

IBIS-AMI的建模通常是在IP研發快完成時才執行;也就是說, 一般是先有如用Transistor設計的IP出來, 再開發出AMI模型以便一同釋出。模型之所以需要是因為IP智財商一般不會把設計的細節揭露、但其用戶又需要有相對應的模型才能做分析。在實務上, 我們也會看到倒過來的情形:即先有如behavioral之行為模型或加密過的spice模型,甚或是Lab裡量測出來的數據後,再回頭來想做出AMI模型的案例。這種需求之存在大都是因為原智財商或者沒有AMI模型或者索價甚高。當然也有可能是用戶想先用能不同的參數找出在其設計裡最佳化的組合後再回頭來找是否有相對應的元件或向原智財商要求調校等。
在這篇文章中, 我們將就一最近碰到的、上述情況中的後者來做案例研討,我們的目的是要來示範建模的一般流程並以本司的軟體做為示範。下列為討論的大綱:
- 相關IP資料
- 建模標準及需求
- 建模流程
- 模型之釋出
- 其它想法
相關IP資料:
對此案例的設計而言, 我們收到的資料是一以此design IP架在一般SERDES的通道的一網表(netlist), 其設計如下:

在TX及RX端都是含有可調參數的加密過後的HSpice, 當我們挑其中一組參數組合來進行仿真時, 可得到有效(即有意義無誤)的波形如下:
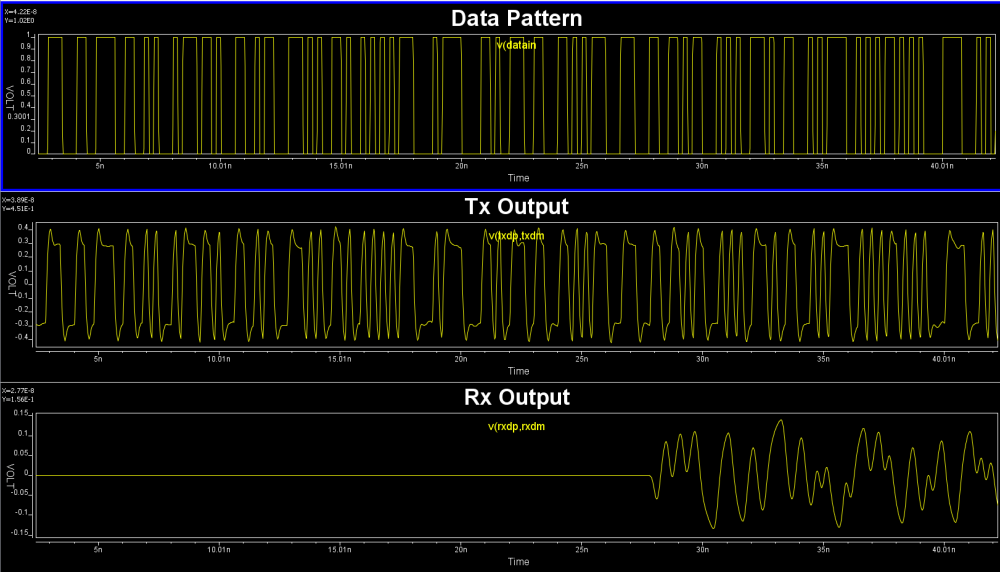
由於這是HSpice的網表, 所以我們可以很自由的去probe不同的節點並視需要去改變仿真的形式(如從瞬態改成小信號AC或是轉移函數等)。
建模標準及需求:
客戶自原IP商所拿到的除了上述網表外, 只有一個簡單的檔案約略說明各方塊及參數的意義和範圍。其中, Tx, Rx封裝模型均是spice sub-circuit. 通道(channel)是一S參數。而Tx/Rx都各含有Typ/Min/Max corners。其次, 在TX端有可調振幅電壓的參數, 有一分為7-Bit及6-Bit各可做為振幅乘數及EQ幅度的參數, 也另有一個boost = on/off旳參數來開關EQ的運作。
針對這些設計參數, 我們的建模目標是要產生相對應的AMI模型以對應不同的參數效能, 也就是模型使用者要能透過AMI本文檔的部份來調整模型效能。其次, 由於本司的軟體係做為建模工具, 所以建模者需要能以不透過寫任何C/C++程式或編譯的形式來達成建模的需求。
建模流程:
以此”逆向工程”來建模的案例來看, 原IP使用者大致是沒有最原始IP的設計的。也就是說, 諸大EDA商(如SystemVue, SimuLink)等的Top-down流程在這種案例上可能沒什麼用武之地; 因為沒有原始設計、自然也就沒有可以自動產生AMI C/C++碼的可能;取而代之的,我們得先依仿真結果來倒推出原IP 的設計架構, 再用試誤法來推出在某組效應下應有的AMI參數。這建模細部可又略分如下:
- 建立Tx/Rx測試設計(test bench)
原廠所附完整通道(full channel)的網表裡含有建模並不需要的部份, 比如說封裝及通道的S參數就是依設計不同而不同的, 所以建模的第一部就是把實際相關的TX/RX部份萃取出來;其次, AMI模型的一項假設是所有模型的輸出入阻抗都是很高的,所以抓出的設計也就不需含有負載的部份而只與其輸入輸出有關。
就TX而言, 其輸入為PRBS而輸出為簡單的50Ohm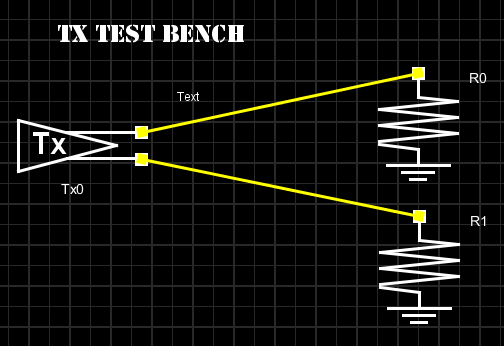
跑出的仿真圖形如下:
當我們把TX直接連到RX的輸入時,跑出來的輸入輸出眼圖如下:
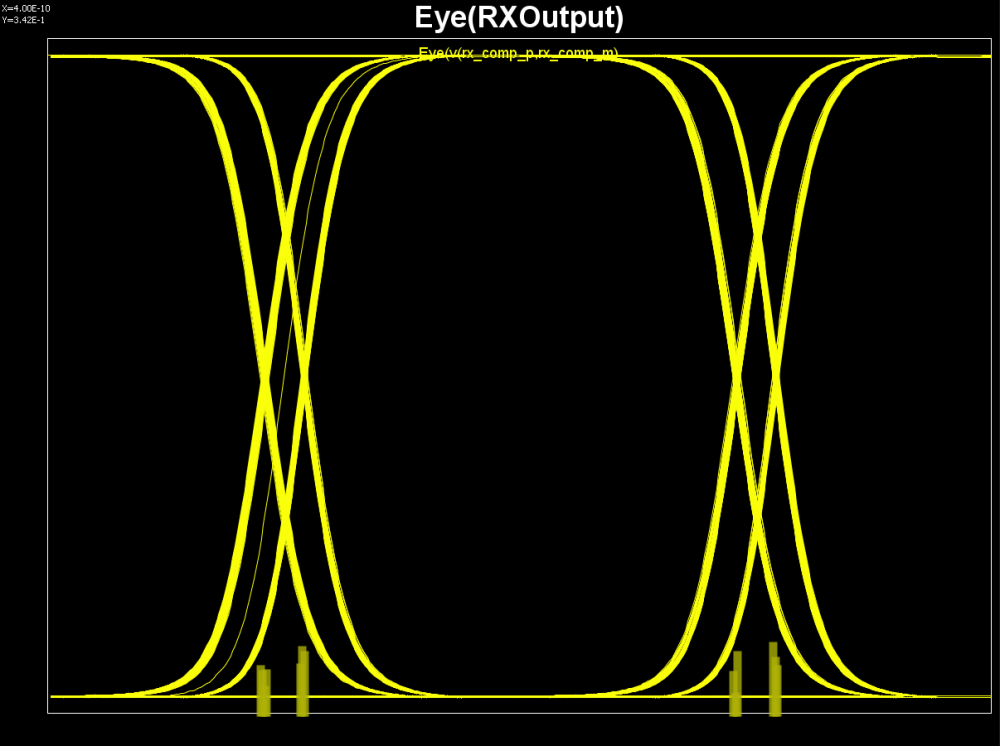
由於眼圖中並未看到如DFE般因force zero而產生特有的突降, 故我們可推測RX端約略是由像是CTLE般的boost filter所組成;依此我們可假定RX test bench如下:

依此跑出的頻響如下: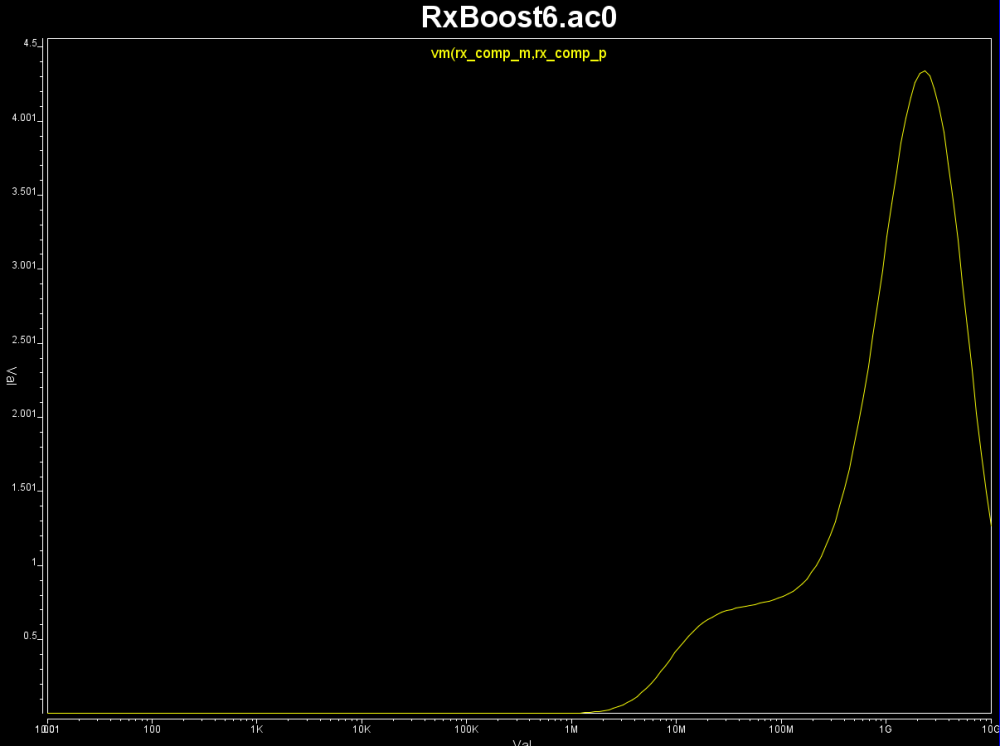
其次, 由於下一步我們需要依現有的輸入來套到我們假設的AMI模型上, 再將其輸出來和由HSpice跑出的輸出來做比較,所以在此準備階段, 我們由透過本司的VPro來把輸入值轉出成單獨的波型檔案。下面會提到的SPISimAMI.exe就要利用到這個檔案來驅動AMI_Init 或是AMI_GetWave函式。由於HSpice是一variable time-step 仿真器, 要在其輸出probe得波形中得到相同時步間隔(fixed time-step)的資料,我們還得加上此一選項敍述:
- 定義模型架構
有了測試電路, 下一步就是來倒推出可能有的模型架構並看看我司現有的Spec模型可否支援此一設計。
對於利用HSpice進行的TX的仿真結果, 我們可以看到兩個特點:
- 有de-emphasis, 其發生點在peak值之後
- 振幅和原輸入並不在同一位準:輸入是0~1, TX輸出是-0.5~0.5, 其次, TX的輸出在上升及下降端都有如RC的充放電效應而非方波, 也就是有應是有AFE(類比前端, Analog Front-End)的存在。
對於de-emphasis的部份, 我們利用本司Spec-AMI的what-if功能來看看在不同的pre/post-cursor情況下輸出的效果為何, 我們依次單獨把某一de-emphasis值調-0.1: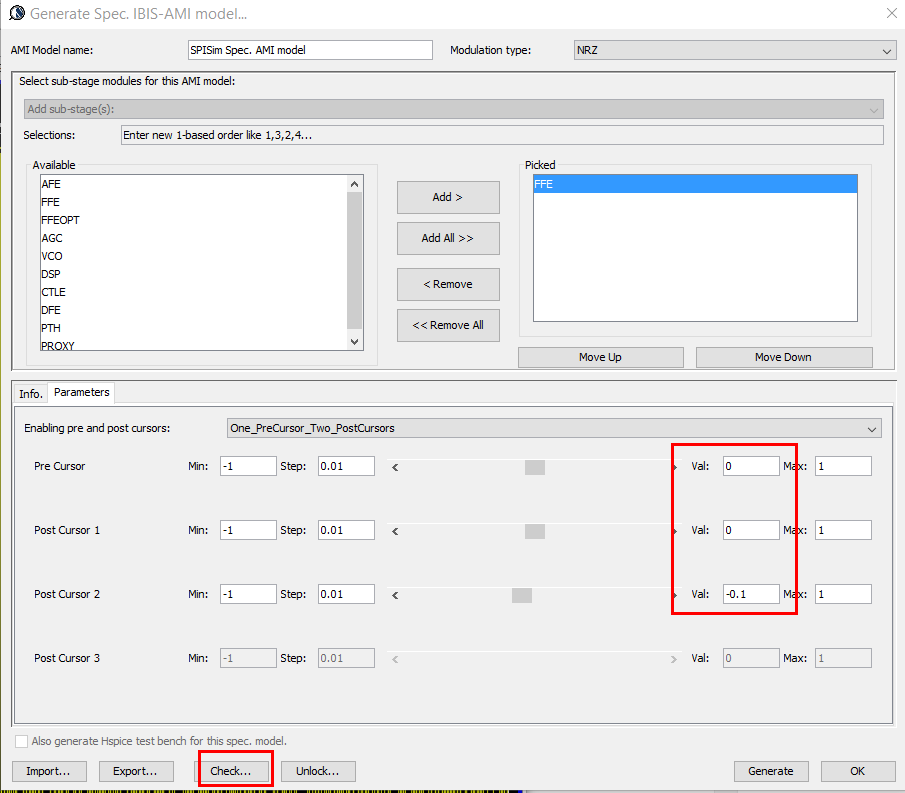
再透過即時的測試驅動來看對PRBS的效應: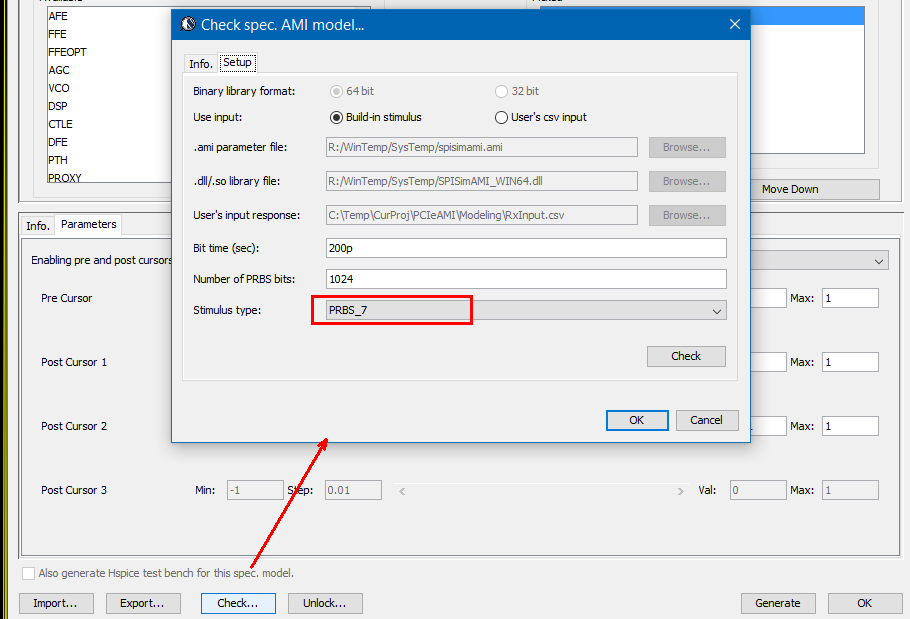
可得如下比較波形: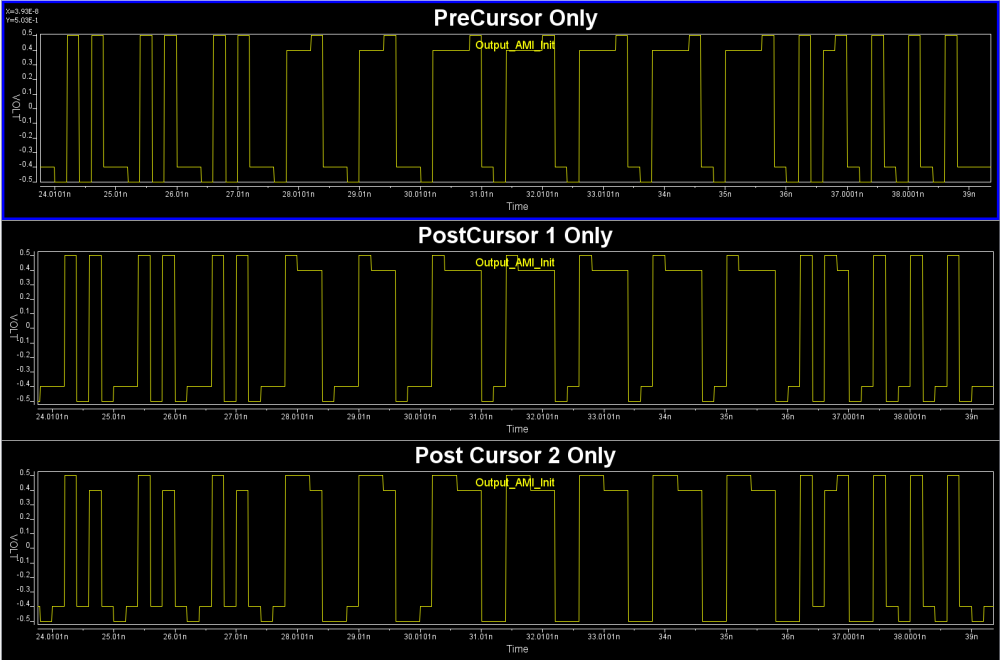
由於我們的實際波形de-emphasis是在峰值之後, 且延遲只有一UI, 故和上圖中間者相合, 也就是確定為1 statge FFE with PostCursor 1 only的存在。
而類比前端部份加在前述FFE之後, 在本司模型中, AFE將對上下端的峰值加以箝制, 所以實際波形的峰值也就是我們模型的high/low rail voltage參數;剩下的就是調整RC參數來得到對應的slew rate了:
經過幾次的調整試誤, 我們可以利用FFE+AFE兩級來和某一參數組合的HSpice結果來對對照, 其結果如下 (藍為HSpice, 紅為AMI結果):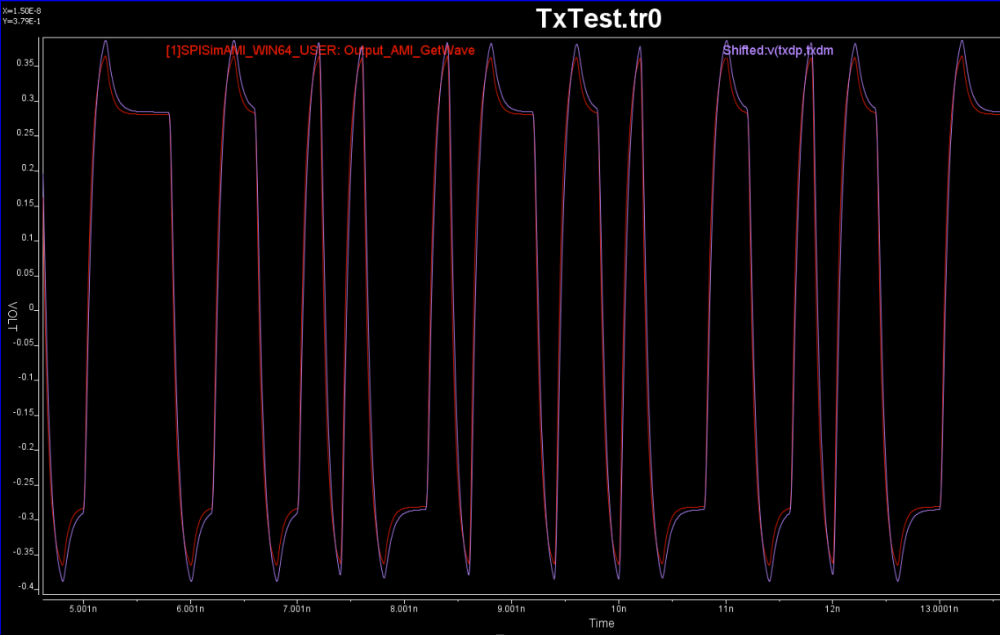
RX部份也是同樣的步驟, 我們利用之前已截取的RX輸入信號來驅動CTLE級,並對部份參數做試誤法的調整,即可以很快地得出一相仿的波形:
下圖中綠為HSpice結果,黃為AMI結果。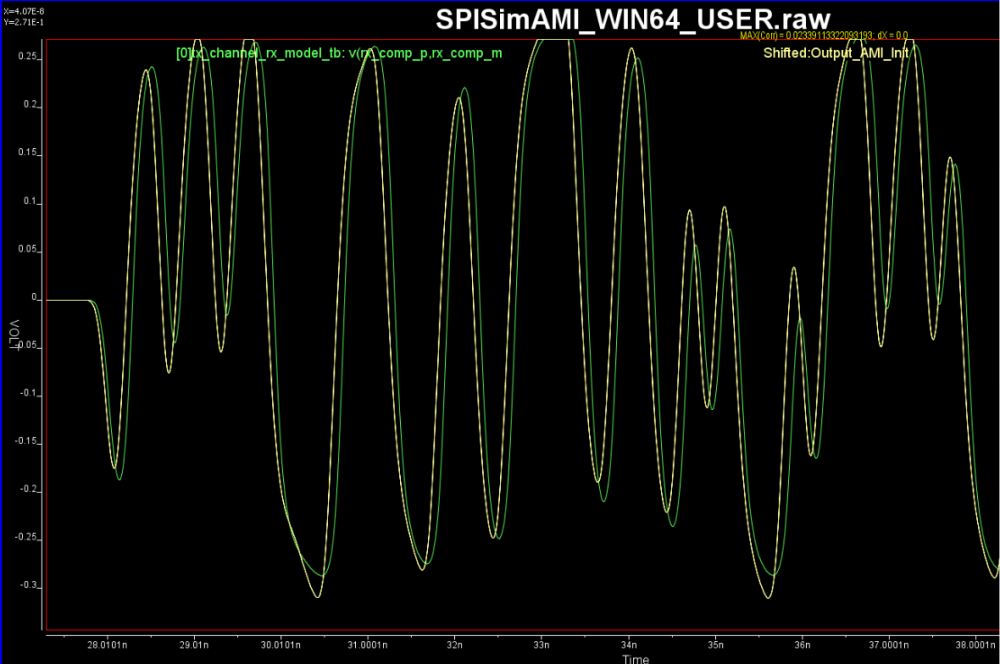
也就是說,在這一步驟中,我們針對某一特定參數組合下的HSpice仿真結果, 來逆向推出AMI模型應有的架構, 再透過一些試誤及參數的調整,使得現有的AMI模形得以產出和原仿真近似的結果。結論便是:本司現有的AMI模型,是足以供此建模所用的;而接下來的挑戰, 便是如何快速有效地針對不同的參數組合找出其所對應的AMI參數並產生可用的模型供釋出。
由於RX較為簡化(沒那麼多參數組合)且以下的步驟兩者相似, 故下述的討論單以TX端進行。
- 制定仿真計劃
在制定計劃並進行大量仿真前, 我們也先針對TX端那有6-bit及7-bit旳參數部份單獨做一維掃描,並不需要掃所有的2^7=128及2^6=64個值, 只要挑一些來看看它們是否相互獨立, 結果如下: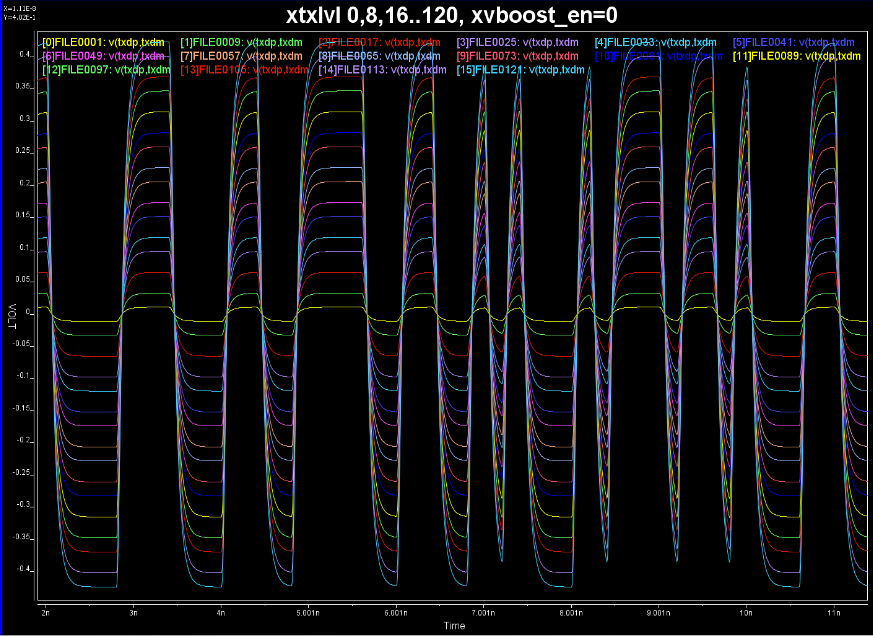

可注意到的是slew rate及峰值部份並未因EQ值的設定而改變, 可見其相互獨立性;再者,這些值的間距也似與所設定的BIT值呈線性類比的關係, 這也就揭示了毋需全面sweep而可透過linear interpolation減少工序的可能。
以此例而言,欲為TX部份的五個參數做全域掃描, 所需進行的仿真可達2^6(de-empasis elvel) * 2^7 (swing level) * 3 (corner) * 2 (boost flag) * 3 (voltage rails) ~ 150000個, 由於線性類比可內插性, 我們加大間距而只掃部份的bit組合,依此想法, 我們透過了SPIPro的MPro制定了產生2403個仿真的計劃: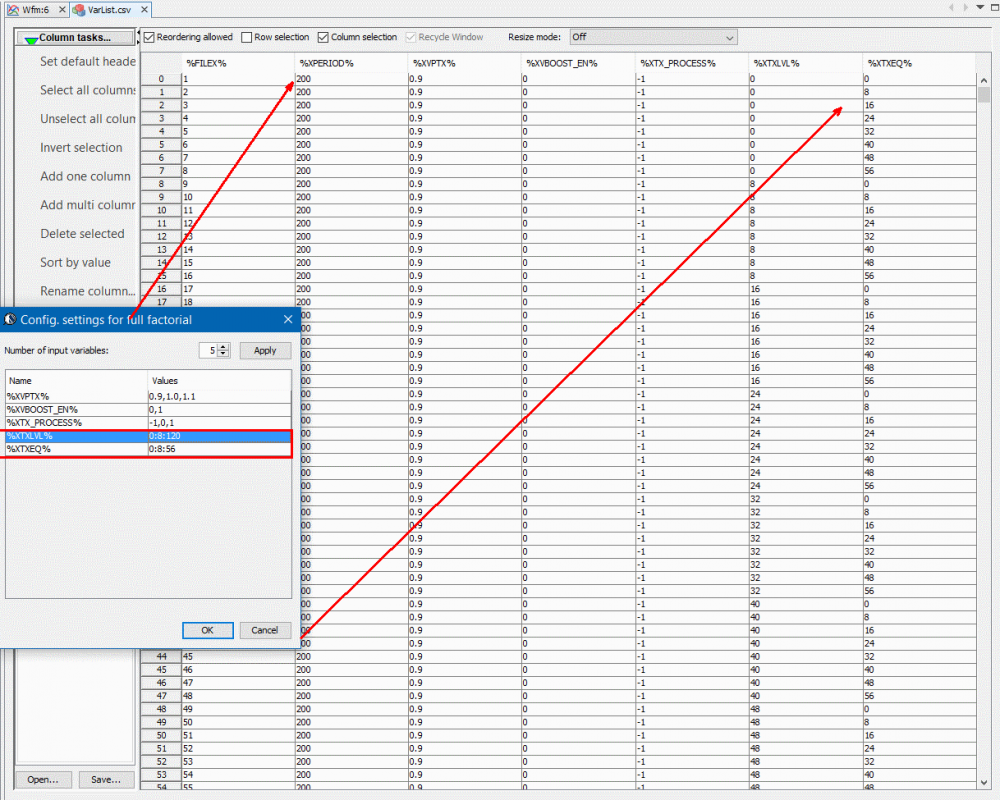
這2403的case是原150000case的近六十分之一, 其次,我們把TX測試電路參數化, 如下所示:
也就是說, 變數可以用%來含括(如%XVPTX%)而在稍後做取代; 上面表格的第一行(header)即為變數名稱, 其下每一行(row)裡都有該變數在那個行所代表組合裡的值;這裡描述的流程有點像是一般SI裡DOE的步驟; 當我們有一樣板化的TX測試電路及這一表格後,MPro即可據以產生相對應的兩千多個spice檔並以HSpice進行批次仿真, 因為只是驅動電路而無channel的存在, 所以仿真跑得很快…一個小時內所有的兩千多個結果就都出來了。接下來的就是要對每一個結果找出對應的AMI參數。
- 參數的搜尋及調效
之前我們已證明對某一參數組合,我們可以”兜”出其對應的AMI參數以得到和HSpice相仿的結果, 故在這一步驟中, 所要做的便是對已跑出的2403結果裡的每一個都做同樣的動作。其流程如下:

如果是要用人工進行的話,這2403個CASE當然還是太多…得再減少到成只有50~100左右, 若用程式自動化來跑則無此顧慮。從結果來看, 因為即使不同的CASE其輸入的PRBS波形都一樣, 也就是說在輸出端會出現峰值及EQ變化的時間點也都一樣,所以我們大可透過程序來自動進行。
在我們的做法中,我們首先先把之前證明可行的FFE+AFE架構的AMI檔參數化如下:
其次我們觀查某一組EQ及峰值掃描的結果: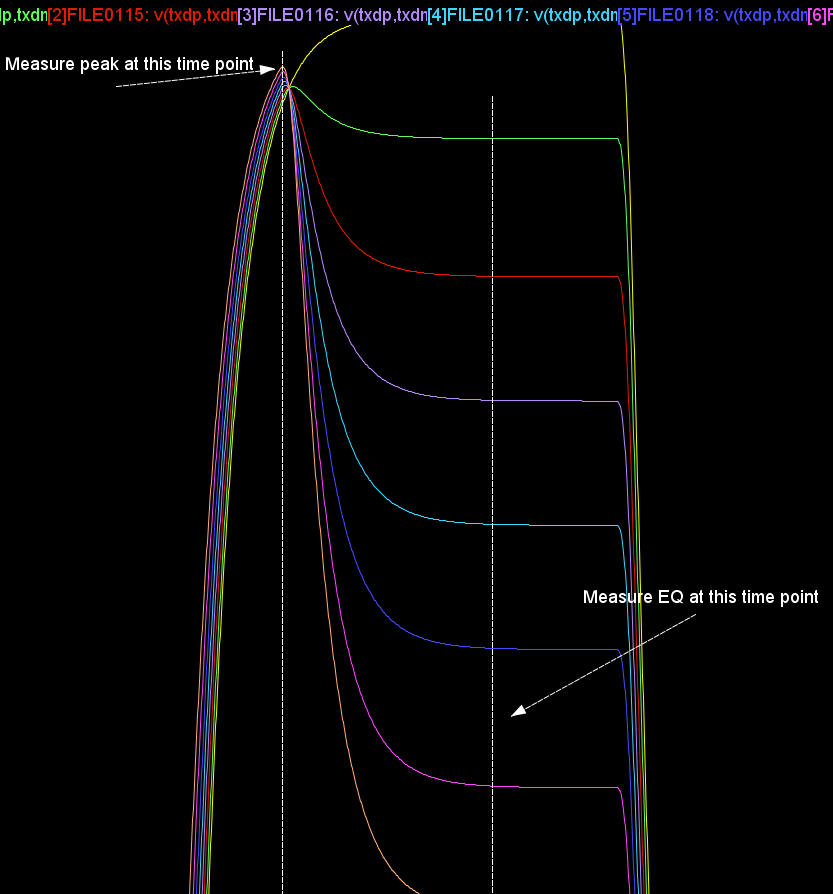
決定的做法是:先讀取HSpice仿真值裡的峰值設定, 由此決定了上面樣板化AMI檔裡的%SWING%變數,其次,再以仿真結果的EQ值為目標, 透過二分搜尋法來變化樣板AMI裡的%FFE_PARAM_POS1%變數, 一旦有新的AMI檔後就把最開始抓下的等步輸入來透過SPISimAMI.exe驅動此AMI檔及.so/.dll, 結果自動和仿真值相比直至其差相近或二分法未收歛為止。
我們的SPIProPro有支援類似的自動化步驟,即使沒有SPIProcPro, 這部份的自動化程序用perl, python或matlab來做都遠比寫C/C++的AMI程式碼來得簡單,其結果, 我們能在約一小時內就把所有的2403個結果處理完並找到對應的AMI參數值。
這是SPIProcPro的部份設定: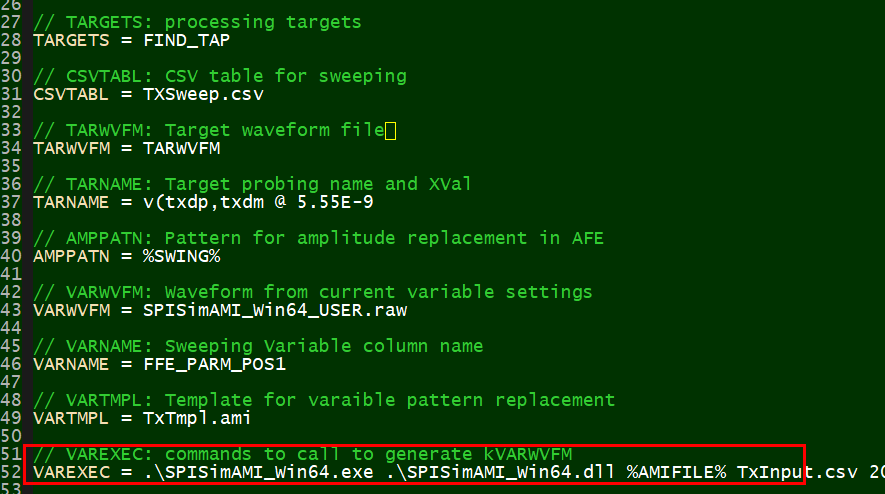
對於2403個每個CASE, 其後處理之後每個都會有個別的、內含有找出AMI參數的csv及log檔產生,而這些檔案也被程式自動組合成一個含有2403行的CSV檔,最後用MPro把原始輸入參數和此計結果檔左右相結合, 所得到的就是一個不同情況下的輸入及找出AMI對應參數的對照表。
模型之釋出:
上一步驟的CSV檔案結果如下所示: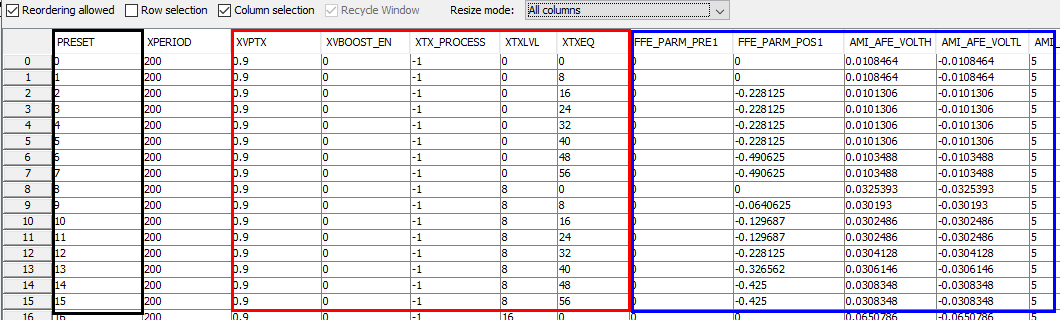
其中右邊藍框內的參數是本司SPISim AMI模型所需的參數,這些欄位的第一行, 即表頭部份,有著和AMI參數完全相同的名稱; 而之下的每一行就是不同設計參數下由之前步所驟所找出的相對應的AMI參數。
記得在之前定義架構完成後所產生的AMI檔有著我們內建模型所特定的參數如下:
我們所希望釋出的模型能有和原IP同樣的設計參數, 這些參數為上面CSV表格中紅框的部份, 其也為在產生TX兩千多個不同測試檔案中所用到的變數, 而最左邊黑框的部份則是(可有可無)的索引預設(preset)。
我們SPISim內建模型有一個特點: 其可透過此種預設表格的方式來為所需的參數提供資料, 且這設定可很簡單地透過我們AMI的GUI完成: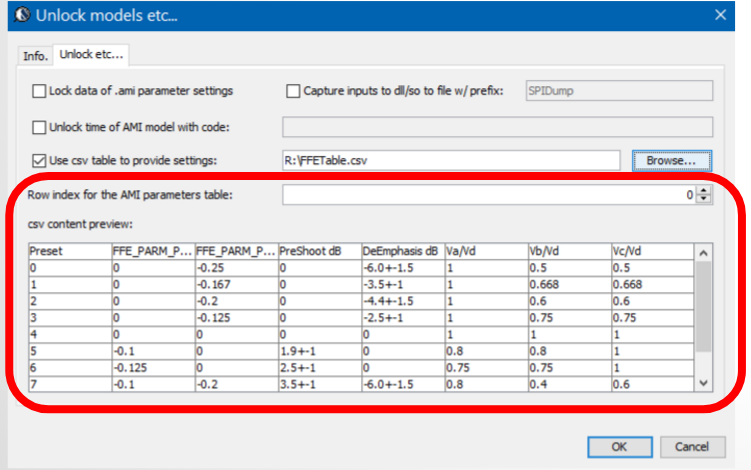
上圖中用的是PCIe的例子,其TX有十一個預設值定義於spec裡, 所以利用這麼一個表格,用戶可只用PRESET的AMI參數便來為其它的, 模型所必需要有的FEE_PARAM_PRE, FFE_PARAM_POS0等變數來提供數值。
而在這個案例裡,我們要用的不是這Preset值,而是各原始IP的設計參數如下所示: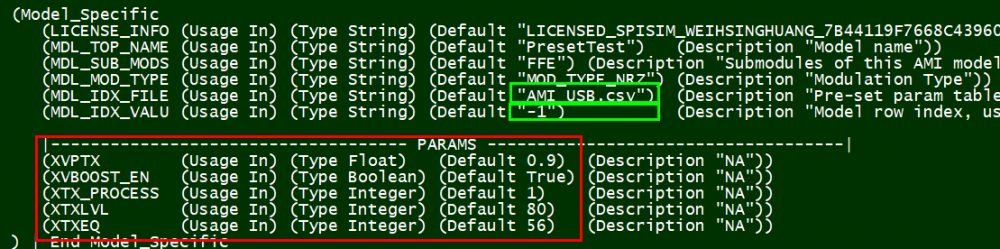
則做法是把Preset值設為 -1, 而後提供如原始IP等相對應的欄位名(上面AMI檔內紅框所示), 在運作啟始階段,我們的內建模型會把這些變數來在CSV表格內去找出過濾出來的行(row), 然後再把那行裡相對應的內建 AMI模型參數套用進去, 如果這些原IP參數裡有至多兩個數值型(而非字串型)的變數沒有找到, 則模型會把最接近的兩行找出來來做線性內插, 而再把內插出來的值傳給模型使用。
也就是說,我們可利用本司模型裡數客戶自訂參數來找出對應內建AMI參數的功能, 以及至多可做二維線性內插的功能來為產出簡單明瞭的模型供釋出。
由這些步驟所產生的最終結果是一個.ami檔, 一個.csv 檔(內含所有對應表, 此.csv檔可為明文或經SPIPro編碼加密), 及一組早就編譯好的.dll/.so檔案。在上述的過程中,完全毋需寫任何C/C++碼或在不同作業系統上編譯來產生AMI二進位檔;即便是.tr0後處理的階段,用人工做至多五十至一百個參數的搜尋、抑或是用簡單perl/python/matlab來進行和SPIProcPro相似的運作,都仍遠比從頭寫AMI模型及編譯來得簡單。
其它想法:
在此案例中,我們透過的是如”逆向工程”般的方式來產生一對照表(.csv)以便為定義好的AMI架構來供值。由於廠家提供建模用的IP是Spice檔, 另一種可能是透過我們SSolver或NGSpiced來直接對所供的Spice檔來仿真(這仿真引擎是內建在AMI模型裡的)並為AMI_Init或AMI_GetWave提供輸出波形。這樣就不用透過各種掃描(sweep)而可提供更直接的對應。但要能如此做的前提是:原Spice檔未經加密(加密過的網表只有HSpice能讀), 未牽涉到製程檔案(要不然大概仍是非HSpice不行)且其網表的語法能輕易地轉換成SSolver/NGSpice所支援的格式。其次, 在參數搜尋方面, 因為我們只有一個EQ參數需要找值,所以用二分搜尋法就可以很快地收斂。但若是有兩個或二維以上的變量需要搜尋…比如說同時有pre-boost及de-emphasis參數等, 則若二維曲面每一點找值不可行(要仿真的case過多),便要考慮使用如gradient descent等的差分/最小能量似的優化algorithm。