

前言:
在前篇貼文, 我們大致探討了有關IBIS-AMI模型的幾種相關角色及其所需要的考量;在這篇文章中,我們以建模工程人員的角度來研究幾種可能的建模流程及其利幣。先申明的是本文中所提到的幾種其它商用程式範例均以在網上可合法公開取得的資料為準, 所參考到的文章已列於本文之末。
IBIS-AMI模型:
不論欲建為其建模的SERDES設計是多麼的精巧複雜,最終要做的事仍是要以C語言將其以合乎AMI API的三到五個函式(取決於要支援的IBIS SPEC.)寫出來並以編譯器在相對應的系統上做出.dll/.so的格式。要先說明的是API雖必需以C語言寫出,但其中的運作(即函式叫進來後是怎麼算出SERDES結果的)並不以C語言為限。比如說用戶可以用matlab寫出其中的計算並以p-code, 可執行碼或函式庫的形式與外包的C語言進行資料交換。不論如何,這套程序所要進行的工作仍然是如何能將SERDES的運作轉成相對應的源碼(source codes), 在此之上,另要考量的則是如何做才能使得產出的程式跑得快、算得準、容易維護又延伸性佳。
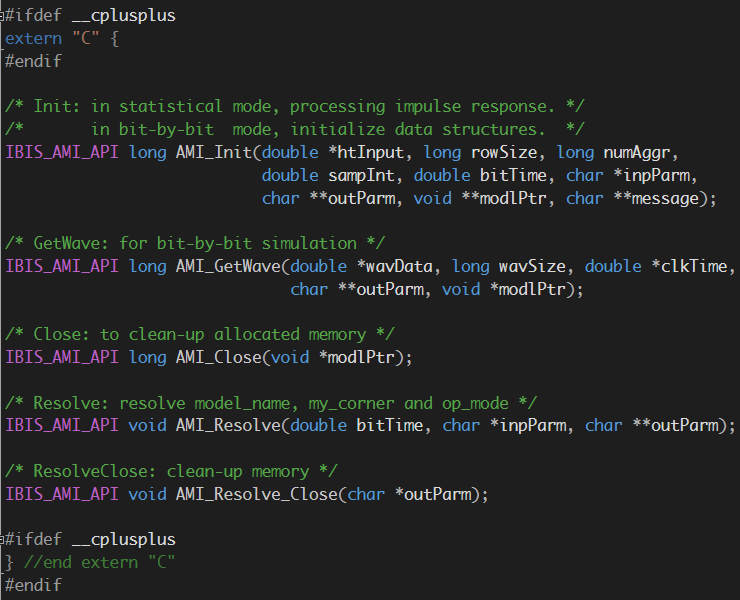
IBIS-AMI應用程式界面
為達此目的,一種相對簡單的建模流程是利用程式自原始設計自動地將源碼產生, 也就是所謂由上而下(Top-down)的設計流程。
由上而下的建模流程:
一般硬體的設計流程都是由上而下的:一開始是做佈線規畫(floor planing),然後必需有的各功能以方塊圖的方示表之,在此階段,各方塊圖內的細節先不是重點,要求的是各功能區塊間的行為互動、資料交換標準、及時域或譟聲的預算或容忍值等等。在這之後各設計人員或團隊才分開並針對每一個功能區塊做實體上的設計。最後把所有的設計整合起來做最後的整體分析或仿真。以此設計流程而言, 一般會有可編輯原理圖(schematic)的軟體讓設計人員把現有函式庫或樣版(template)編輯並接連起來, 而每一個區塊也常是各自有其階層性(hierarchical), C/C++源碼產生是由軟體將每一層的設計逐層逐級地產生。
要將設計轉成源碼, 如果順利的話一般是設計人員先右擊各功能區塊且設定要外顯(expose)的參數及名稱或變數範圍, 然後透過一程式產生模組來將設計轉出對應的C/C++源碼。就IBIS-AMI而言因其不僅有功能上的要求,在API函式的名稱及參數上也有規範, 故常還要另外有一個AMI專門的外掛來進行這些動作。
就這種程序而言, 用戶只要專注在SERDES的設計就可以了而毋需去考慮產出軟體的內容細節及品質。因為這兩家公司在業界也算有名,所以一般可相信以這些源碼做出的模型在實際運作後也能產生和原設計幾乎近似的結果。
電腦產生的源碼:
由電腦或程式自動產生的源碼, 可以看到軟體”很忠實”地如原理圖般一階一階地把它們串起來了,但坦白而言, 可讀性、維護性及延展性可能都不高,其次,不論如何為這些程式做更動或調整, 下回當再次將設計右擊滑鼠產出源碼時,所更改的這些部份又都將被覆寫而白作工了。也就是說,這種由上而下的建模方式在下端(即已產出的AMI模型)做的改變更動大概都無法回溯置回原始(上方)的設計裡。
我對這種由上而下的AMI建模方式的看法是:
- 適合給有所有原始設計、且又不想管CODE的工程師用
- 由這些程式自動轉出的程式:
- 應能算出準確的結果,(如果不是的話就麻煩大了… 因為不會有最原始的程式碼可供查驗偵錯)
- 運作起來跑不快, 至少以目前所見的情形都會是如此
- 結果源碼可讀性不高…無法強制依某種coding guideline來產出, 所以並不容易維護及做長久性的支援
- 由上而下是單向式的, 改變的源碼無法回頭標註在原始設計中,所以下回再次產生源碼時可能就又被覆寫過去了。
由下而上的建模流程:
若是以軟體架構的眼光來看AMI建模的需求,又會做如何的設計流程呢?猜想應是會和由SERDES工師師來做不同, 一般而言, 可能會做如下般:由下而上(bottom-up)式的規劃:
- 首先, 先定義出AMI建模中常會用到的幾種功能區塊, 諸如
- FFE: Feed-forward equalizer, LTI, Time or frequency domain
- LPF: Low pass filter, LTI, freqeuncy domain
- CTLE, Bassel, filter based IIR/FIR etc
- DFE: Decision feedback equalizer, NLTV/digial, time domain only
- CDR: Clock data recovery, NLTV/digital, time domain only
- Coder: various coding page
- 64b66b, 8b10b etc
- PRBS: Pseudo random bit stream, PRBS7, 10, 15 etc
- AFE: analog front end to convert pulse to shape with Rt/Ft/Swing etc
- 其次, 就這些區塊為透過OO的要求針對AMI來做設計:先定義出軟體界面、基礎類別及要以虛擬函式來執行的相關運作等。
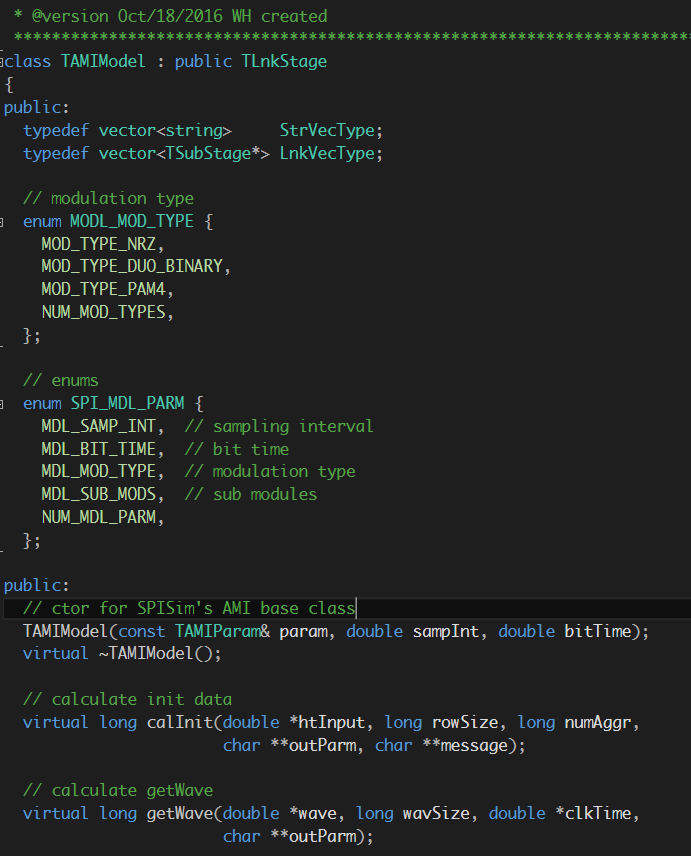
- 而後,針對不同的區塊進行實作, 並在上層要連結起來的階層以”更優雅”一點的方式整合
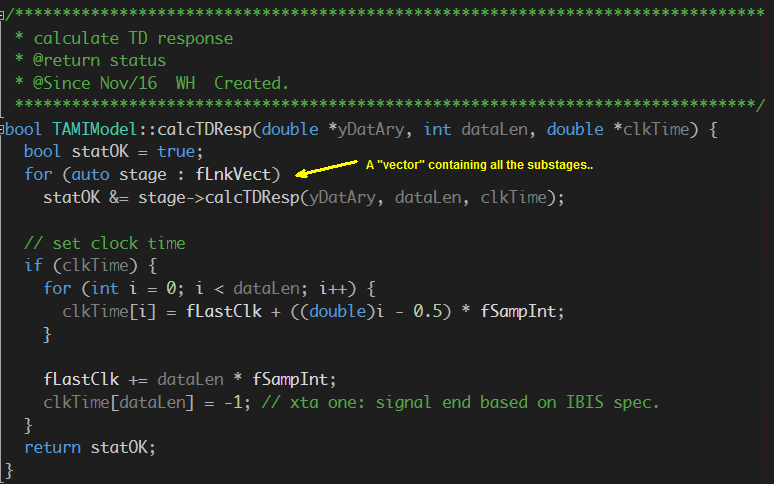
- 這點可算做加分題:可順便考量更進階的外加功能(諸如加密, 為不同CTLE或FFE組態做切換的設定等等)可如何地透過.ami檔來進行等
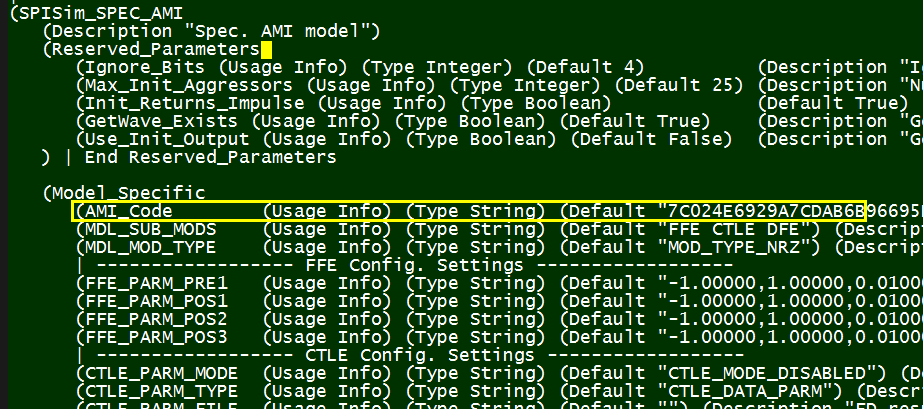
因為這些源碼是手動寫出來的…而非機器程式一貫作業產生的, 所以在可除錯性、程式易讀及可維護性、以及可延伸性上應都有更好的結果,再加上適當的說明文件, 這些模型可視為是公司軟體智財的一部份而有其價值且可長久使用。
在運作準確性的要求上:
- 這些源碼應儘量不要是為單一設計而做, 所以不應有hard coded數字的情況發生,所有設定應儘量參數化以供自動優化用
- 可透過sweep, lest-squared-error based fit, 或其它的優化方法以取得一組能和原始硬體設計效能最近似的參數供模型使用, 也就是說, 以此法得出的模型,不能假設其必然準確,而需另下功夫才能達到這要求。
我對這種由下而上的AMI建模方式的看法是:
- 適合給懂得OO又對軟體編程有興趣的工程師使用
- 因為大都是人手工寫出的軟體:
- 需另下功夫以先確保軟體品質,而後再求精確性
- (做得對的話),應會跑得更有效率
- (做得對的話),會更易維護並延伸
- 可重覆使用性高(軟體的本質),長久而言應更具經濟效益。
資料表單式的AMI建模:
綜上所述, 兩種AMI建模的流程都各有利幣,難道不能有兩全其美的方法嗎?
當然是可能的…但並不相對簡單, 究竟即便是工程師也各有分工專業,這也就是為什麼提到AMI建模時需要軟硬體相關知識,再加上DSP, 科學或工程計算等等的跨領域背景要求了。
大致上來說, 我認為如果能將兩種不同流程裡的短處減至最少,則就有近似兩全其美的條件;比如說, 當我有機會找到其它EDA廠商的AMI元件庫時,很高興地發現其實它們的設計也都如bottom-up或軟體模組的思維一般是很有完整性的, 之所以會在由上而下流程走過後產生令人不敢恭維的源碼是因為SystemVue(Simulink大概也一樣)這套軟體給一般設計使用(就像CPU一樣, 什麼都能做),也就是說, 它們的設計理念是:我們可將任何設計轉出相對應的源碼, 轉出後的品質等是其次的考量。
既然要改變大公司現有軟體應用領域大不易,則從另一方面來思考, 我們也可從現有的很多(開源等)DSP或濾波器函式庫來做運用而非重新發明輪子般地從頭做起, 在這些已經過較多測試函式庫上再以軟體工程的思維(而非廣義的自動軟體產出)來做AMI的建模應是更易著手的方案。所幸的是這類的開源函式庫很多,其實就連上述兩套體體裡也處處可見運用這類公用函式連的踪跡。更有甚者, 很多的AMI功能其實都可先編譯出來, 再事後透過外顯的.ami檔案來將各功能加以組合, 從這觀點來看, 就像是以datasheet/spec來將已做好的AMI模型透過.AMI來自動產出一樣。
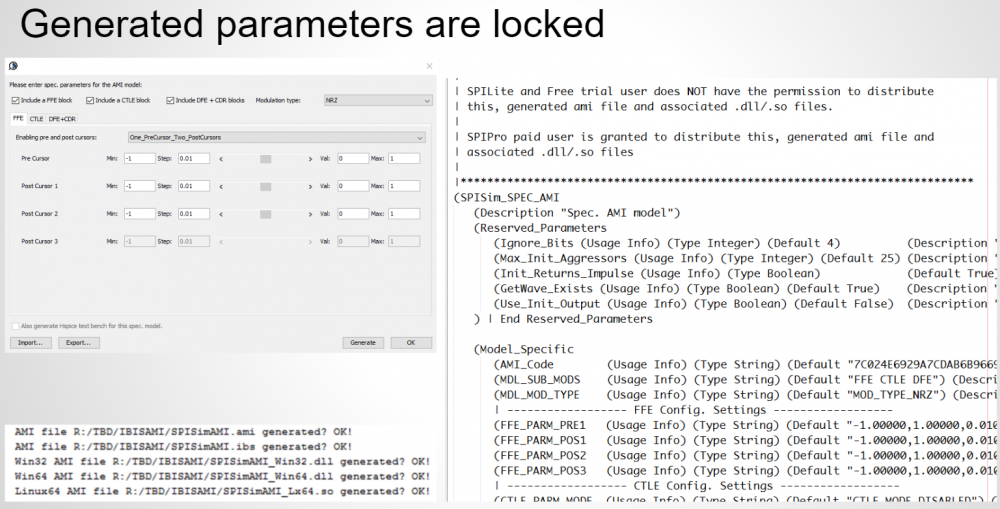
最近其它先進所發表的一些文章, 及以諸如我等較小EDA公司所訂出的AMI建模方案都是朝這個方向進行, 也因此更能證明這個折衷方案是能得兼由上而下及由下而上兩不同流程優點的一可行方式。
參考文件:
2015 DesignCon paper: [HERE]
2016 IBIS Summit paper: [HERE]
2016 DesignCon paper: [HERE]