這Script是用.m寫的, 則終端模型用戶的電腦裡就也要有matlab才跑得起來,就算是用compiled matlab的用戶也要先裝matlab compiled runtime (MCR)才能跑,若是以perl的話用戶要先裝perl的解譯器…凡此種種都要先考量, 更何況有些語言在license上可能就有散佈上的限制。
- 考慮使用Python!: 以此AMI建模目的而言, Python應是一很值得考慮的語言, 其一是它有很豐富的開源數值運算函式庫 (SciPy, NumPy等),更重要的是有一Embedded python的機制使得薄層AMI在和python的函式庫一起編譯之後,所有所需的Python編譯器就可連同所需的函式庫一起打包成單一zip檔案來和AMI模型一起發佈…相較其它語言來說(C除外), 等於只多一個用戶的script及此zip檔, 可說是相當簡潔的。最終端模型用戶完全不需要另外安裝python的解譯器。
以Spice subckt 來為AMI建模:
現在暨然我們知道了”薄層AMI”模型可能的妙用,則很自然的下一步想到的就是:是不是可以連寫碼都不用,直接透過nodal-based spice仿真器來進行AMI的建模或運作? 這答案當然是肯定的!
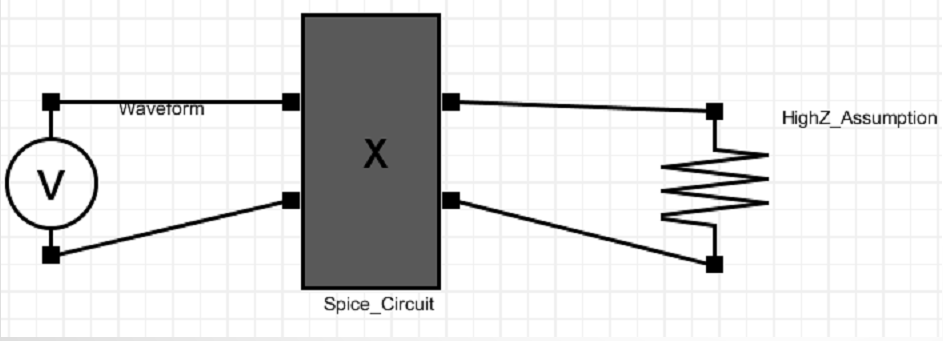
這裡我們要先回頭談到之前所提及的High-Z assumption. 在一般的nodal-based spice仿真器運作上,每一個時步裡其實都牽涉到好幾個牛頓法的求解(Newton-Raphson Method). 每一牛頓迴圈之初,試探性的每節點電壓就會先被設定,而後在不同節點間的元件依這些電壓來做運算,所需採用或輸出的電流再注入這些所連結點裡; 在牛頓迴圈之末,仿真器就做矩陣運算看KCL/KVL是否已達平衡,依此再決定是否需要另一牛頓迴圈或是可進入下一時步。
對於link analysis而言, 要做Bit-by-bit based 時域分析這麼多牛頓迴圈就行不通, 所以其所採的假設之一就是High-Z, 也就是說輸入及輸出阻抗都很高…使得其輸入的電壓不會被此級電路所需流所影響,而且一旦算好輸出電壓, 接下來同一時步內的運算也就不會將其改變。如此一來, 每個時步就只要運算一次!
在此假設之下,我們若欲以spice model來為AMI建模, 要做的就很像是script方式走的程序, 探討如下:
流程:
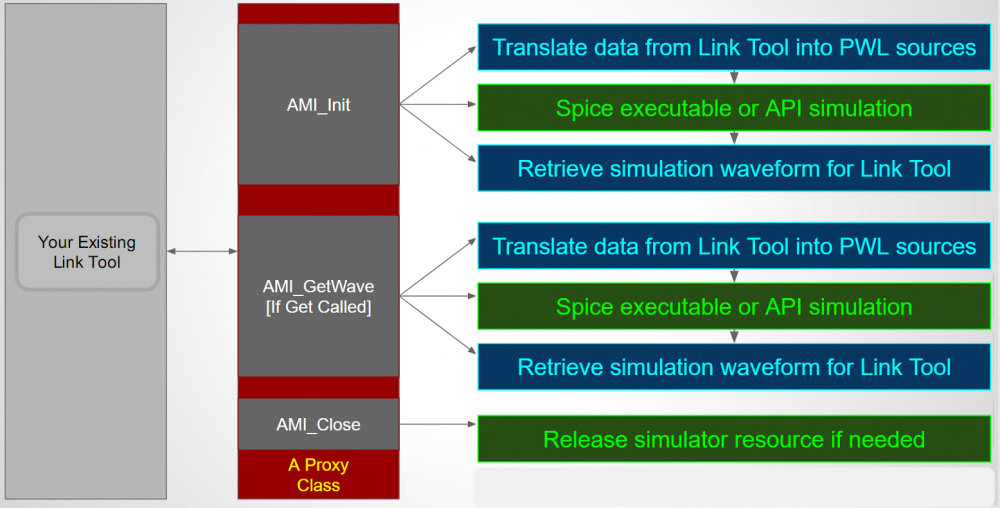
首先, 一以C寫好的”薄層AMI”模型仍是需要的,其作用儘限於將從仿真器所傳來的輸入波形以一PWL源的方式表之並寫成一網表(netlist), 這網表內會呼叫用戶所提供的spice model, 至於spice 的參數也若有要覆寫的話也可先籨從.ami檔裡設定; 寫好網表之後, 薄層AMI就呼叫所支援的spice仿真器來對產生的網表仿真, 這程序可透過外部仿真器的直接呼叫或內建的API來為之。仿真完後的波形…可能是如.tr0檔案,則再被薄層AMI所讀入、處理並填回初始傳址呼叫變數的位址裡以完成回傳的程序。
值得一提的是傳給用戶spice model的電壓只是兩節點間的電位差, 其並不含有任何有關GND參考電壓的資訊,所以用戶spice model裡自己很可能需要定義此一電壓的GND 參考值在那裡, 也就是說, 用戶的spice model裡需有接地端。
範例:
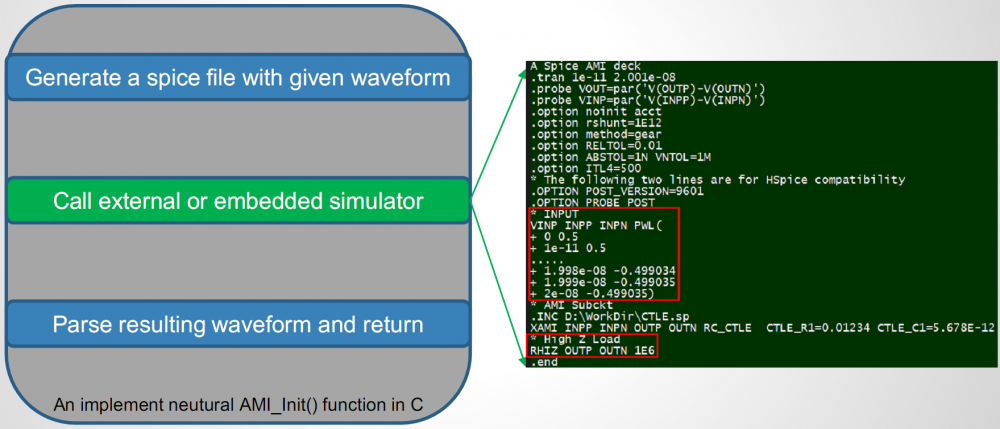
上圖所示為一可能範例,其中左邊第一步:”薄層AMI”有一內建網表檔案, 這網表的PWL資訊及所呼叫兩輸入、兩輸出端點的spice model為何則在網表寫出時機動產生; 輸出端的probe也都已設定好了, 所以中間那一步就是透過仿真器來對剛產生的網表做仿真,而最後後再後處理其結果並把值填入回傳給上層link tool.
考量:
如與Script建模流程一樣,這裡也有效能、可散佈性等的考量。效能方面因為每一次的spice model呼叫都會牽涉到nodal simulator matrix的初始化、DC的求解、以及每一sampling point時步的運算, 所以不會跑得太快, 同樣的…若是執行的API函式只是AMI_Init,則這點顧慮可以忽略..因為只會被呼叫一次;就算其運作上是AMI_GetWave而要比一般的AMI model花上十數或數十倍時間來跑,但只要跑一次就可得到精確的數據而能供未來旳建模參考之用。其次就可散佈性而言,若是spice mode裡有用到某個mosfet的模型而需要特別的製程或仿真器, 如HSpice,則終端用戶就也要有HSpice才能跑;就這點而言建模者可考慮開源的仿真器如NgSpice, QUCS等,因其不僅可以執行檔的方式進行運作,同時也提供了shared library的模式, 也就是說此一”薄層AMI”雖要做的動作不多, 但其實可和仿真器的shared library連結一起編譯而自成一仿真器, 在此設定之下,用戶完全不用安裝任何其它的仿真器。
結語:
從上面的討論, 我們知道不論是透過Script或是Spice Model來為AMI建模都是可行的, 事實上,這理所談的都不是紙上談兵而都是已實作出案例;即便是有效能或可散佈性上的考量, 這兩種建模的流程都以縮短建模的design cycle或提供日後可能要以C/C++語法做實際建模時的參考數據。而其中所提及的、不可或缺的”薄層AMI”模型, 因其運作上的要求很簡單,只要一次性的花時間做一個就可被重覆使用;事實上本司的SPISimProxy就連這步驟都為讀者省了因為我們已將其公佈供各位免費使用, 凡此都可供讀者做為日後AMI建模的參考。