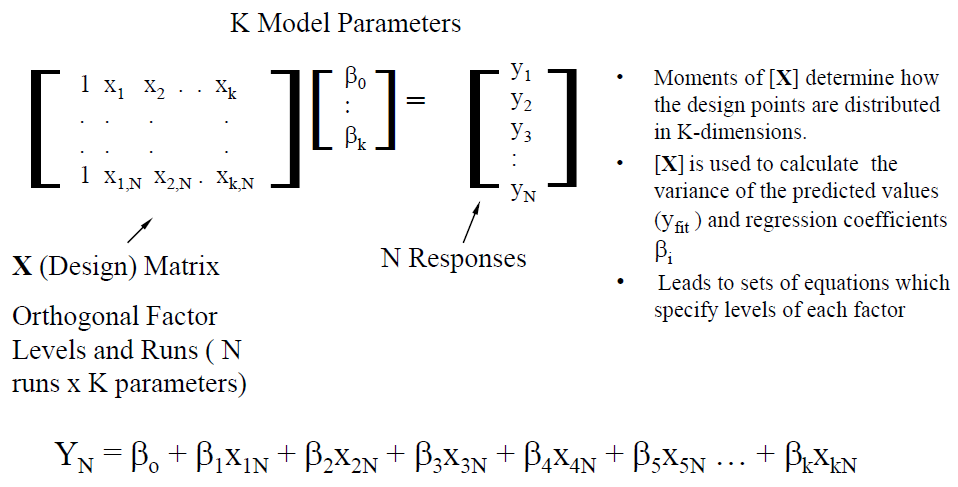
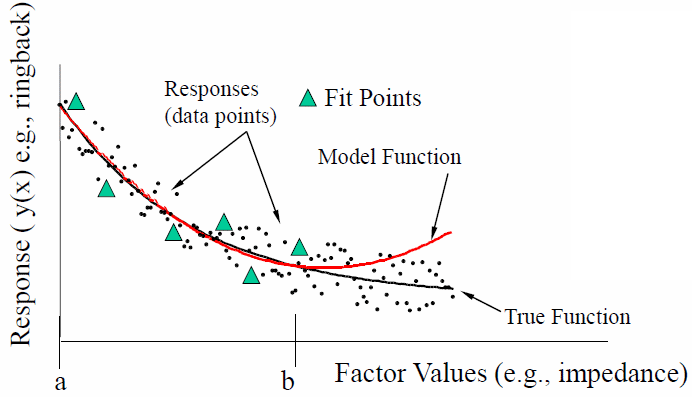
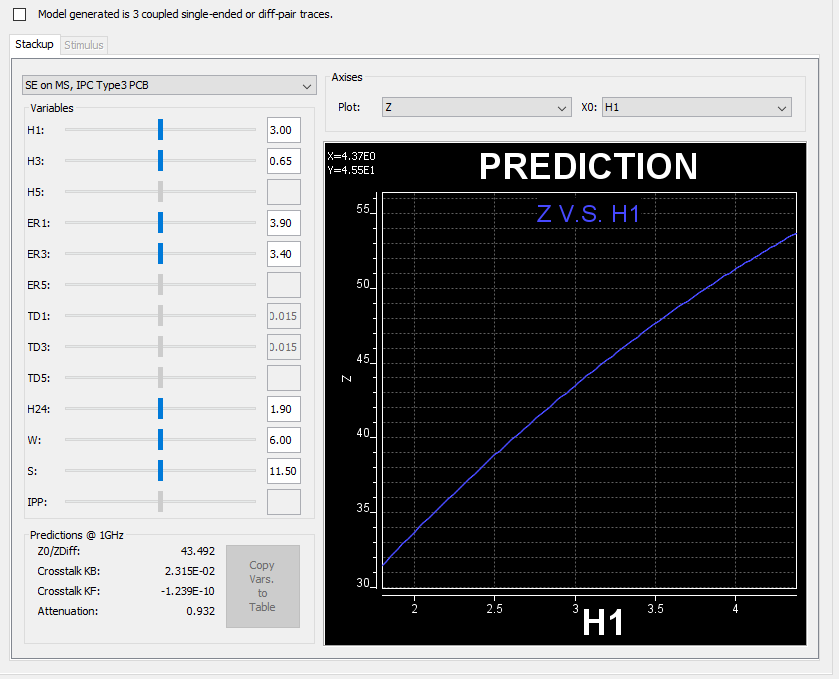
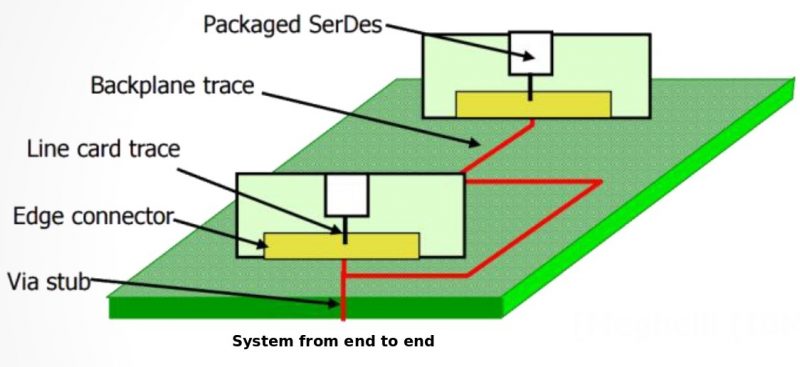
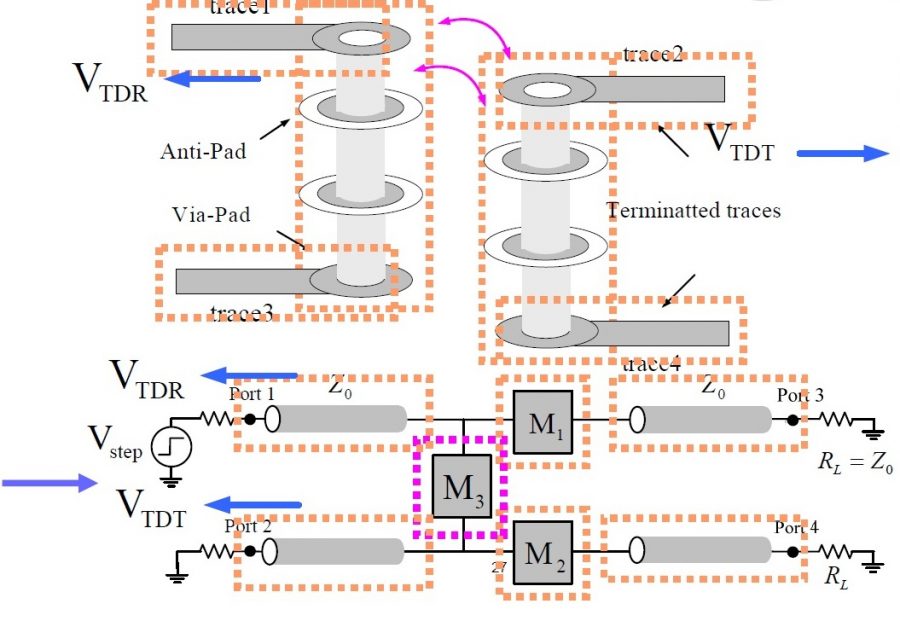
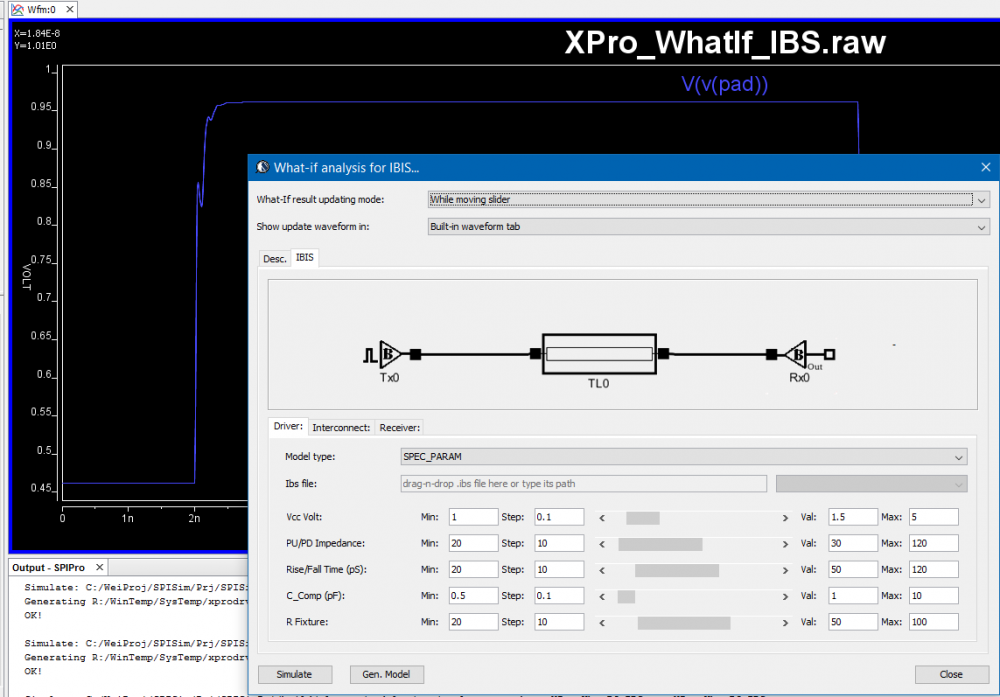
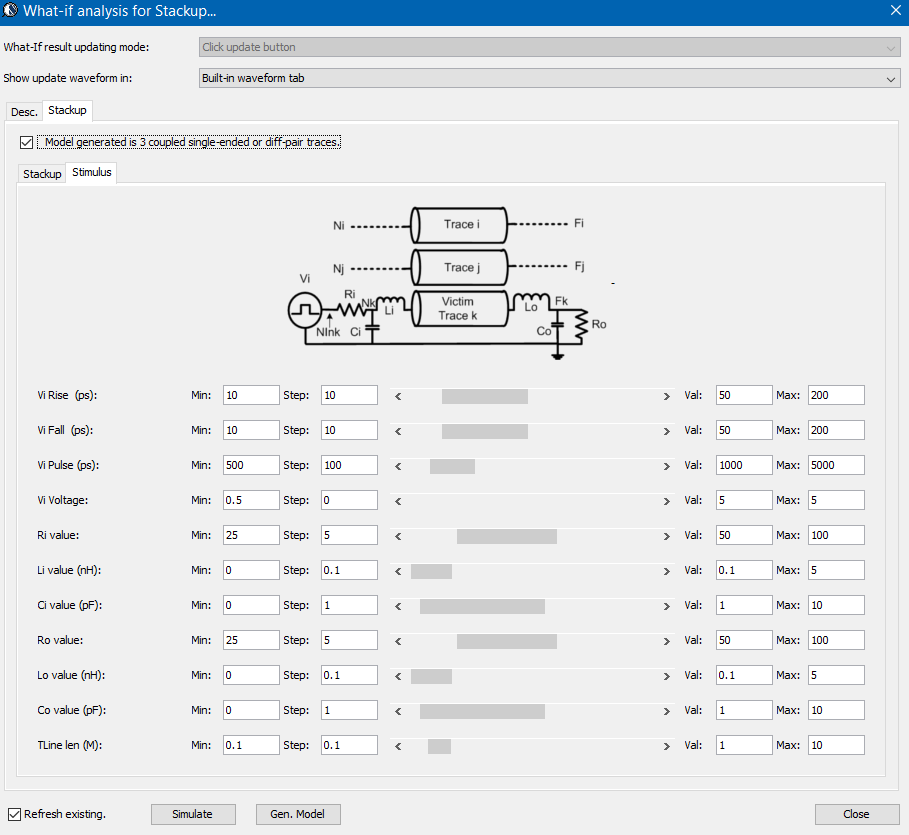
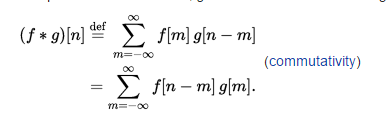在IBIS-AMI的建模領域中, 有一些”黑箱密技”值得一究;它們之所以存在,是為了使整個AMI建模的流程不但更順暢且富有彈性而不僵化。在這篇貼文中, 我們會分享並探討最近本司在建立AMI功能中的一些經驗及技巧以供讀者參考。在文章末也會來看看其它公司的AMI模型有些什麼不同的樣式。
黑箱密技所在何處?
相較於系統分析中所會用到的其它元件模型:諸如傳輸線的RLGC Tabular Model、連接器或封裝的S參數、甚或是傳統的IBIS模型而言,AMI模型本身就是個黑箱(Black Box);其為系統及位元相關、由C/C++編譯而成的二進位檔案;在Window裡, 檔名為.dll (dynamic linked library), 而在Unix-like作業系統中為.so (shared object);這檔案裡都是機器碼;另一相關的檔案、即ami檔、雖是人眼可讀的本文檔,但其含有專位這些.dll/.so檔模型所用的資料,故非可以隨意更改或變動。
對於一個AMI模型開發者而言,即便是他/她對C/C++及.dll/.so編程編譯的過程知之甚詳, 這整個流程走起來也是蠻煩瑣且易錯的;舉例來說:即便在Windows上,相同的原碼也需分別以x64及x86 (Win32)的組態來編譯並測試;在Linux上更麻煩:因為Linux 有很多的Distro (Debian-based like Ubuntu, Linux Min, Redhat based etc)且IT所裝起來的環境…至少在所含程式庫上也不盡相同;好比說”boost” 及”gsl”是吾人在工程及科學計算編程上很常用的開源程式庫,但在以production為導向上的linux機器便未必有安裝,而Linux的主要訴求之一是很多的程式庫都放在/usr/lib或/usr/local/lib裡分享, 所以未安裝此程式庫的結果便是原來在開發者機上跑起來沒問題的模型放到這些其它機器上便Load不起來;常用的解決方案是把所有的機碼都以static link的方式放到.so檔裡,再把symbol給strip掉以減小程式大小,最後再把結果放到不同的(虛擬與否)機上做測試以確保相容性;正由於這些麻煩的過程, 在以往AMI建模的市場或領域僅被少數公司所把持或寡佔, 且在專案的計價上動則要美金數千或數萬元。
在之前的貼文裡,我們提到了將AMI檔和仿真器(circuit simulator)相對比的觀念;就仿真器而言,為某種電路所特別打造的(如cache, memory等高重覆性設計的電路)仿真器固然跑起來較快且有其存在價值,但對大多數的電路設計而言, 用MNA (modified nodal analysis)所建成的一般化的(generalized)仿真器如Spice/HSpice便足夠所需;這些仿真器雖為二位元檔,但內建有如R/L/C/I/V等的基本電路元件;就算是複雜的系統元件如傳輸線或S參數等,也可由外部讀入模型檔而不需要為不同的電路重編一仿真器;也是說:仿真器即便是與OS/系統有關也多半是固定的..一年最多更新幾次,就好像HSpice只有一個…不管你的電路為何;而可變動的部份是用Netlist網表的形式來傳給仿真器,這就好像.ami檔是以本文描述的設定可用來傳給實在不需太常被編譯的.dll/.so檔一樣;也就像有Encrypted HSpice檔一樣;當吾人有敏感的資訊需要傳遞又不想被人看破時,便可以加密的形式為之。
從以上的觀點來看,其實AMI建模的”黑箱”不僅可指所編出的.dll/.so檔,也一樣可適用於所需的.ami檔案, 以下就稍做探討:
.dll/.so檔裡的黑箱密技:

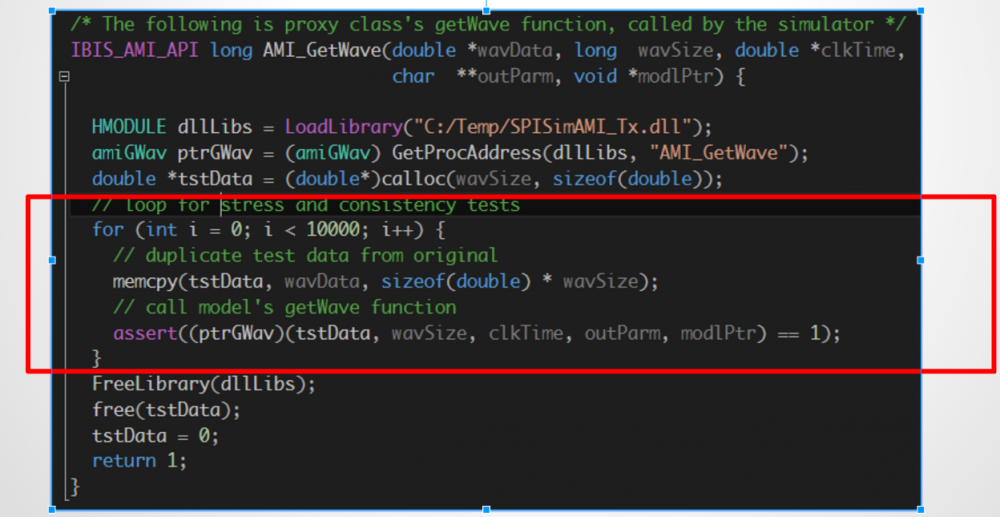
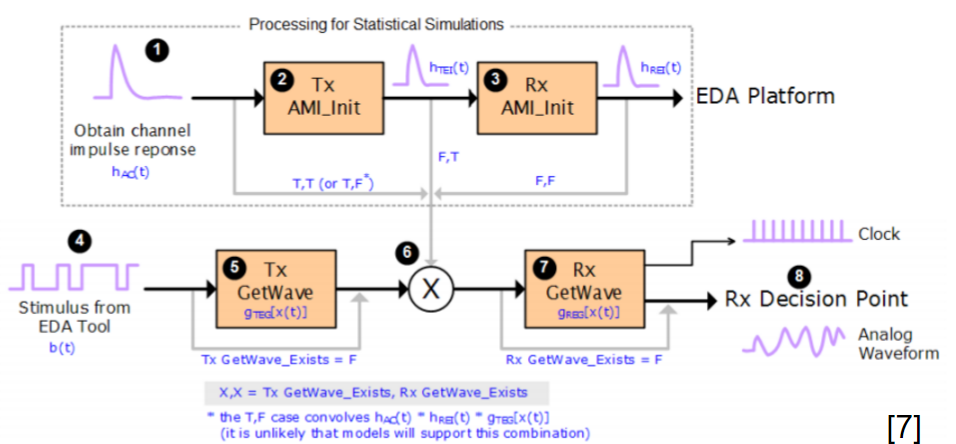
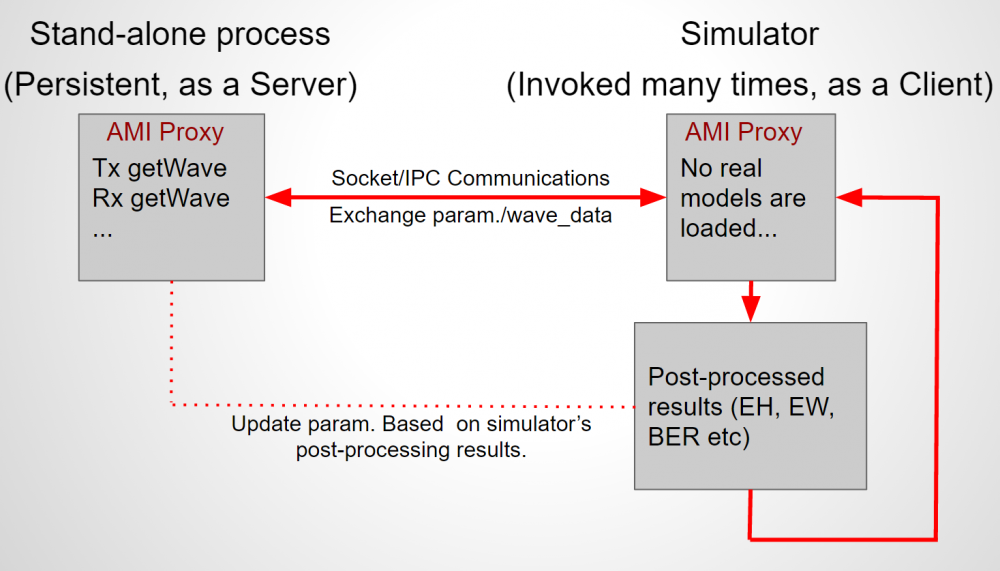
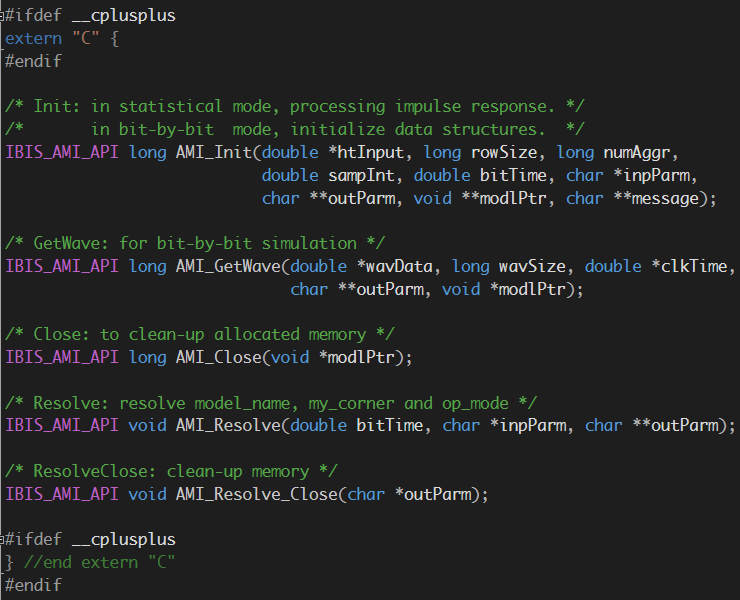
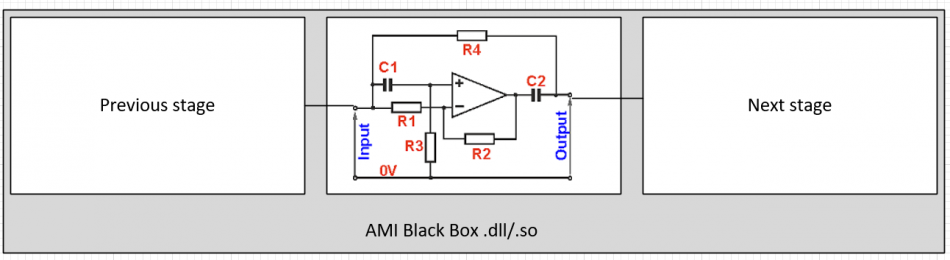
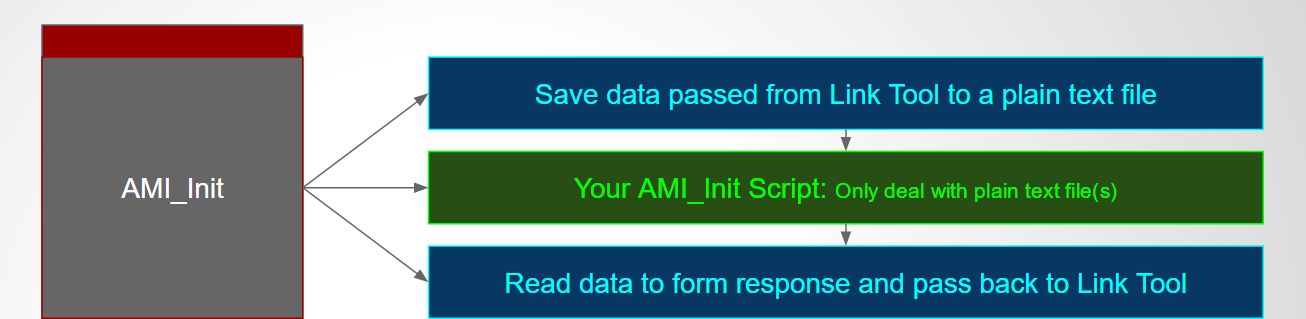
在IBIS-AMI API的規格中, 雖然定義了五個API函式;但實際上最重要的是如上所示的AMI_Init, AMI_GetWave兩者;從它們的傳遞參數中,我們可以了解兩個指標(pointer)即AMI_Init裡的impulse_matrix及AMI_GetWave裡的wave同時負有輸入及輸出的責任;也就是說, channel simulator把資料放在這些指標裡傳入吾人所定義的函式中,計算完成後我們的函式需再把結果放到這些指標所指的位置以傳回給上層;這一個流程以電路上來看的話大概像是下圖:
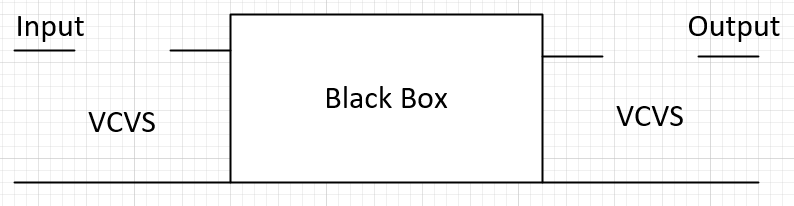
上圖中可看出一個AMI仿真中所沒明說的假設是:下一級的輸入阻抗對AMI來說可說是無限大(好像Rx AMI模型不會因為接上去後就把傳進來的impulse_matrix 或 wave值改掉了,要不然就應有iterative的程序直到真值解出為止), 同理也可套用到Tx的輸出級一樣;也就是說,我們可以想像是有兩個增益為1的電壓控制電壓源一樣, 分別在輸入及輸出端替我們的AMI黑箱和其它電路隔離開來;而我們建模者要做的, 就是專心把這輸入及輸出的關係,透過所編程出的AMI .dll/.so檔來表示出來。
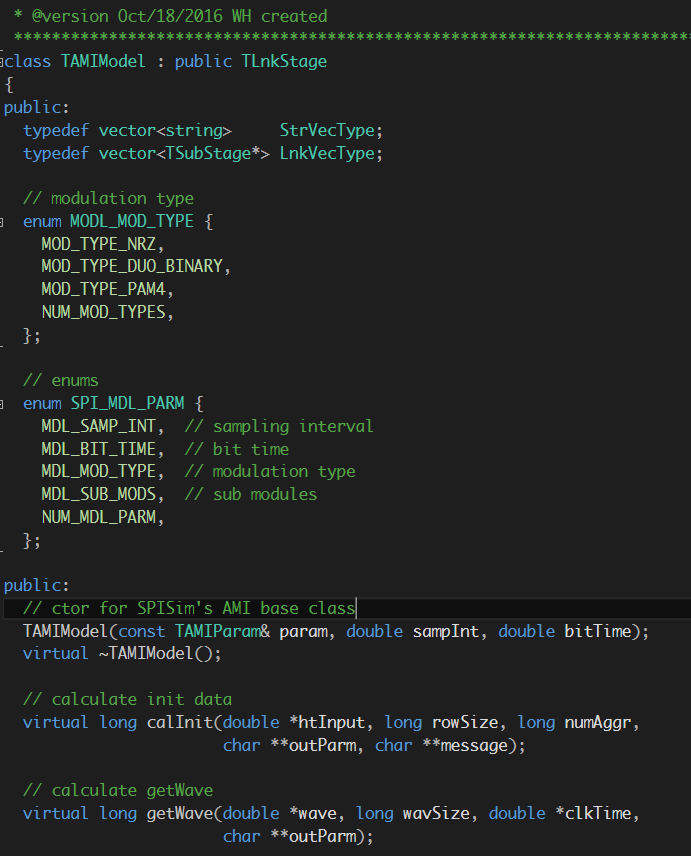
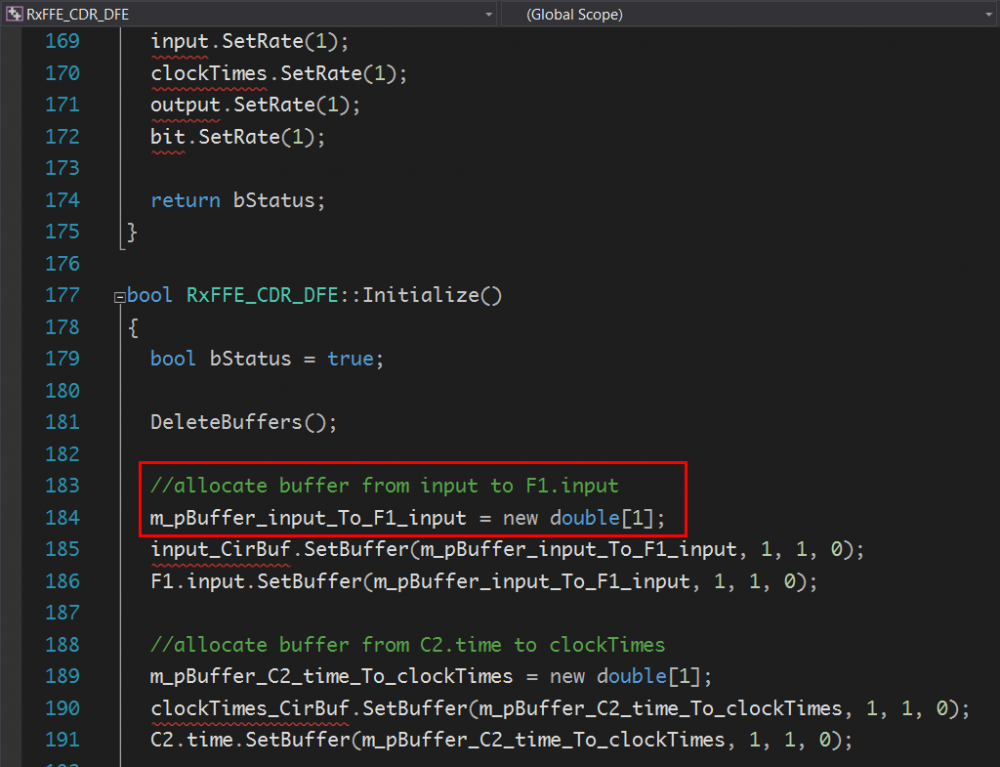
正因為這黑箱是.dll/so檔, 所以裡面如何編寫除了老闆外其它人都看不到, 所以一個沒什管的或求快不求好的建模者便很容易寫出”spaghetti” C/C++碼把什麼都混在一起而降低這黑箱的再次使用性;一個比較好的設計應是看起來如下模組化的:

如果我們同時以Spice .subckt的觀點來看, 它大概是長這樣:
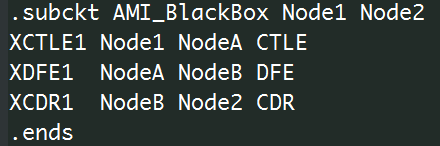
也就是說, 不同的CTLE, DFE, CDR等都已定義在其它的模塊中以供重覆使用;上述兩圖明顯地已將各模塊所需的參數略過不提,值得再說明的是即便是如上看起來很有機制的設計,也內含了幾個假設:1: 這個黑箱只有三個模組(即CTLE, DFE及CDR), 若是我要另加一AGC於前或DSP Filter於其中呢,難道又要重新編程編譯? 2:所有的模組是以cascade方式連成(這假設對SERDES設計來說大致上可成立),且每個模組都是一進一出(未必皆然, 有的有回控電路輸入), 所以看似精心設計過的AMI模可其實都還有改進的空間…因為這兩個假設都未必皆然且和設計有關,所以如果說我們的目的是要把.dll/.so檔的重覆使用性上做到最高, 這些假設都不應hard code到模型裡而應以外在.ami檔案的方在來進行組態(configure).
還有就是在建模過程中,一般的程序是先將實際電路或模組的行為模式(behavior)萃取出來到一個可以用C/C++語言來描述的地步才開始編程;比如說如果我們知道這是個濾波器,則先要拿到其頻率響應, 而後便可用傅利葉反轉到時域再和輸入信號做convolution;但有些時候一些模組的行為並不那麼能精確的描述, 或是其close-form的等式並不存在, 則是否我們可以把如.subckt裡的電路定義放到AMI .dll/.so裡呢, 這當然是可能的;比如說我們SPISim有內建的仿真器及IBIS, S-Parameter 等元件模型,自然就可以以一mini circuit simulator的樣式來做這一級的AMI模型;實務上,這種模組可用於Tx的輸出級或Rx的輸入端來模擬封裝模型的S-參數;而如我們所樣在其它貼文提到的SPISimProxy一樣, 這AMI的某一級其實可以外叫其它的程式或Script來達到特製化的目的。
從上面可以看到, 其實即便是對將會被編譯成二進碼的.dll/.so而言,其C/C++的設計也有很多密技可供使用;之所以如此做的目的,是因為所需編成.dll/.so的步驟煩瑣易錯, 所以我們相信更實用的方式應是盡量把富有完整功能的各模組模型都盡量編到這.dll/.so裡, 再透過外部的.ami來做呼叫使用;就好像把可手寫易編的本文netlist傳給不常變動的spice仿真器一樣。
.ami檔裡的黑箱密技:
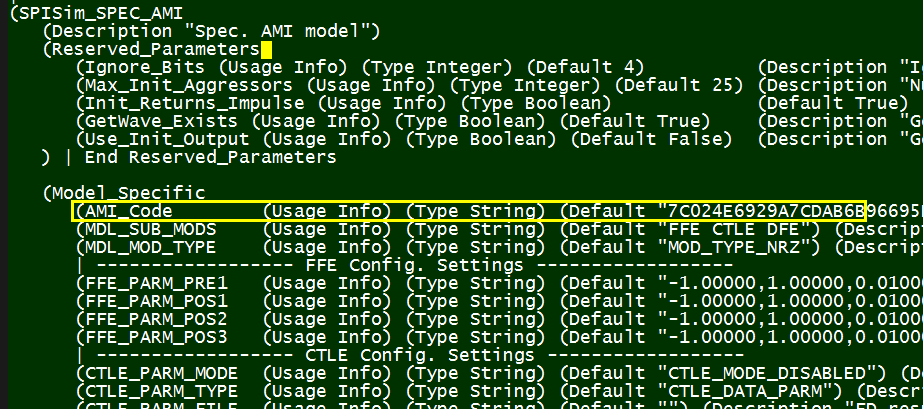
一個.ami檔案裡同時含有給channel simulator及(更重要的..)真實.dll/.so模型裡運作所需要的資訊, 如下所示:
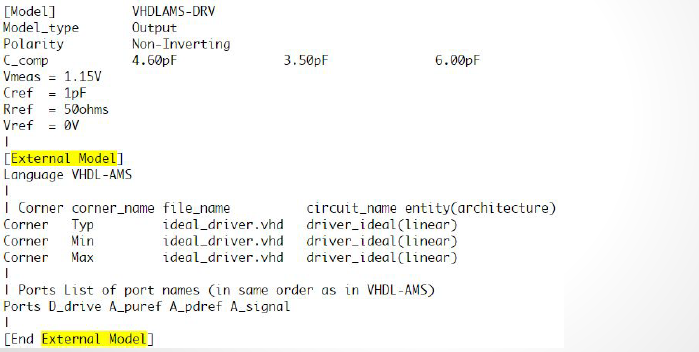
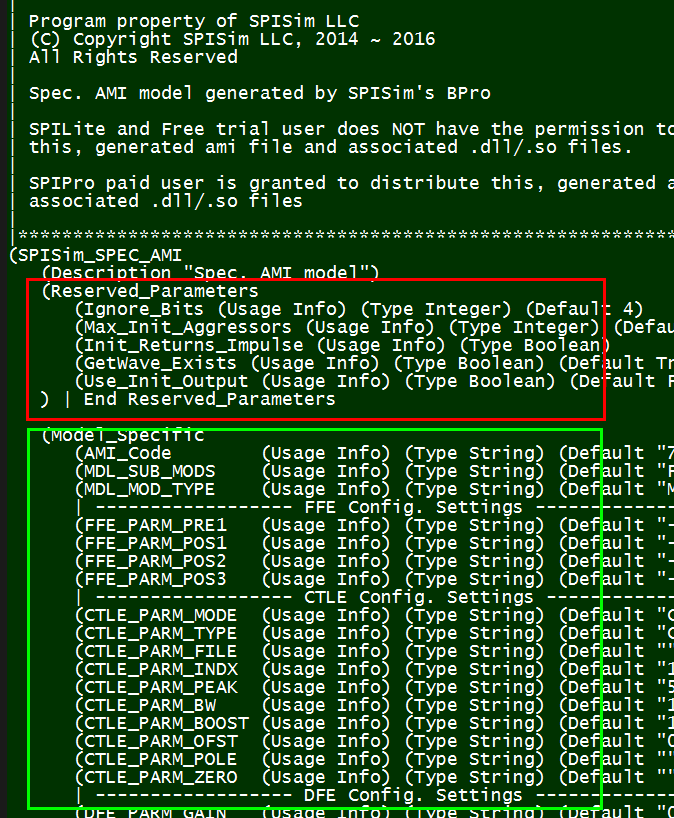
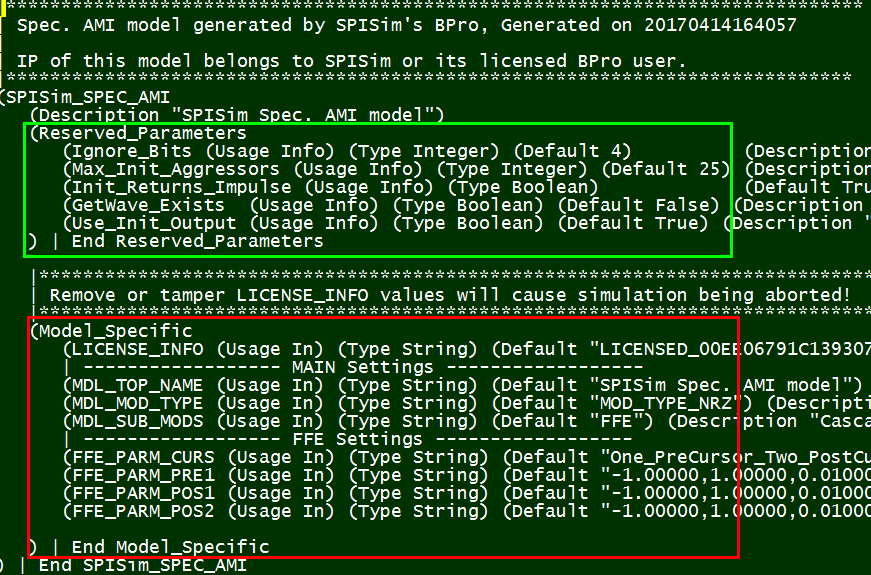 圖中, 綠色方塊裡的”Reserved_parameters”的部份是給channel simulator所用, 其所必需含的保留字(reserved keyword)都在IBIS Spec規格裡有詳細定義及規範,如此所有支援IBIS AMI規格的仿真器才能讀入這些設定且加以使用。在實務上, 因為之前所提及的市場寡佔, 我們的確看到過廠家自訂的保留字置於此處以支援其本身的仿真器。
圖中, 綠色方塊裡的”Reserved_parameters”的部份是給channel simulator所用, 其所必需含的保留字(reserved keyword)都在IBIS Spec規格裡有詳細定義及規範,如此所有支援IBIS AMI規格的仿真器才能讀入這些設定且加以使用。在實務上, 因為之前所提及的市場寡佔, 我們的確看到過廠家自訂的保留字置於此處以支援其本身的仿真器。
在另一方面,上圖中紅色方塊裡的”Model_Specific”部份則是只跟.dll/.so模型有關而與channel simulator無涉的;也就是說, 吾人建模者有很大的自由度可定義其名稱、數目及格式;也就是在這點自由度上, 我們可以發揮創造力來加入黑箱密技。
在.ami檔裡做文章的觀念我們在去年底的貼文裡有約略提及;很令人高興的意外是:在今年初的DesignCon的一篇文章裡,我們看到了IBM/GlobalFoundaries也做出了類似的運用, 所以多少可以說是英雄所見略同 :-), 此一文章的連結如下:
The AMI_Resolve: A Case Study for 56G PAM4 (http://ibis.org/summits/feb17/)
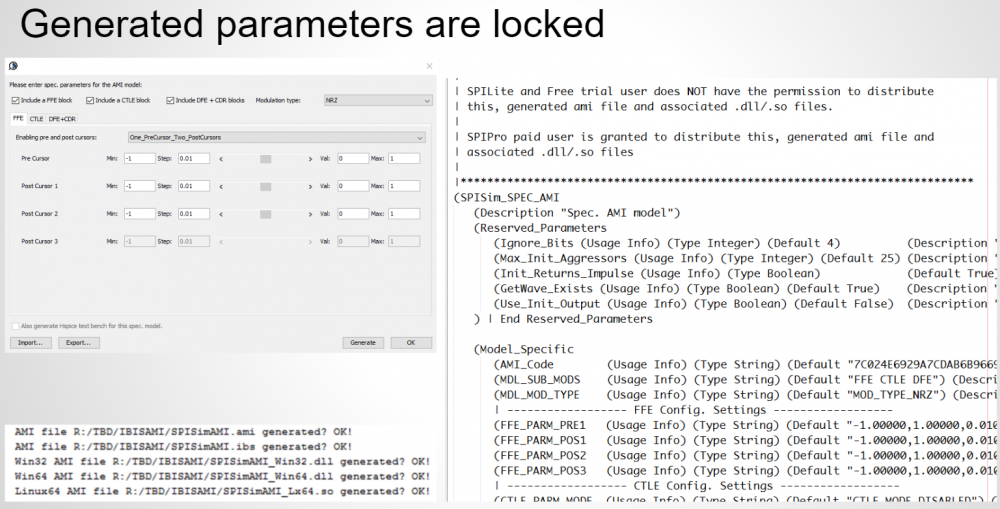
簡單地說, 我們可以把許多資訊放在.ami裡以傳給實際運作的.dll/so檔案,不同的加密技巧也可同時運用以保護相關的IP 或設計;就我們SPISim而言,我們之所以能把已開發的不同AMI模型以公開免費的方式釋出供大家無償使用正是因為所有產出的AMI模型都需要一個自動產生的license資訊,這一小段機碼雖是本文格式,但必需存在且也和機器上的日期甚至是所含的資料有所連結,所以一旦有所更動或破壞,就會造成.dll/.so檔運作的失敗而產生鎖碼、鎖失效日期或鎖值的功能。

上面所提到IBM的文章所展示的是透過.ami檔來和API裡AMI_Resolve函式來做呼叫的概念,其所欲解析(resolve)的網表或等式也是以加密後的格式傳送,回到.ami所支援的model_specific變數來看, 雖然其也同時定義了諸如table 等的樣式,但在實際運作上不是像如excel一樣地一目瞭然而有實際上有更改操作上的限制; 相較之下, 我們更喜歡(且於SPIPro裡採用的)是直外外連一個檔案:

這外連的檔案可以是如含不同pre-cursor/post-cursor設定的預設值、不同CTLE的頻率響應或其至是如S-參數或網表(netlist)等供之前所提mini-simulator 模組所用; 格式上也可以加密與否的方式進行;由這些討論來看, 這.ami檔雖是本文格式,但實也可富含密技以支援所叫的.dll/.so以達到減少重新編程或編譯的目的。
AMI模型實例研究:
上面所提的黑箱密技拿到實際運用上來檢視又是如何?以下我們看一下同由Altera所產生不同AMI模型的兩個案例: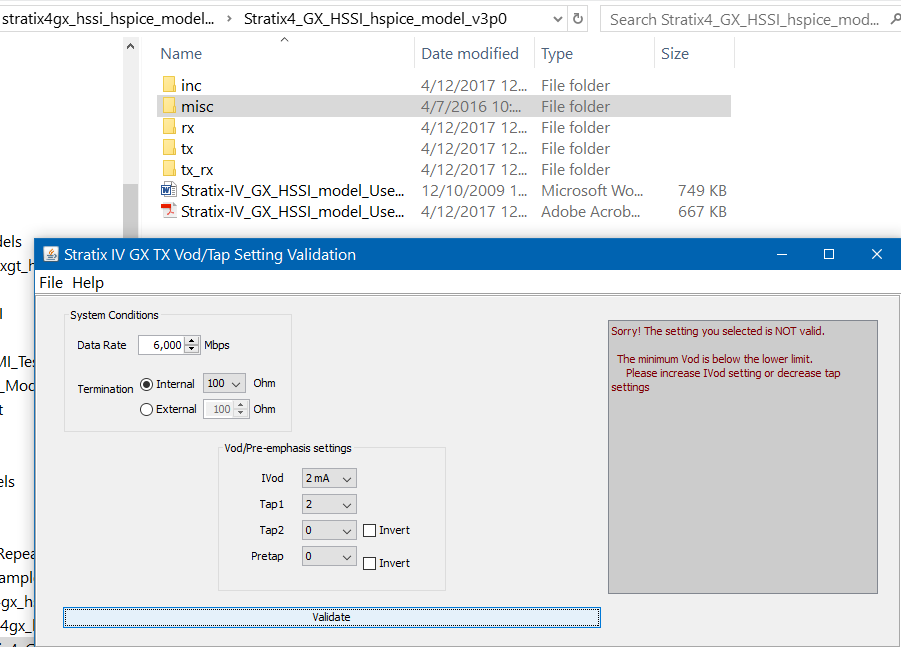
在這個例子裡, 它們不儘發佈了AMI模型,也同時提供了一個小GUI程式來檢測所用的參數組合是否有效;也就是說, 儘管只有一個.ami檔案,但裡面很多組合的值都有而用戶得自行參閱或事先檢查組合是否有效。
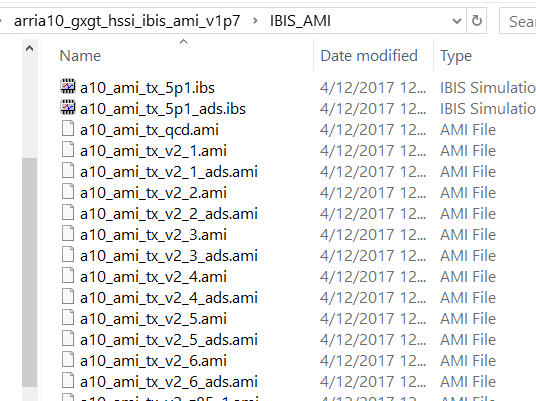
在Altera另一發佈的模型裡,我們看到不同的組態方式,這裡有許多預設的.ami檔案, 猜想用戶仍需先對所要用的設定查索引再來使用正確的.ami檔。
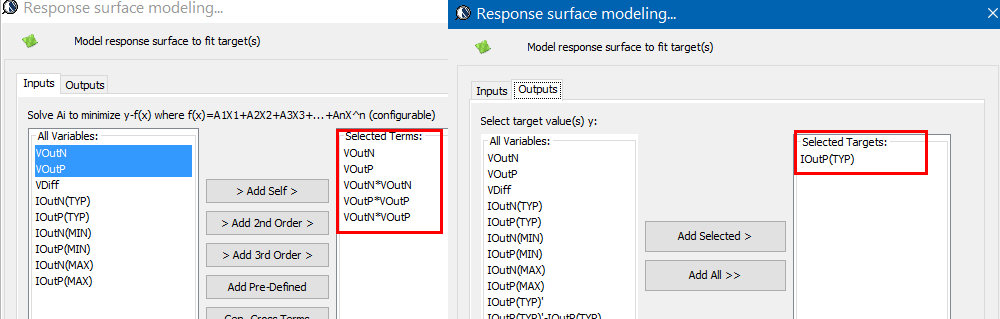
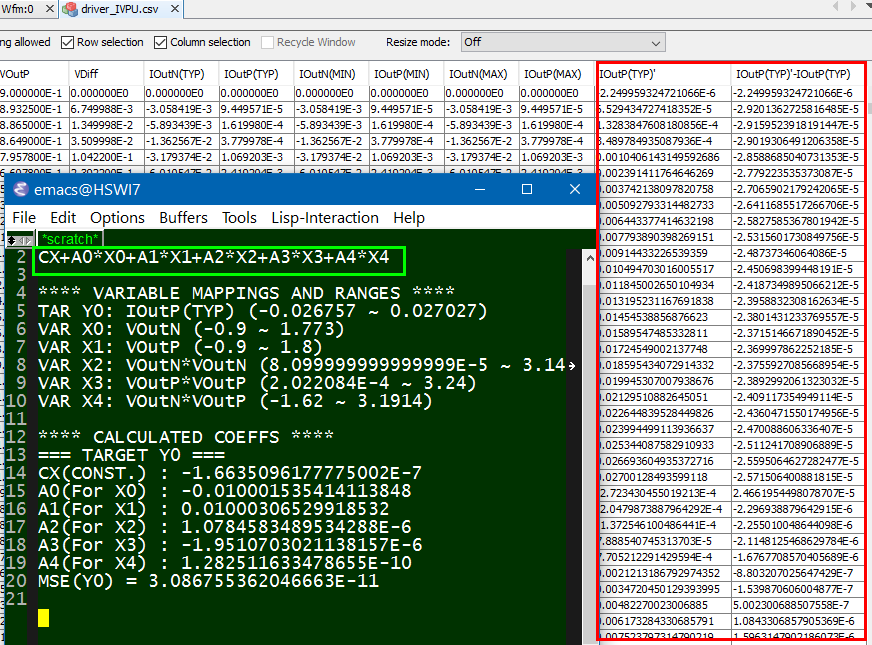
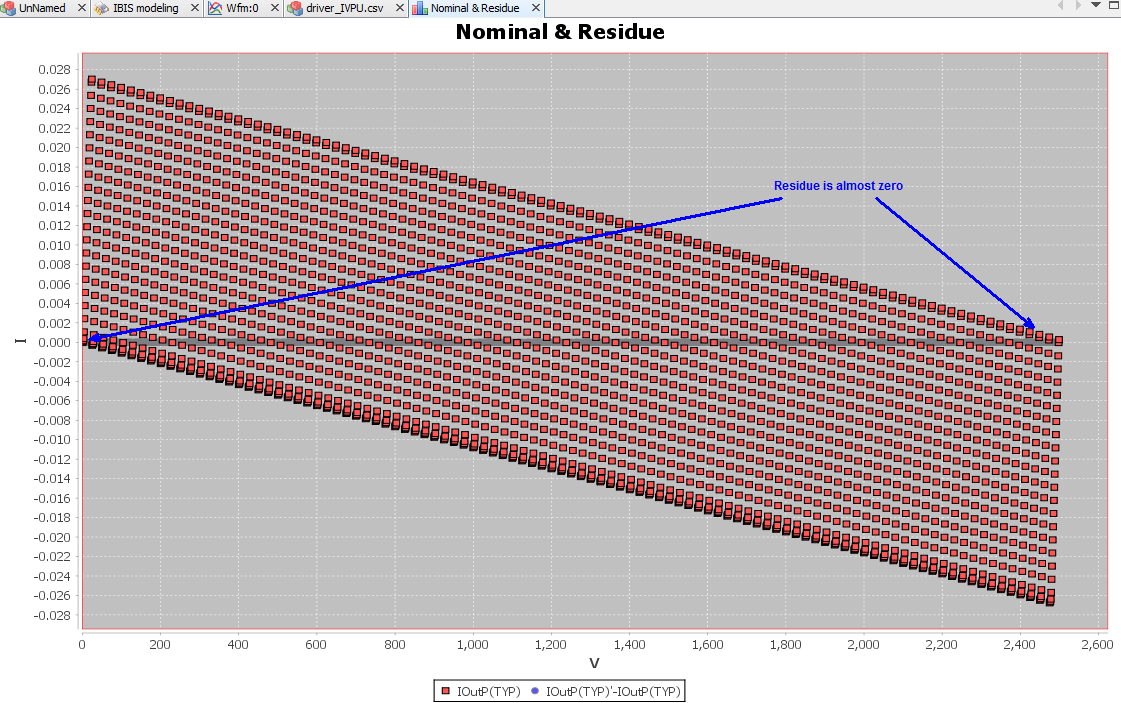
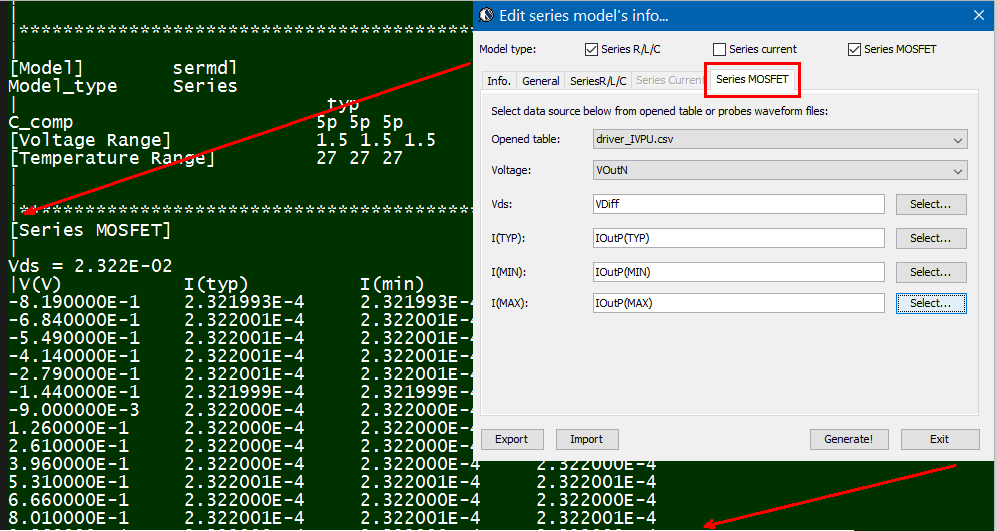
在我們SPISim的執行方式上, 我們允許用戶(建模者或使用者)以一csv的格式來建立可一覽無遺的檔案,每個欄位的表頭都是要提供給內建模組的參數名程,而每一行就代表一個可能的參數組何;對於使用者而言, 他/她只要變換所用的行數ID即可而不用一個一個去改變參數的值或corner.
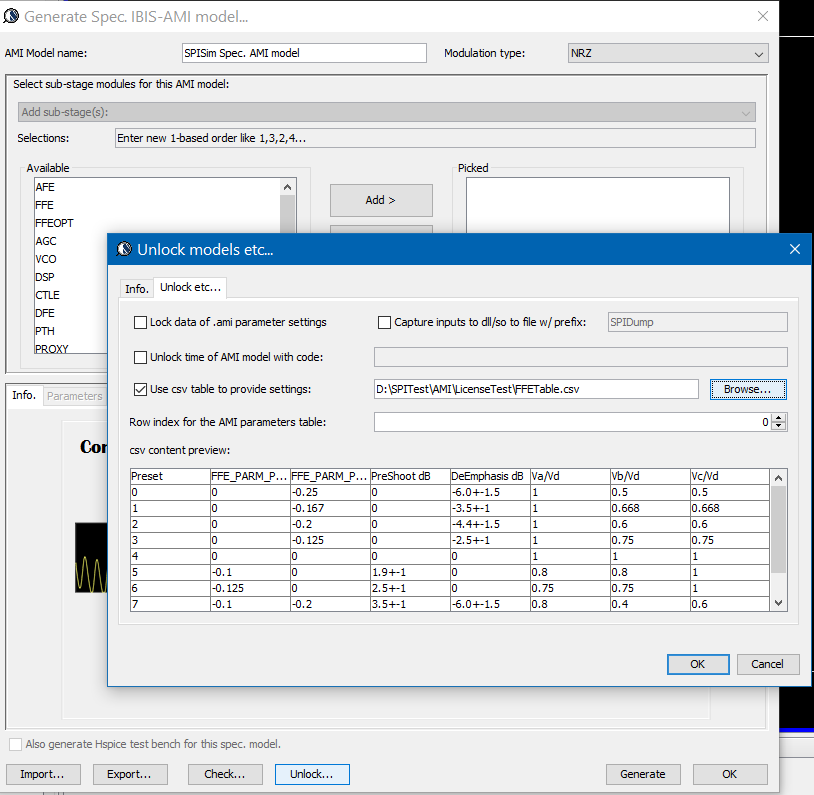
透過這種方式, 所要用到的表格可以加密與否的方式為之, 建模者可以提供同一份.dll/.so及同一份的.csv/.ens (encrypted csv)給不同的客戶,同時再針對不同客戶的不同需求給不同的row ID可能值即可; 就一.ami檔來看, 其內容是十分簡潔且只要一份即可… 不像要上面第二個Altera範例般要許多的.ami檔案。

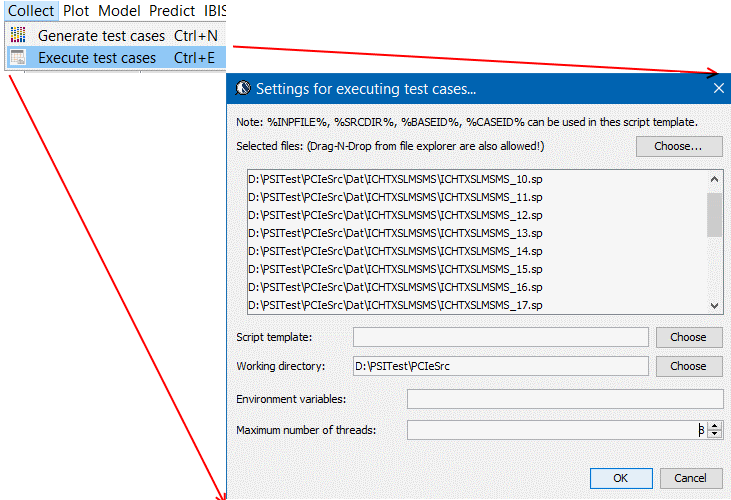
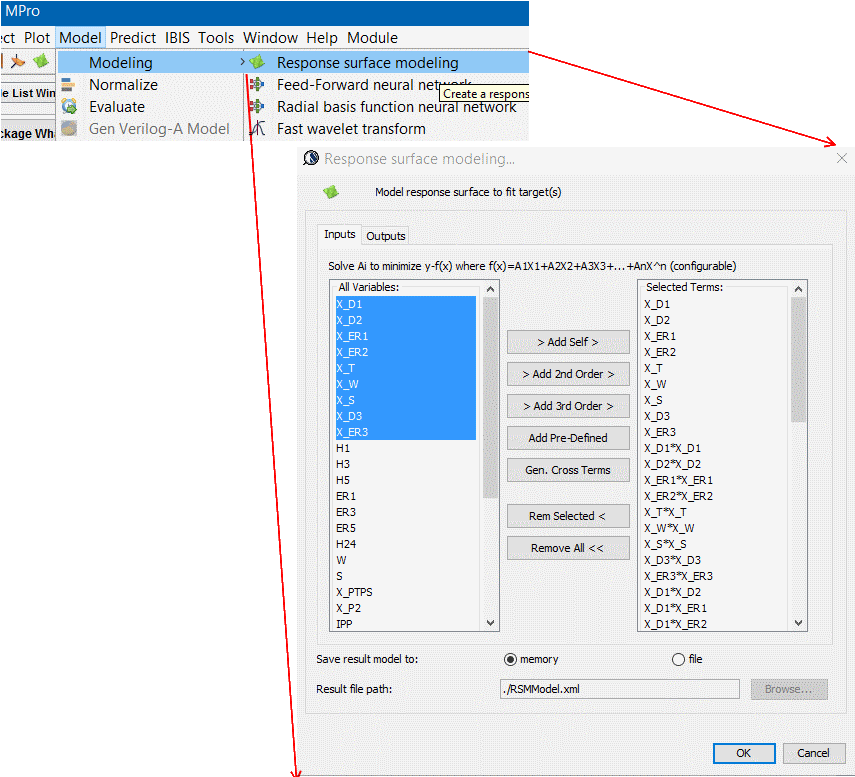
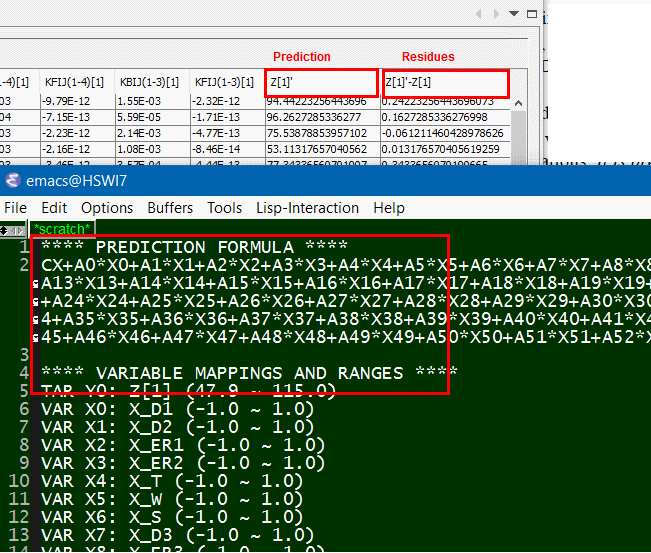
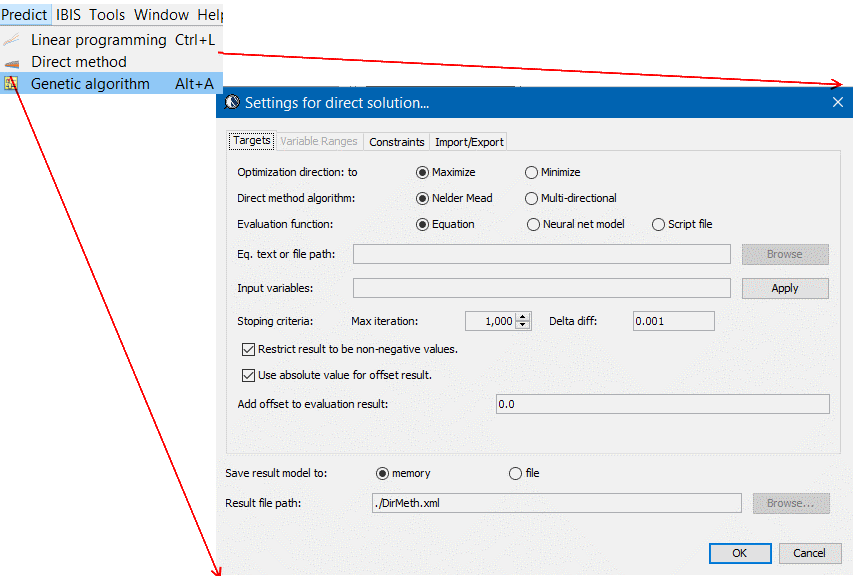
而我們所提供的解決方案, 實際上可說是先透過一GUI來做組態上的設定, 而後由GUI所屬的程式產生出含黑箱密技的.ami檔案, 而事先已在不同作業系統及位元編好且測試的黑箱.dll/.so也同時在一秒不到的時間內同時產生; 最後模型使用者只要更動很少的設定就可對不同組態的參數做掃描(sweep)或分析, 這可說是一個極為方便有效的流程。
AMI:測試後再使用
一個有點相關、但相當值得一提的是對所得到(或產出)的AMI模型的測試流程: 不同於以往的一個作業系統只有一個版本, IBIS最近最新版的Golden Checker已是特定於不同系統及位元;之所以如此做, 正是因為AMI的日漸流行且其相較於傳統IBIS的複雜性, 所以必需在不同系統上對.ibs檔做偵測。以下是我們覺得不論是建模者或使用者對一個AMI模型均應有的測試步驟:
- 第一步是用golden checker來測試模型相容度, 只要一個.ibs檔內含有Algorithmic部份,其所指向的.ami及.dll檔都會同時一併做測試, 唯這些測試儘止於API函式的存在與否及系統相容性, 而非功能上的運作測試。
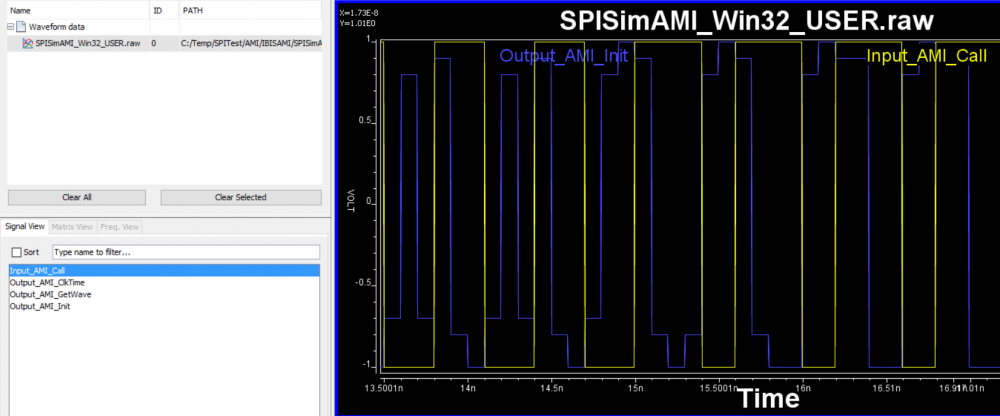
- 第二步則是用Model Driver來驅動所給的.ami 及.dll/.so;就好比通過golden checker的ibis模型仍需先放到test load來看波形合理與否一樣(而非直接丟到system simulator做channel simulation), 這一步驟可以偵測出許多運作上的問題及對設定參數的了解情形; 在HSpice及Ansys的程式裡,這驅動程式都叫做amicheck.exe且也都要相對應的license才能運作,我們SPISim提供了免費有效且功能更強的程式, SPISimAMI.exe,以供此用。
- 最後一步才是把.ibis, .ami及.dll/.so檔案到諸如HSpice, Cadence’s SystemSI 或是Mentor HyperLynx等的channel simulator裡運作, 這些工具程式能對如眼圖, BER及Bath tub Plot等的數據加以計算及產出,可以期待的是我們的SPICPro在今年(2017)稍後也會加如類似的功能。



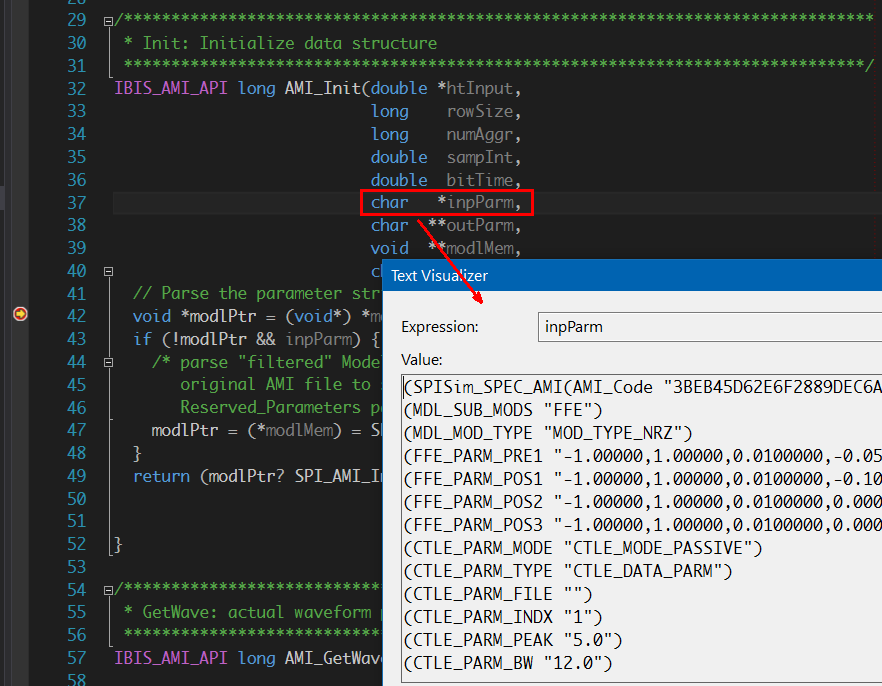
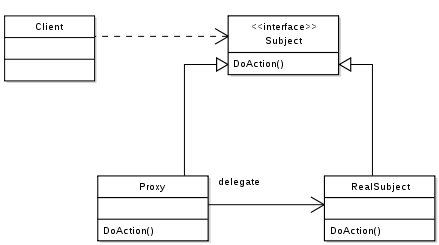
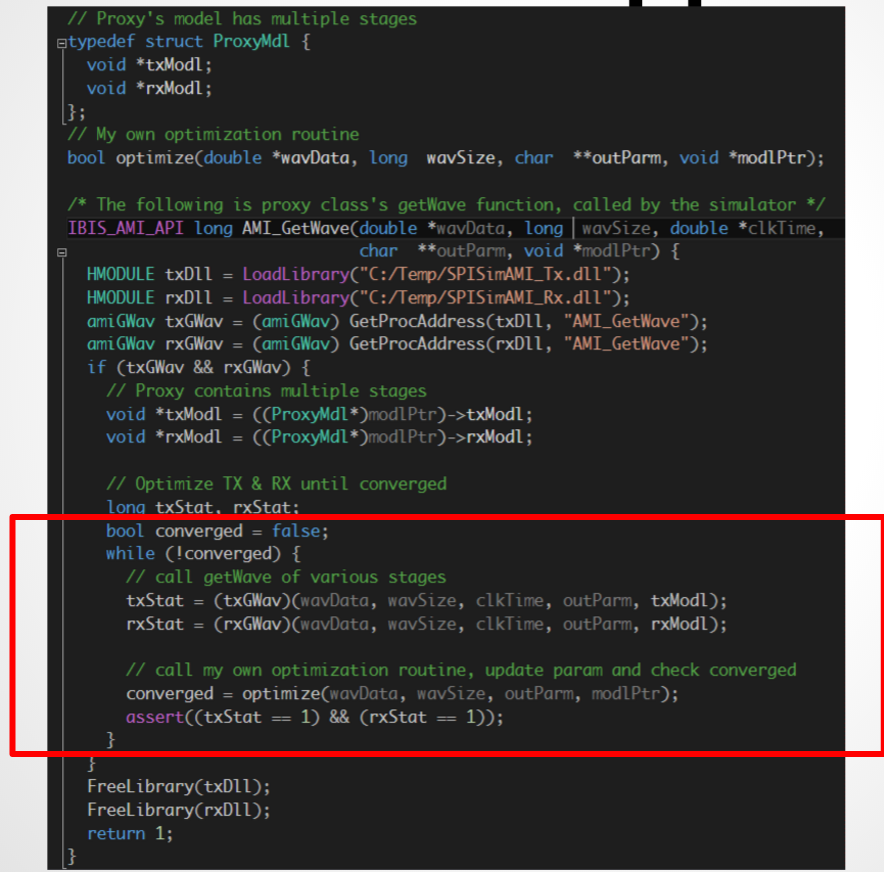
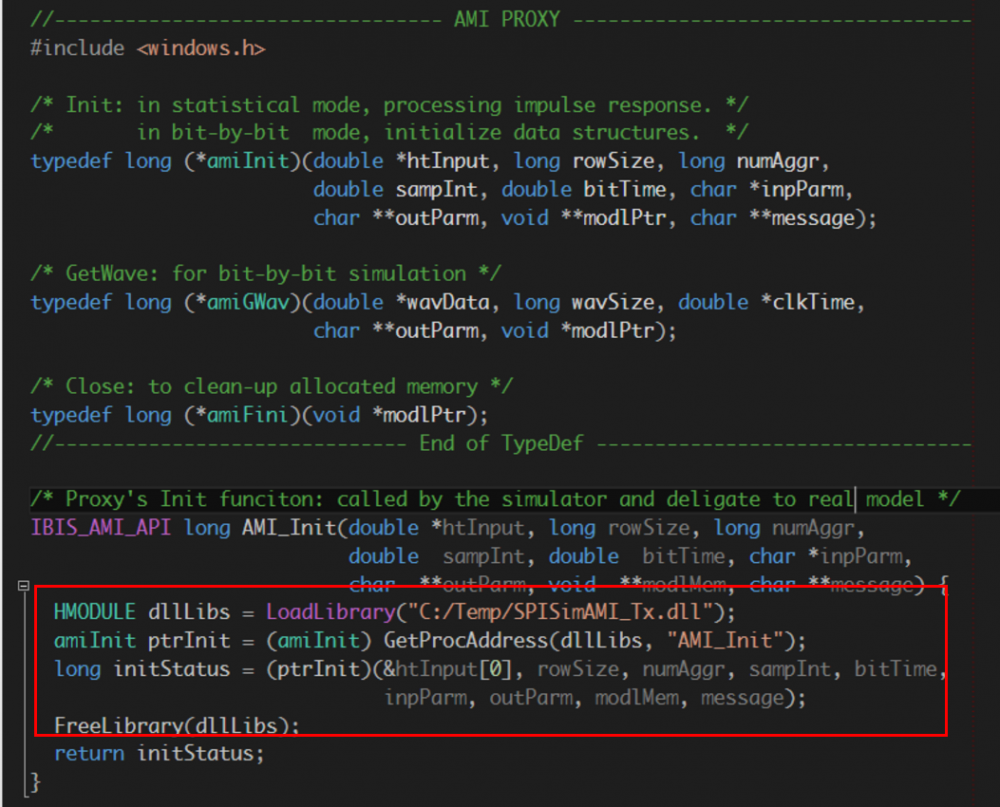 在上圖的源碼截圖中,可見到Proxy的AMI_Init函式做的是把真實模型的.dll/.so加載進來, 並轉而呼叫其內含的AMI_Init函式。
在上圖的源碼截圖中,可見到Proxy的AMI_Init函式做的是把真實模型的.dll/.so加載進來, 並轉而呼叫其內含的AMI_Init函式。