Preface:
A hot topic in recent years about IBIS-AMI is co-optimization through back channel. During this process, either Tx, Rx or both participate to select optimized set of parameters in order to have best link performance. The IBIS spec. as of today does not support this type of communication or data exchange between models, thus new protocols have been proposed. In addition, there are also occasional needs to support 1. simulator or AMI models from other vendors, 2. implemented in different AMI-API spec version, or 3. written in different languages such as matalb. Most of these cases, only their binary formats rather than source codes are available. To overcome these obstacles and bridge the gap, a proxy class based approach is proposed.
This post is written in preparation for the presentation of the same topic at the IBIS Summit during DesignCon 2017 on Feb. 3rd. Audio recording of the presentation and slides have been made available at the bottom of the post.
Roles in an AMI flow:
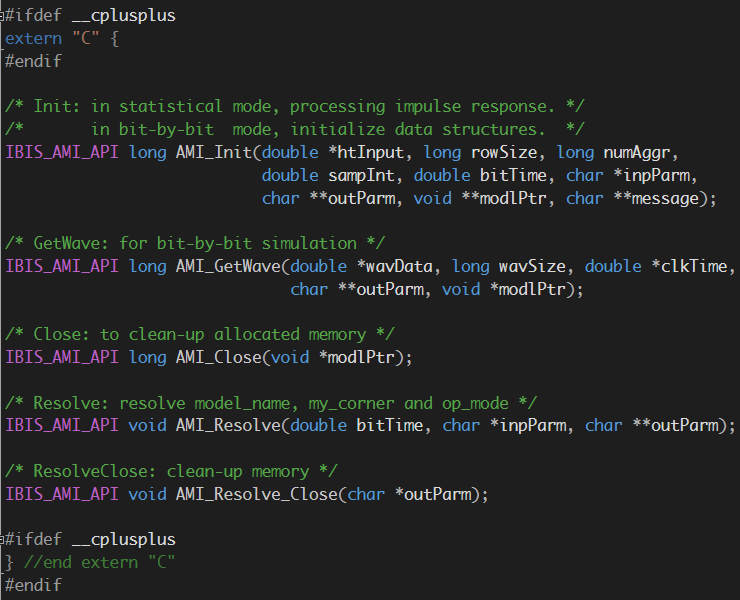
Readers of the latest IBIS spec. will find that Chapter 10, Algorithmic Modeling, is all about defining two roles in an AMI flow and how they communicate through API. These two roles are 1: EDA tool (usually circuit simulator) and 2: one or more AMI models being simulated. AMI API is defined such that EDA tool knows where the .ami file is and which functions are available in the model .dll and can be loaded. In the current spec., no interaction between different models is possible.
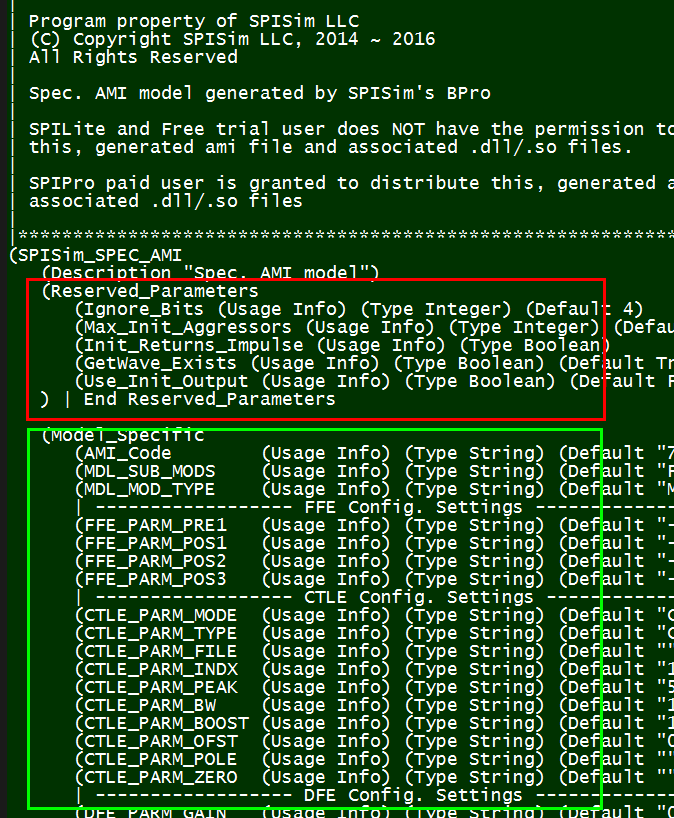
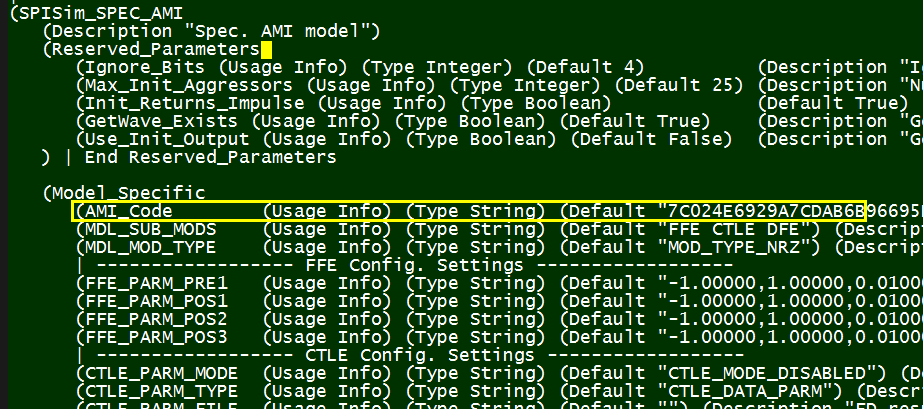
Take the .ami file above as an example, the EDA tool is responsible for parsing the ami file and do type and range check first. It then needs to figure out that an “AMI_GetWave” function implemented in the model since the parameter “GetWave_Exists” is set to true. In addition, the waveform process should happen in the AMI_GetWave” call rather than AMI_Init because “Use_Init_Output” is set to false. Beyond this, the only thing EDA tool needs to do regarding “Model_Specific” keyword section is to parse these data and form key-value pairs before passing into model. The simulator itself doe not need to know what they are and how they will be used.
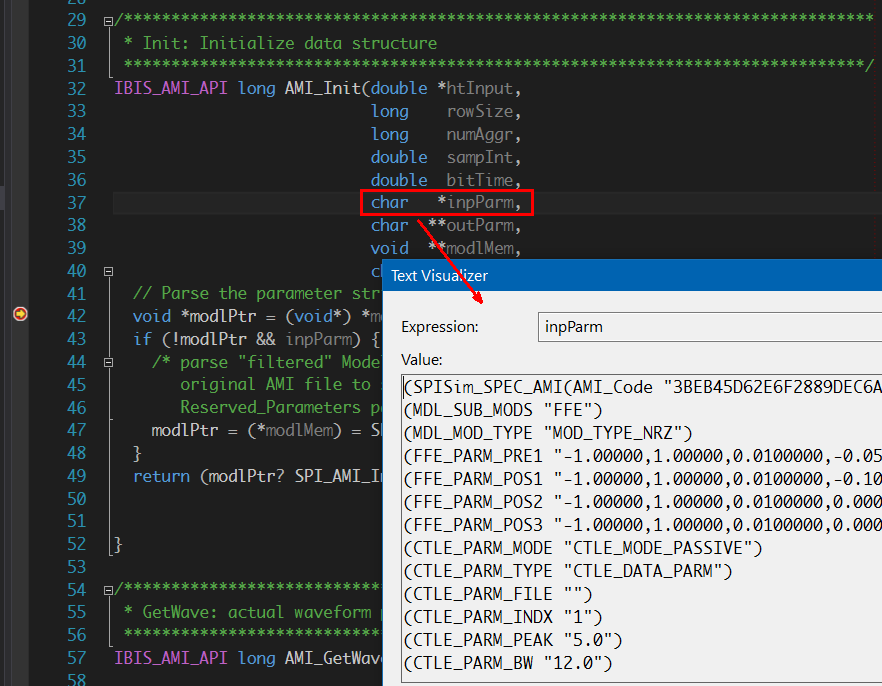
When a break point is set at the function call inside the model’s .dll/.so, one will find that the parameters now form pairs already and can now proceed to consume these settings. Note that this breakpoint will only be hit if the APIs are implemented correctly (thus can be recognized by the simulator and loaded according to the spec.)
With the introduction of the back-channel interface (BCI), new AMI APIs are being defined to support communications between models themselves:
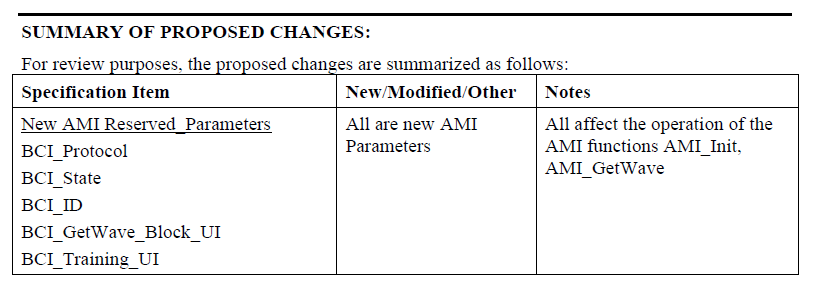
Interested reader can find BIRD147.,1_Draft on IBIS website fore more details. Simply speaking, models can pass data back and forth through this protocol via files. Since this is a reserved parameter, this BCI parameters should also be supported by the EDA tool.
Reader keeping track of this topic probably knows that for the past several years, several EDA companies have been arguing about how these back channel communications should be implemented. Some of the main considerations include:
- In case when legacy models can’t be re-compiled, how are they going to participate in the optimization process
- Whether or not a simulator should perform solution exploration actively or should leave this to the models themselves
- Should the communication protocol be only between models involved or it should also be part of the defined spec. as well
On top of these, we would also argue that:
- As a simulator/EDA tool developer, how can I test the AMI models at hand for co-optimization?
- As a model developer, my EDA tool may not be updated or up to date. How can I test the co-optimization if I want to add such support my model?
- As a model/EDA tool user, can I inspect what’s going on between simulator and models? I only get post-processed results from EDA tool and they are not correct!
For these purposes, we think that a proxy based class can be used in AMI analysis flow.
A proxy class:
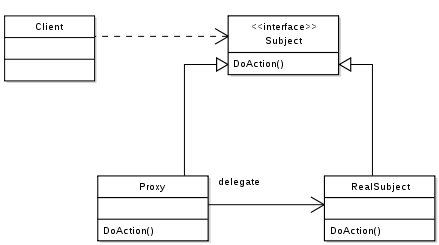
The proxy pattern’s UML is shown above. The dot line at the top represents “has a” relationship while the solid vertical arrow line represents “is a” relationship. This UML diagram can be read as: A client has one or more subjects which implement interface function called “DoAction”. When the proxy class’s DoAction is called, it delegate to RealSubject’s DoAaction” function.
Put this in the IBIS-AMI’s context, the statement above can be read as: An EDA tool can load one or more .dll(s)/.so(s) which implement AMI-API’s interface such as AMI_GetWave etc. When the EDA tool calls a proxy’s AMI-APIs, this proxy object delegates calls to RealSubject (i.e. real model)’s AMI-APIs for data processing.
So this Proxy class is a “wrapper” around real model. It’s loaded by the EDA tool yet itself also load the real model’s .dll(s)/.so(s). It’s a “man in the middle” and can be used to intercept, modify input/output data or even perform customized analysis flow beyond what a simulator can do.
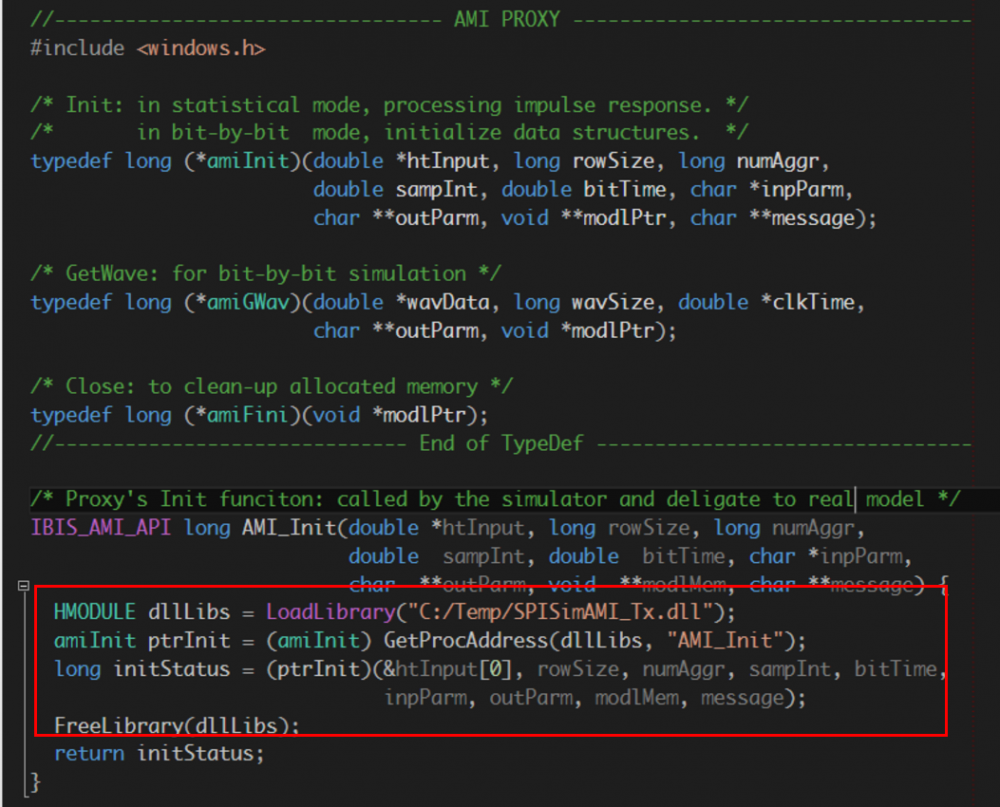
In the example above, the proxy’s AMI_Init function loads the model’s dll, identifies the AMI_Init function and then delegates call.
With proxy class, there are several experiments/test can be done:
Consistency/Stress test:
In this example, a model’s functions are called many times. The purpose is to test:
- Consistency: i.e. when given the same data, will the model return the same result? This should be the case for LTI model.
- Stress: will there be resource leak such as memory usage keep increasing?
As mentioned in the IBIS spec, an EDA tool may break up lengthy bit stream into several chunks and call AMI_GetWave many times, thus a well behaved model should pass these two tests.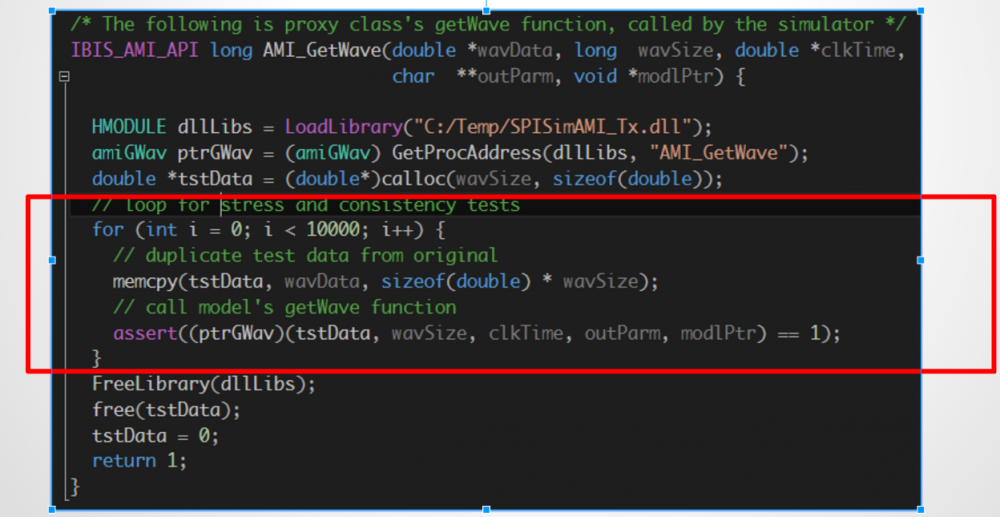
Co-optimization (internal):
The second experiment is to bundle Tx and Rx’s response together within one function call and try to do something with it (such as iterate to find combinations for best performance, i.e. optimization)
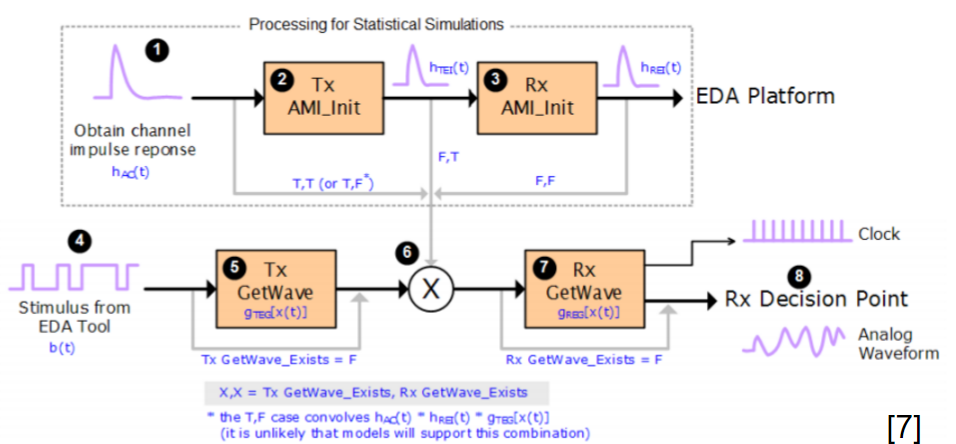
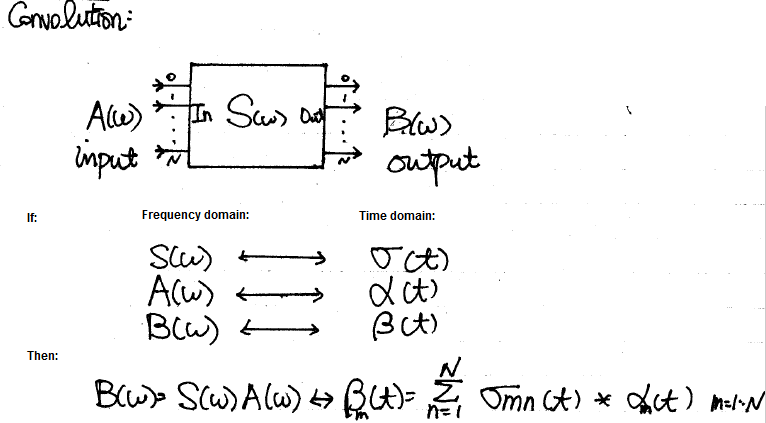
First, from the IBIS spec., or diagram shown above, Tx’s response will be computed first. Most of the Tx’s processing is LTI and its function is mainly to convolve signals with 1 or 4. After this step, EDA tools convolves again with signal 6 before passing on to 7.
Now convolutions is a commutative process, meaning the order can be exchanged:
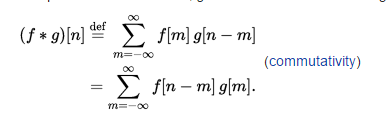
So if we use a proxy class in Tx’s place and implement a delta response (e.g. simply return the data passed in), then EDA tool will convolve step 4 and 6 as before while we can combine the actual Tx model’s function with Rx together after that and get the same result:
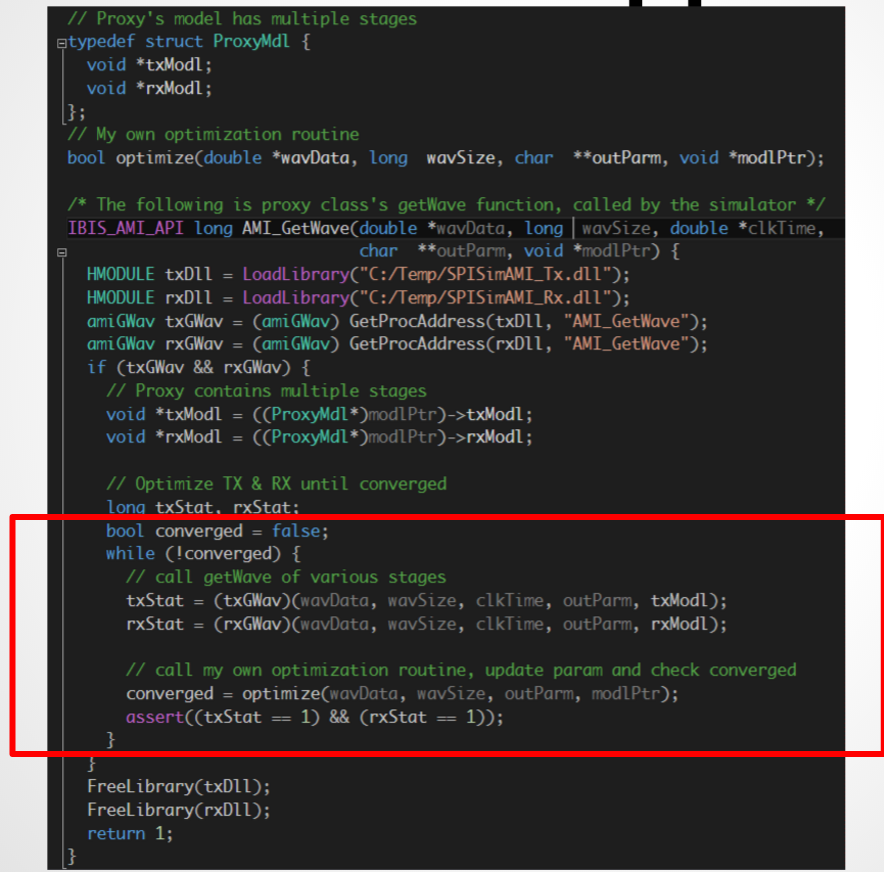
However, these two models are now put together with the Rx proxy’s AMI_GetWave function call. So we have great control by manipulating the models’ pointers directly. This way, setting such as CTLE’s curve index and/or sweep the number of taps and their weights on the Tx side can be performed. This example also demonstrates how a proxy class can intercept call from EDA tool and perform customized flow.
Co-optimization (external):
In the two examples above, data execution is within the same process where the proxy and/or model’s .dll(s)/.so(s) are loaded. However, it’s also possible to implement these in separated process, or on different machine over the network. The diagram below shows an example:
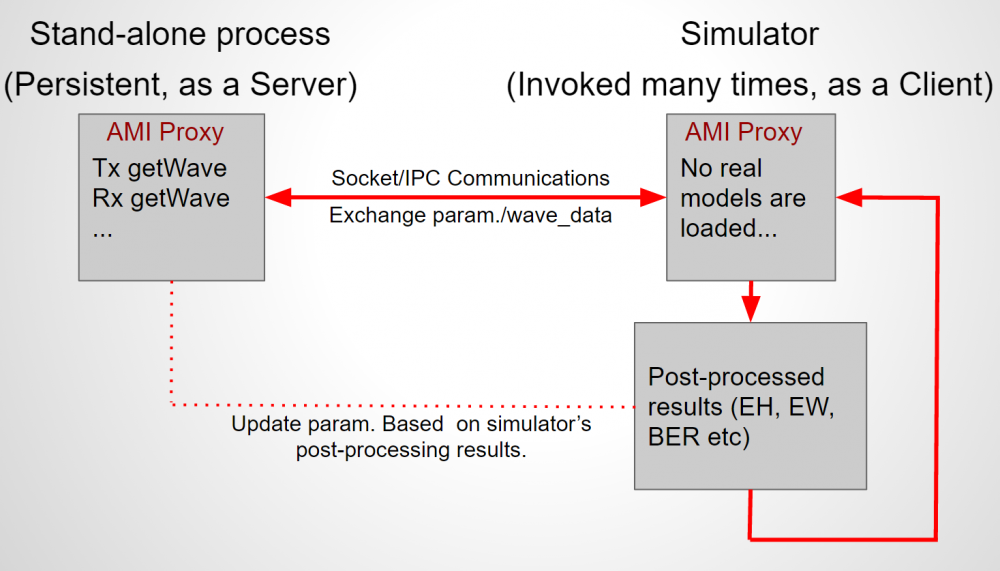
In this case, we want to use EDA tool’s post-processing capability to obtain performance matrices such as eye-width or BER. However, we would also like to adjust the model’s parameters continuously in order to obtain best channel performance. The EDA tool can be called repeatedly, each time the AMI_Init or AMI_GetWave is called by the simulator, a proxy class intercepts and delegates the call to a remote process via communication such as file based IO, socket or shared memory. The remote process is persistent and can be considered as a server. It will return the data back to proxy class upon completing processing, wait until EDA tool’s post-process and updates results, then read and adjust the settings for next call from another simulator run. On the “server” side, a simple AMI test driver loading similar proxy class can serve as the stand-alone, persistent process. This way all the .ami processing can be done up front by the model driver and no simulator license is needed.

The shaded block in the middle execute socket communication to get response from a remote process.
Other possible uses of the proxy class:
In addition to the examples discussed above, an AMI proxy class may also serve:
- As a wrapper class to support model implemented in different language, such as matlab, octave, perl etc in either AMI-API compatible library form or executable
- As a server to centrally manage the SERDES models, provide extra IP protection as it can now sit on some server always updated without being distributed.
- As a wrapper to support legacy models by implementing support of new spec. or parameters at the proxy level without re-compiling the old models.
We have used such proxy class in our AMI analysis and find it very useful. We also expect it will be even more widely used as AMI models become prevalent and IBIS spec. being updated to support new protocol/parameters.
Materials:
Click [HERE] for the audio recording of the presentation.
Click [HERE] or visit ibis.org for the pdf of the presentation.
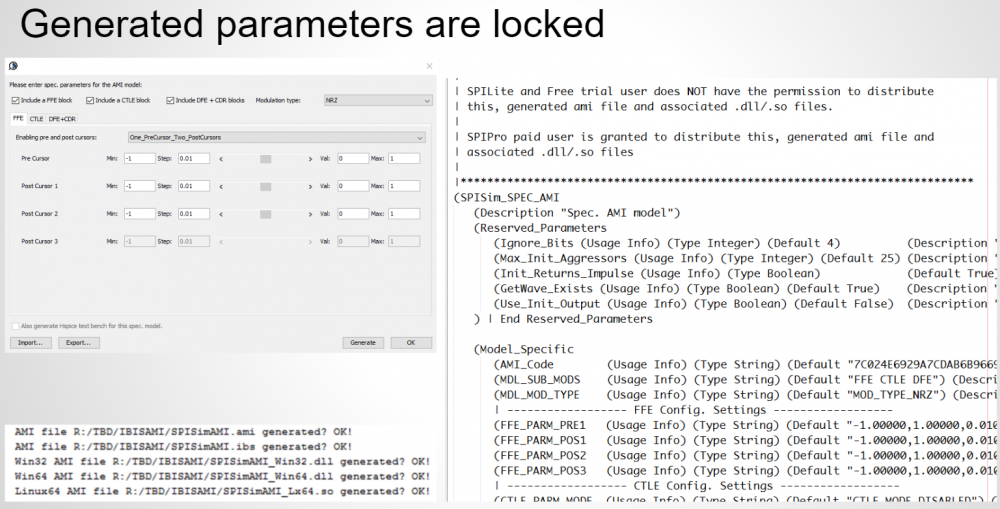


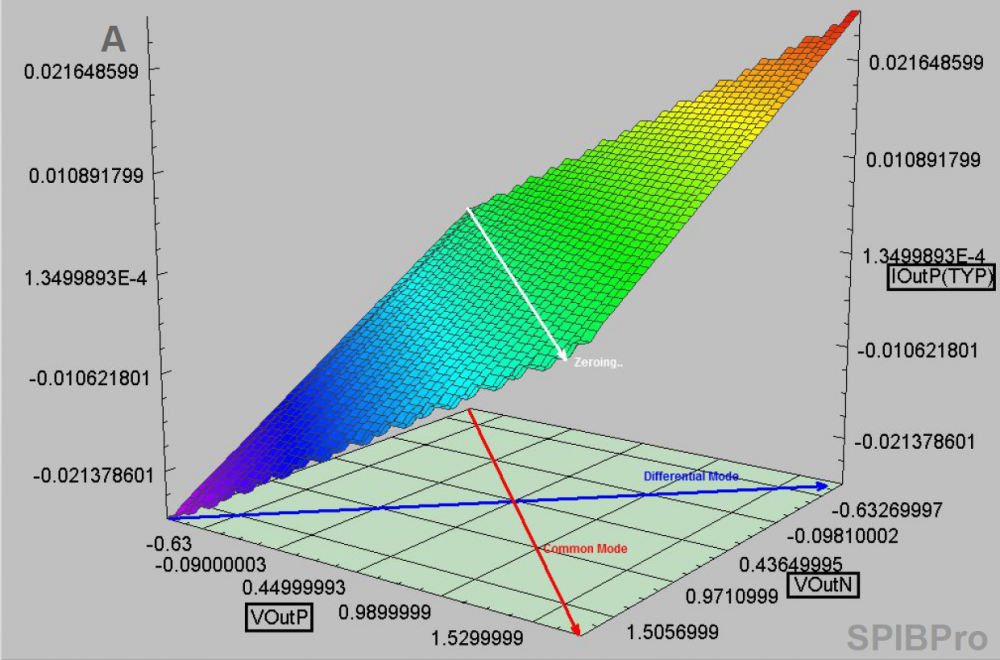
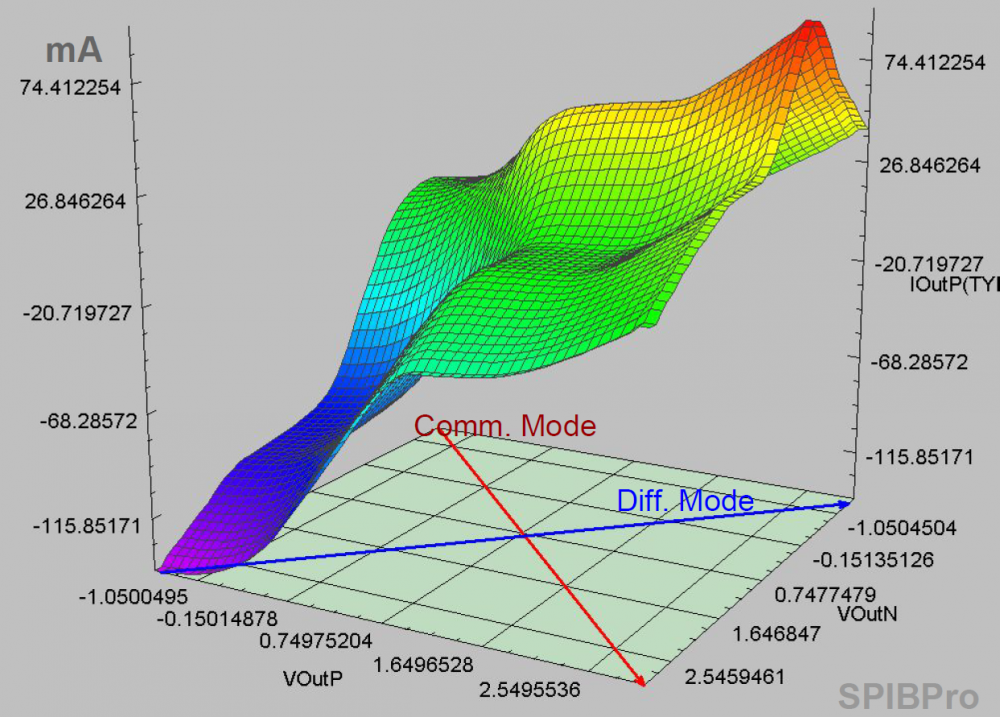
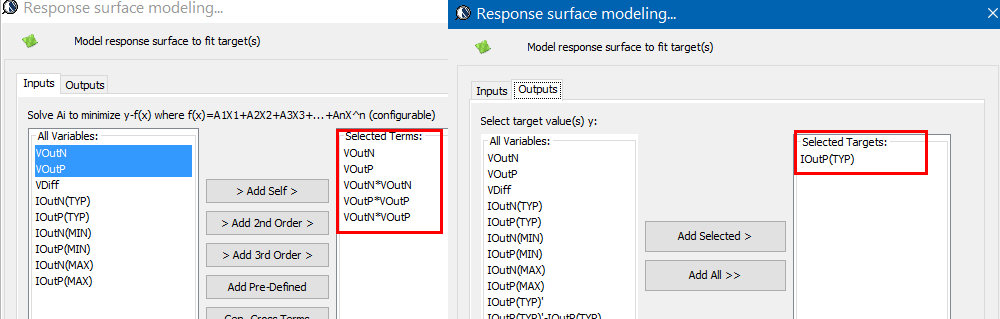
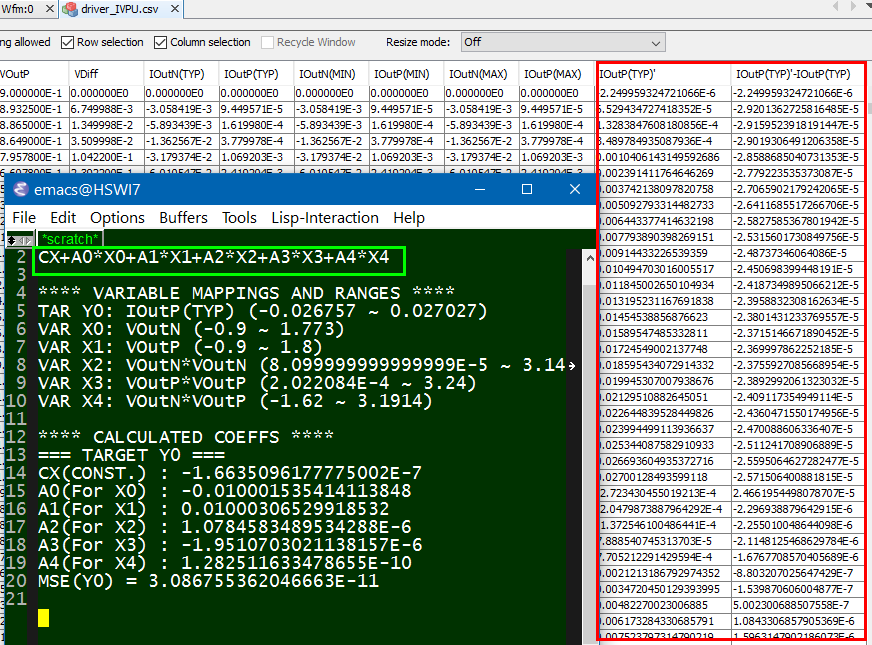
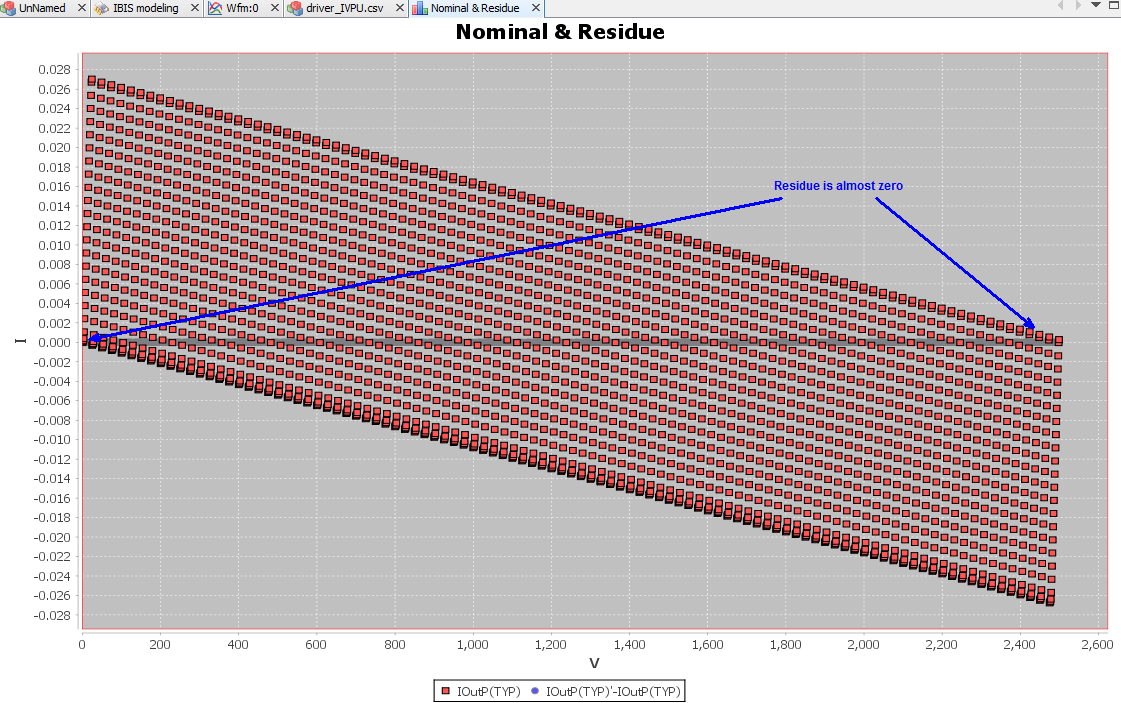
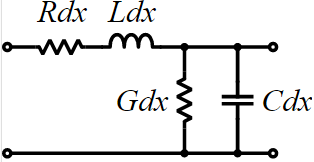
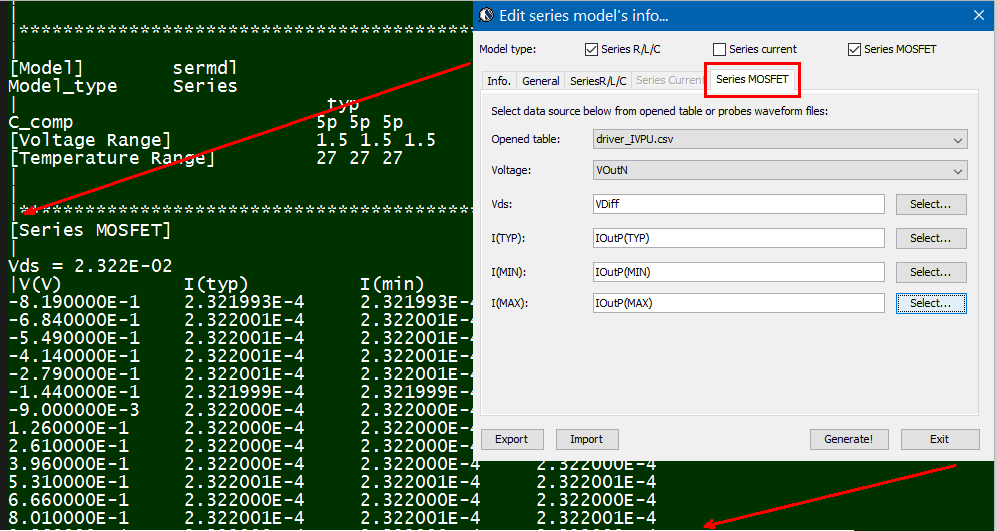 The same table content is sufficient to construct a series element. The steps needed here is to translate data into a IBIS compatible format. Such process is trivial when the model is simply R/L/C. For series current and series MOSFET (can have up to 100 tables of different bias condition), the attention needed to perform such work manually is not economical and a tool/flow should be used instead.
The same table content is sufficient to construct a series element. The steps needed here is to translate data into a IBIS compatible format. Such process is trivial when the model is simply R/L/C. For series current and series MOSFET (can have up to 100 tables of different bias condition), the attention needed to perform such work manually is not economical and a tool/flow should be used instead.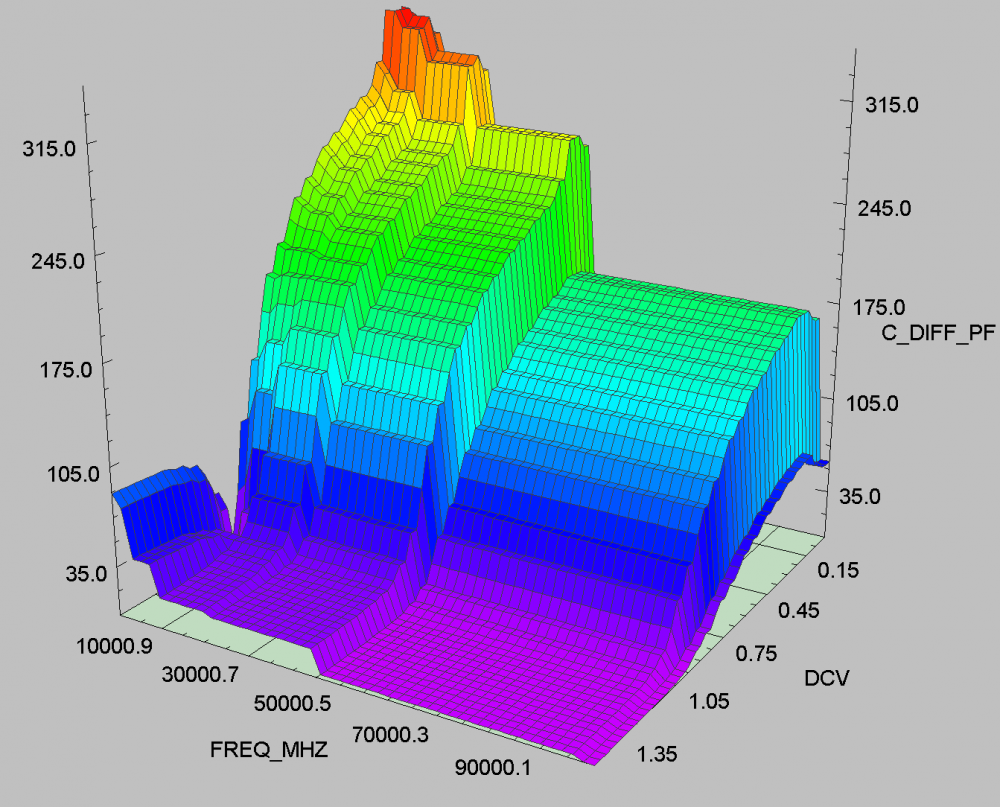
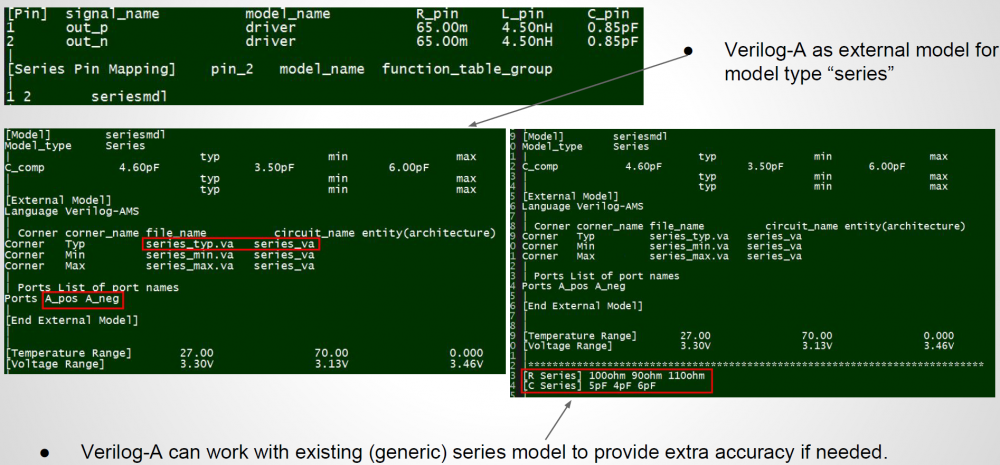

 Take the picture shown above as an example. Under the “Series Pin Mapping” keyword, a model named “R_SERIES_100” is declared to connect pin 1 to and 2. Another instance of such model also sit between pin 3 and 4. Pin 1~4 each has its own model defined in other part of the ibis file already. For example, pin 1, 2 may have an output buffer connected while pin 3, 4 have open-drain buffers. This R_SERIES_100 model must have type “Series” defined as part of the IBIS file. Since “Series” is one of predefined IBIS model type, its contents (keywords) are not free form and must be one or more of the following series elements: R, L, C, Series current and Series MOSFET which contains up to 100 I/V tables under different biasing voltages.
Take the picture shown above as an example. Under the “Series Pin Mapping” keyword, a model named “R_SERIES_100” is declared to connect pin 1 to and 2. Another instance of such model also sit between pin 3 and 4. Pin 1~4 each has its own model defined in other part of the ibis file already. For example, pin 1, 2 may have an output buffer connected while pin 3, 4 have open-drain buffers. This R_SERIES_100 model must have type “Series” defined as part of the IBIS file. Since “Series” is one of predefined IBIS model type, its contents (keywords) are not free form and must be one or more of the following series elements: R, L, C, Series current and Series MOSFET which contains up to 100 I/V tables under different biasing voltages.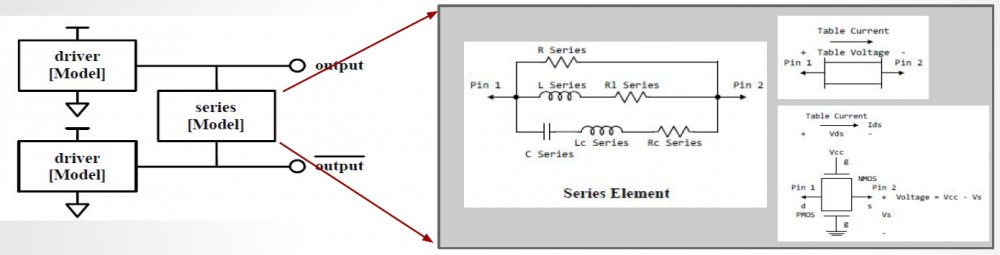
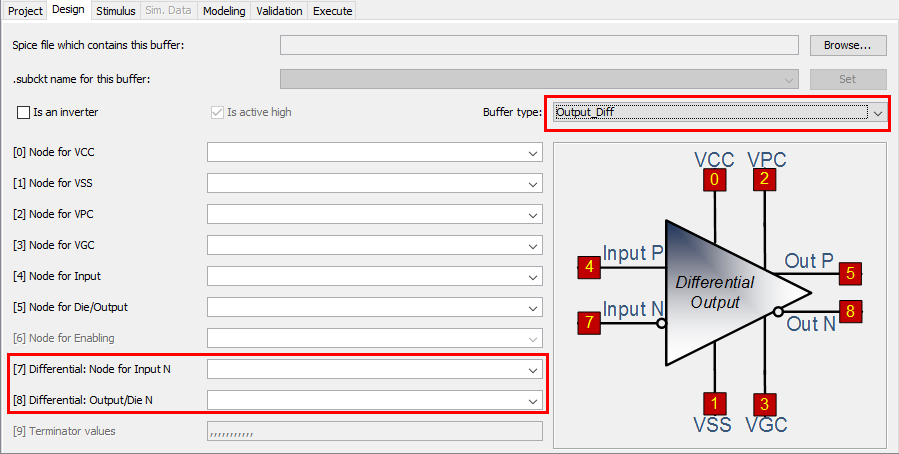
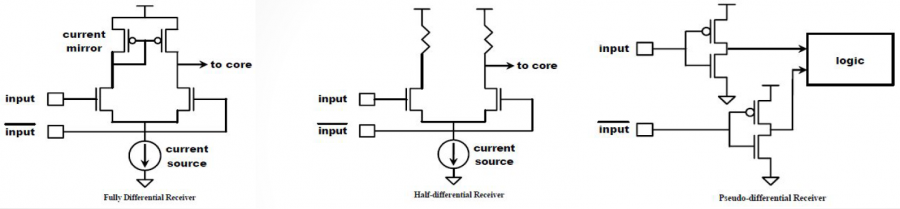
 These differential model types must be implemented with language such as Spice, VHDL-AMS, Verlog-AMS, IBIS Interconnect Spice Sub-circuits (IBIS ISS) and declared with the “External” model section. These languages provides much more flexibility in terms of modeling capabilities, yet they also diminish the portability of the generated IBIS model.
These differential model types must be implemented with language such as Spice, VHDL-AMS, Verlog-AMS, IBIS Interconnect Spice Sub-circuits (IBIS ISS) and declared with the “External” model section. These languages provides much more flexibility in terms of modeling capabilities, yet they also diminish the portability of the generated IBIS model.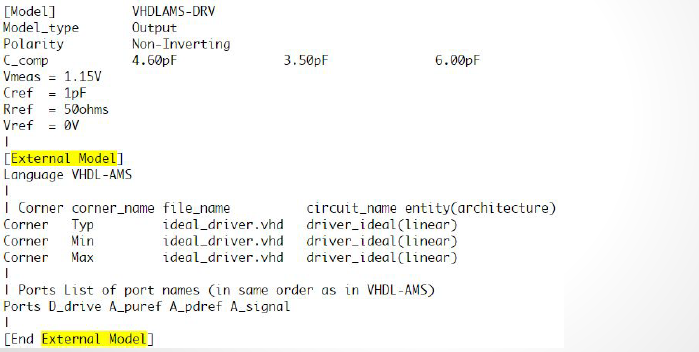 In the example above, a separate file “ideal_driver.vhd” must be provided outside the IBIS file and an “entity” of name “driver_ideal” needs to be defined. The port connections is described using reserved keywords after the “Ports” statement. In the IBIS Spec, all possible ports are pre-defined and the declaring order here must match their definitions in the associated Verilog/VHDL etc file.
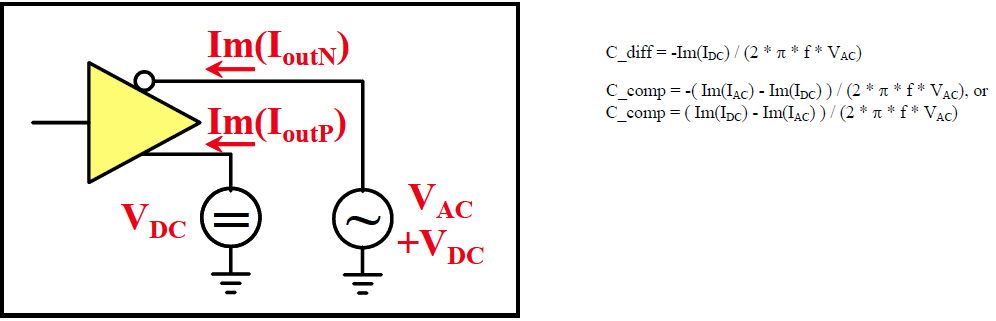
In the example above, a separate file “ideal_driver.vhd” must be provided outside the IBIS file and an “entity” of name “driver_ideal” needs to be defined. The port connections is described using reserved keywords after the “Ports” statement. In the IBIS Spec, all possible ports are pre-defined and the declaring order here must match their definitions in the associated Verilog/VHDL etc file.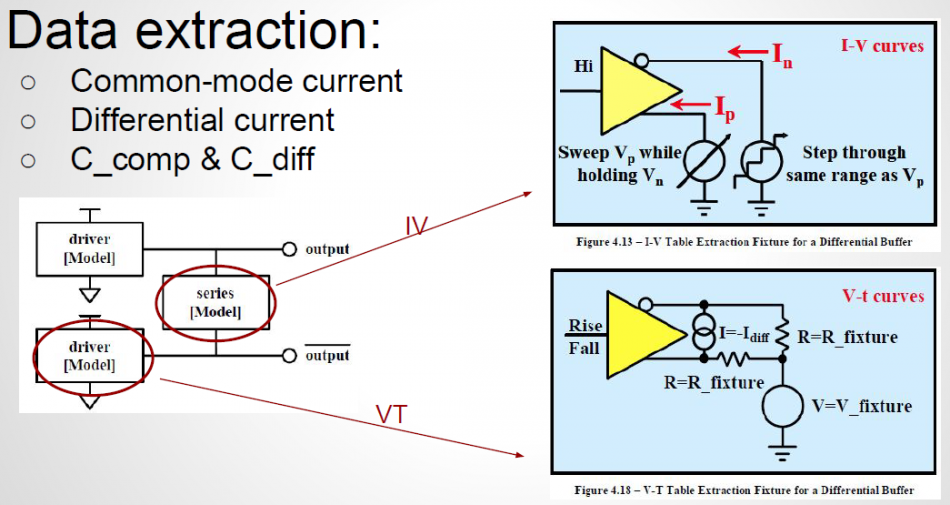
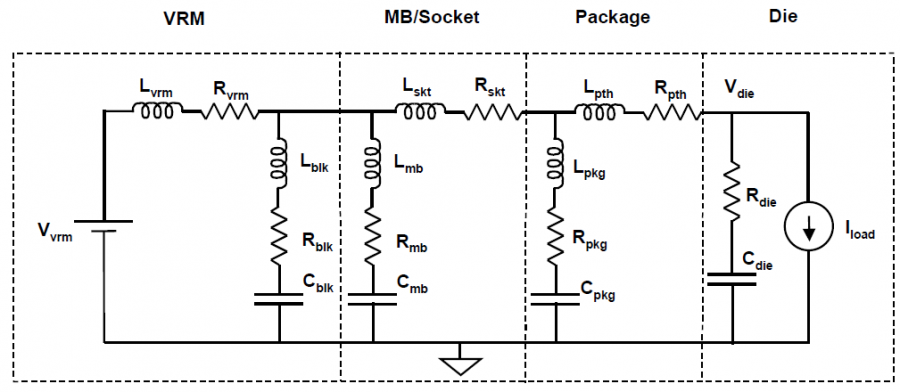
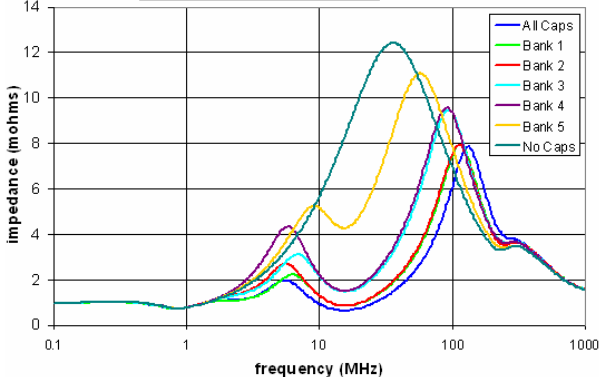
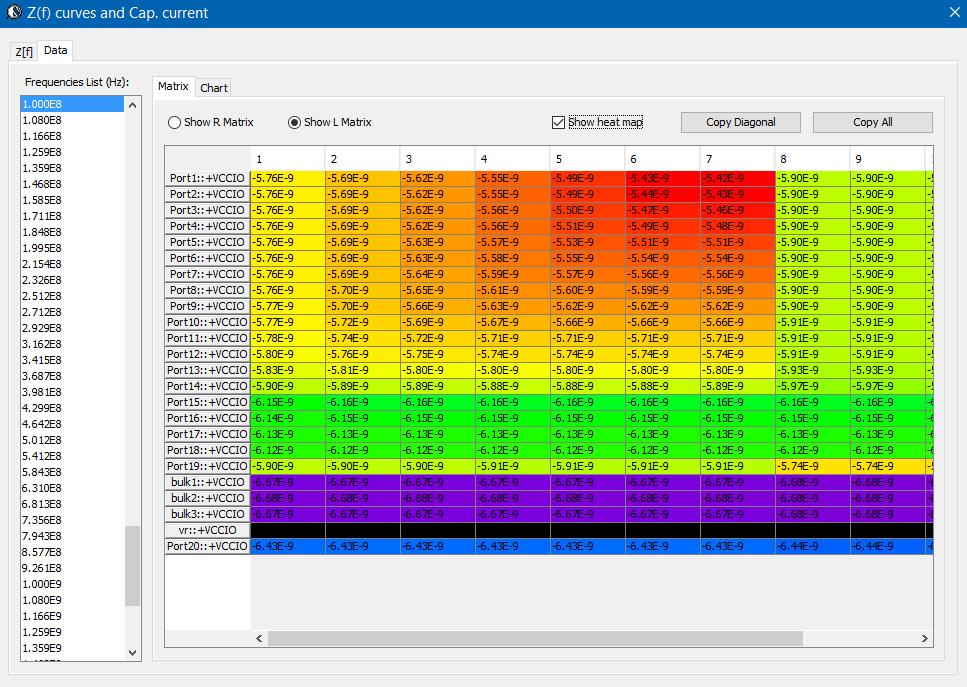
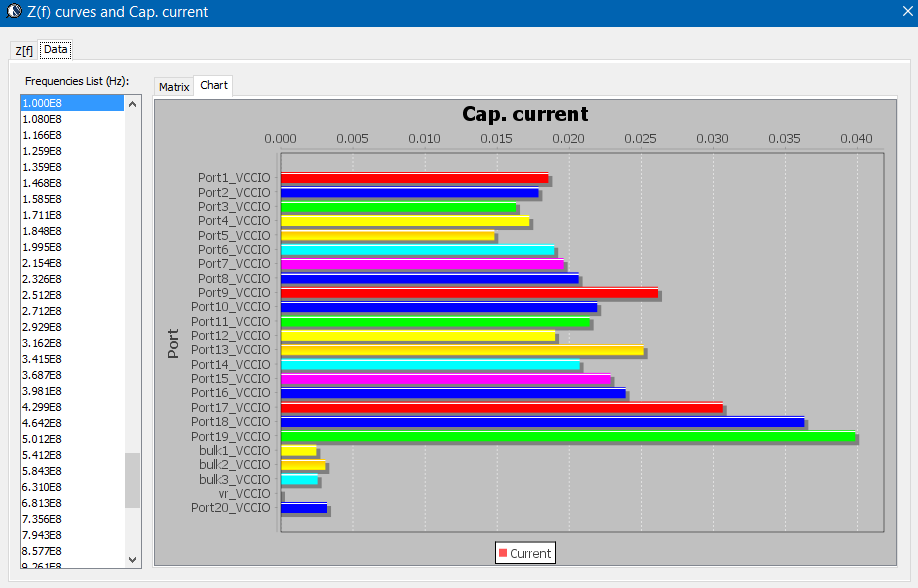
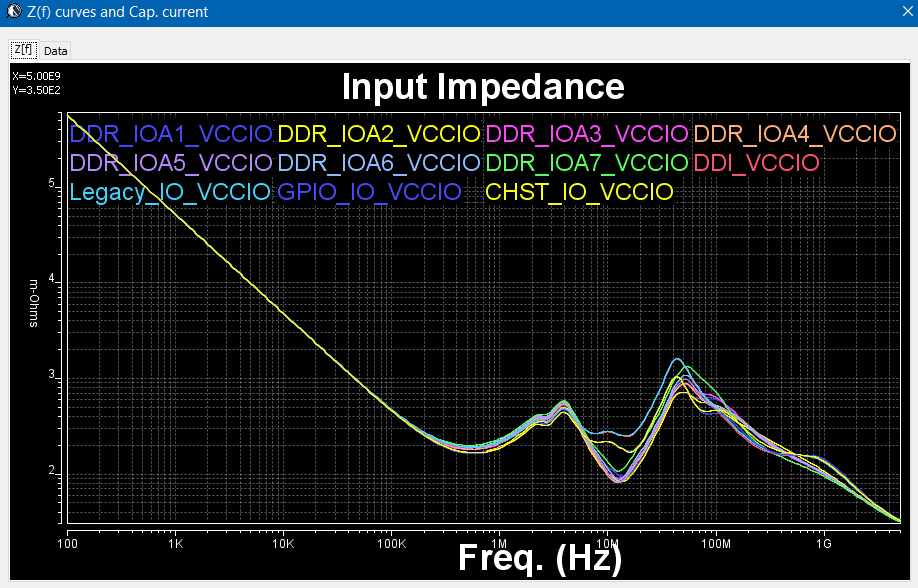
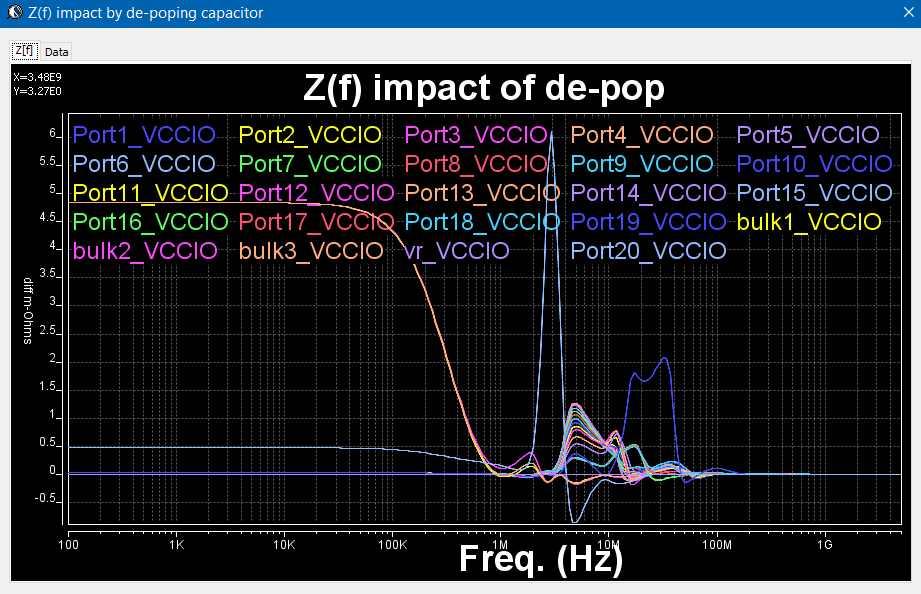
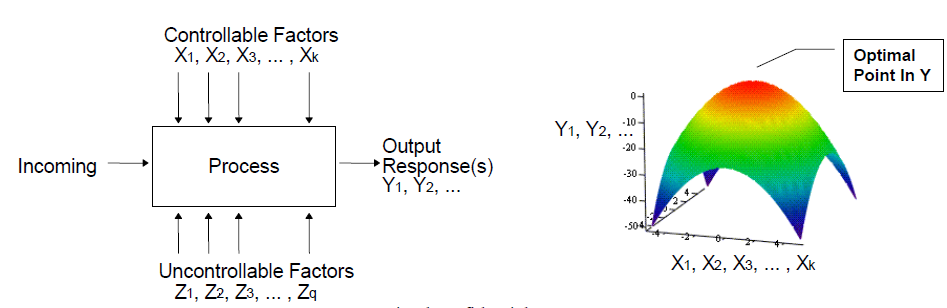

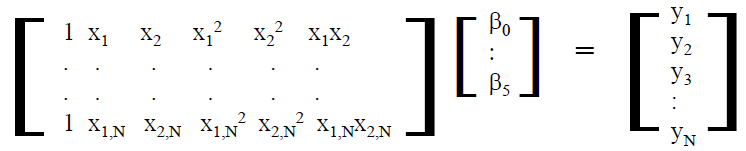
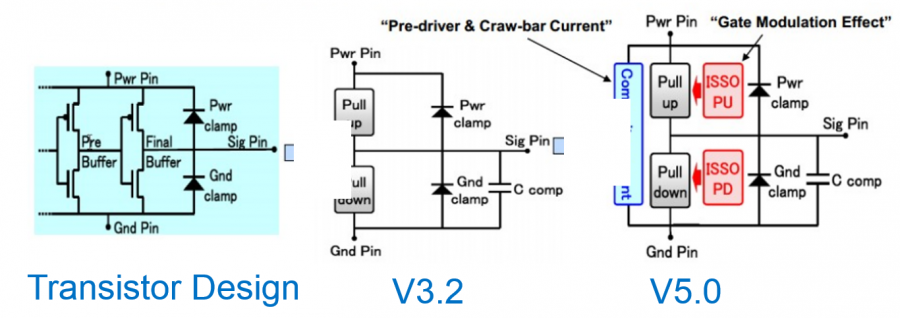
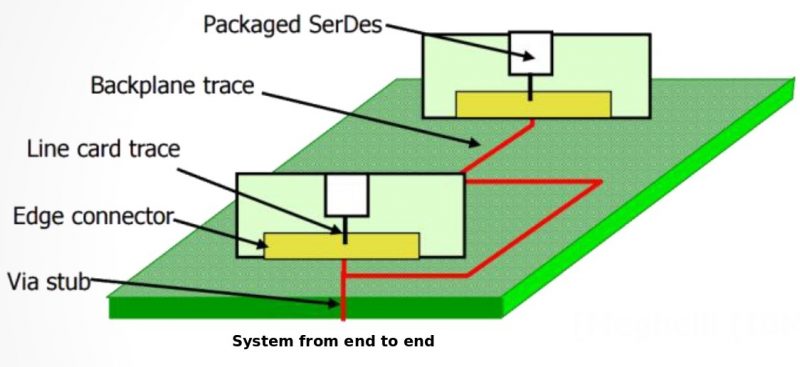 Sources of noise affecting performance:
Sources of noise affecting performance: