

在系統電氣性分析上,有效的方法及流程都必需建構在一定堅實的基礎之上,這“基礎科技”大致上包括了二維或三維場解器、仿真器及能依統計方法來演算出眼圖或BER的模組。針對仿真器而言,新思科技的HSpice可說是業界公認的標準,它功能強大又涵蓋了系統完整性分析上的各個面向;在北美及世界上的有些地區,我們可假設每個工程師都有HSpice可使用;但在許多其它地區。。比如說亞洲、或是當部門預算受限的情況之下,這假設就不成立了。為了能使我們使必信客戶在這種情形下也能享用我們所建構的分析流程,自去年下半年始我們開始了仿真器SSolver的研發。其初版本剛於日前釋出;為了分享一些背後的研發構想及基本仿真概念,我們將以以此篇為首的幾篇貼文饗有興趣的讀者。要說明的是我們的前提是以電氣信號為主之MNA仿真器,故不包含其它有關機械或熱能等的部份。
電路仿真器可說是一門電腦科學、數學及物理等知識相結合的一門藝術!
每個大二電機系學生都學過:兩個電路分析的基本形式是節點電流及網目電壓、分別以科希賀夫電流及電壓定律表之;而由這兩種形式都列出的方程式可以用矩陣的方式來表示。


當然,並非所有的電路元件均可以電壓或電流的形式表之, 比如說電流源的電壓準位即沒有定值。為了能將對每個節點電壓或分枝電流都能求解,將KCL/KVL合寫的MNA (Modified Nodal Analysis)便有其必要,其是以節點電壓法為主是因為就一電路而言,其節點電壓數目較網路來得少,故當以矩陣式來求解時,矩陣大小就小得多而能更快地求解。而暨然談到矩陣,則許多有關線性代數的技巧、諸如稀疏矩陣、conditioning、pivoting等等也都會被使用,而這也就是數學在仿真過程中所扮演不可或缺的角色;否則一旦矩陣循迴幾次求解不成,仿真便不能收歛了。對仿真器研發而言,常也是在這時候必需思考到若有矩陣元素造成不收歛,將如何連結至原始元件或是提供相對應的資訊給用戶以便能對網表(NetList)進行除錯。
實務上,要解一個矩陣一次很簡單。。幾行Matlab碼就可以了,但若要能以最有效率的方式在仿真電路過程中解幾千幾萬次,則又得多費思量了。所以即使是尚未談到元件物理特性的此時,沒有資訊科學上的考量也是行不通的。
電路分析有很多種形式:時域瞬態(TR)、時域靜態(DC)、頻域小信號(AC)、極零(Pole-Zero)等等。系統分析上,最常用的是時域瞬態分析,而其最基本的分析步驟是牛頓法求解,也就是利用矩陣在某個點的一階導數來對下一迴圈可能值來進行預測及再求解,直至矩陣的值解出為止。這個過程又分做兩個步驟:靜態解(DC)及之後每個時間點的瞬間解(t > 0);在解靜態值時,所有的元件已達靜態值:故電容器是開路而電感是閉路,且也沒有任何時變信號。而在瞬態求解的每一個牛頓迴圈裡,時間點是固定的而且端點電壓、支路電流也是固定的。。就好像解靜態值一樣,若求解不成功,則仿真器就在同一時間點內,依矩陣的一階導數來調整端點電壓值等以在下一個牛頓迴圈裡再進行求解。如此一時步一時步地完成時域仿真。在某些情況下DC求解不成功,則仿真器可更進一步地利用Ramp或Charge-up的流程,先假設所有的電壓電流源都是0且元件無初值(則每點電壓就當然也是0),而後漸漸地將有源元件”Ramp”至應有的最終值,通常經此一步驟,DC求解多能成功。
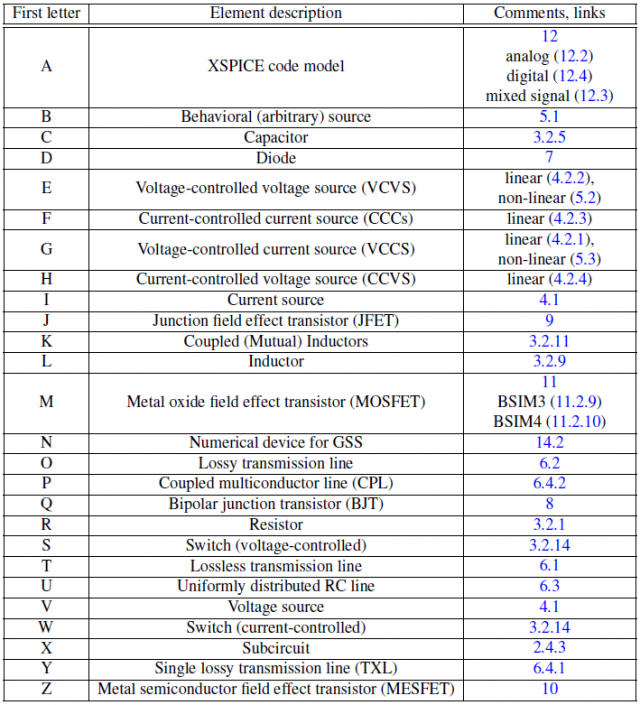
上面的圖是Berkeley Spice以元件字首的表列;之前談到仿真器難的地方在於要以最快的速度求解,則我們就不能不對所要支援的元件進行更進一步的分類,以便在仿真過程中減少函式呼叫(function call)的次數。比如說,我們可將上面所列的元件分為下面幾類:
- 不具時變性:如dc電壓或電流源,電阻等等,它們的值在仿真一開始之前就決定了而不會再有變化。
- 具時變性:
- 線性: 比如說PWL源,其值雖時變,但在同一時步的每個牛頓迴圈裡並不會再改變,所以同一時步只要求解一次即可;
- 非線性:如場效體或傳輸線等等,他們的值必需在每個時步的每個牛頓迴圈裡更新才能求得正解。
- 頻變或非頻變:
一旦分類完成,我們便可再進一步定出仿真器需支援的元件界面,以便能以最有效率的方式在每個牛頓迴圈裡由各個元件將先求元件內的解(Solve)再將那一瞬間的元件值填(Stamp,如蓋印章)到矩陣內以求解;這兩步驟(Solve & Stamp)可說是仿真過程裡被呼叫朂多次的程序(hot loop);一般來說,我們可為元件定出下面的界面:
- 讀網表資料:仿真之初,將網表資料讀入且做語法偵錯;
- 元件初始化:DC開始前將讀入的資料轉成仿真時會用的資料;
- 建物理模型:DC開始前(或也含TR開始前)初始化物理模型;
- 填入矩陣值:依每個牛頓迴圈內的解將元件資料填入矩陣裡;
- 解元件瞬值:在每個牛頓迴圈內依端點值求元件瞬間解;
- 輸出測量值:每個時步完成後輸出所量的元件值;
- 清內部資料:仿真完成後清除資料。
若是以物件導向性語言如C++等來設計,則上述的界面程序應是以虛擬函式來實作,若是以程序語言如C,則大概是以struct 的形式定出functional pointer而由實作的元件依在struct裡出現的順序來覆寫;在仿真器的上層,也應有一些串列來將網表內的所有元件來串連起來;故在仿真過程中,所有的電容器等都位在同一串列中而由仿真器引擎依序呼叫;如此一來,若是遇到非時變性元件的元件串列,則在那時步之初便可直接跳過;而時變性線性元件也只要在同一時步的第一個牛頓迴圈裡呼叫一次即可。
另外也要考慮到的是物理模型的儲存。舉例來說:一個晶片可能有數以千萬計的場效體,但之間有不同元件尺寸的可能不會太多,所以可以以數個不同物理模型供這些場效體來使用而不用每個元件有一個local copy;而每個元件對不同模型的取用也可能得用雜湊函數(hash map)來進行而非連結串列(linked-list), 以避免N^2迴圈情況的發生。
其它的考量至少也包括了時步進行的程序及再初始化:就前者而言,現今的仿真器很少是固定時步的,通常仿真器內會有Predictor來預測下一時步可以跳多遠解值也不會差太多,但一旦“跳太遠”時便必需倒車以較小時步來進行;所以在系統矩陣上簿計的程序也要具備才不會重覆求解;對再初始化而言,仿真器多有”.alter”類的語法以便只要稍改部份元件值便能再進行仿真;故在元件內部的設計上,不僅不需要的程序不用每次仿真(.alter)前都重做,就連算過的解也要能清楚乾淨而不要“污染”到下一次仿真的進行。
諸如以上種種,不難想見設計一仿真器所得先有的設計及想法,否則設計出來的軟體不是臭蟲多、不易除錯或維護、就是延伸性不強而不能輕易地加入新的元件。在另一方面,也正是因為這些必需要有的深刻思考而能讓工程師如我者能欣賞領略各個領域知識相互契合運作無誤而能有助我解決工程設計難題之美。
網上已有許多開源仿真器可供讀者參考,它們多是衍伸自Berkeley Spice而來,Berkeley Spice在我看來是個很完整、至少頗具教育性的仿真器架構。教科書方面我則推薦以下兩本經典供參考:
